システムが大きくなり、要件が増え、ビジネスロジックが肥大化する。
数千行の処理が1つの関数に詰め込まれ、少しの修正を加えるだけで膨大な工数とデグレの嵐が巻き起こる。
誰しも経験したことはあるのではないでしょうか
プログラマをクソコードで殴り続けると死ぬ
こちらの記事には技術的連帯保証人というパワーワードが出ていました、言い得て妙だなと
糞コードは直すな。
注意:
- ここで述べている糞コードとは文法的にもっと可読性が良く、テスタブルに書ける可能性を秘めているコードではありません。(こちらは言語仕様勉強するのとリーダブルコードでも読んでください)
- 残念ながらすでに巨大な糞コードになったものをリファクタリングする技術についてではありません。
- 多分絶対的な正解はないと思います。
ビジネスロジックは足し算で共通化(条件分岐)すると死ぬ
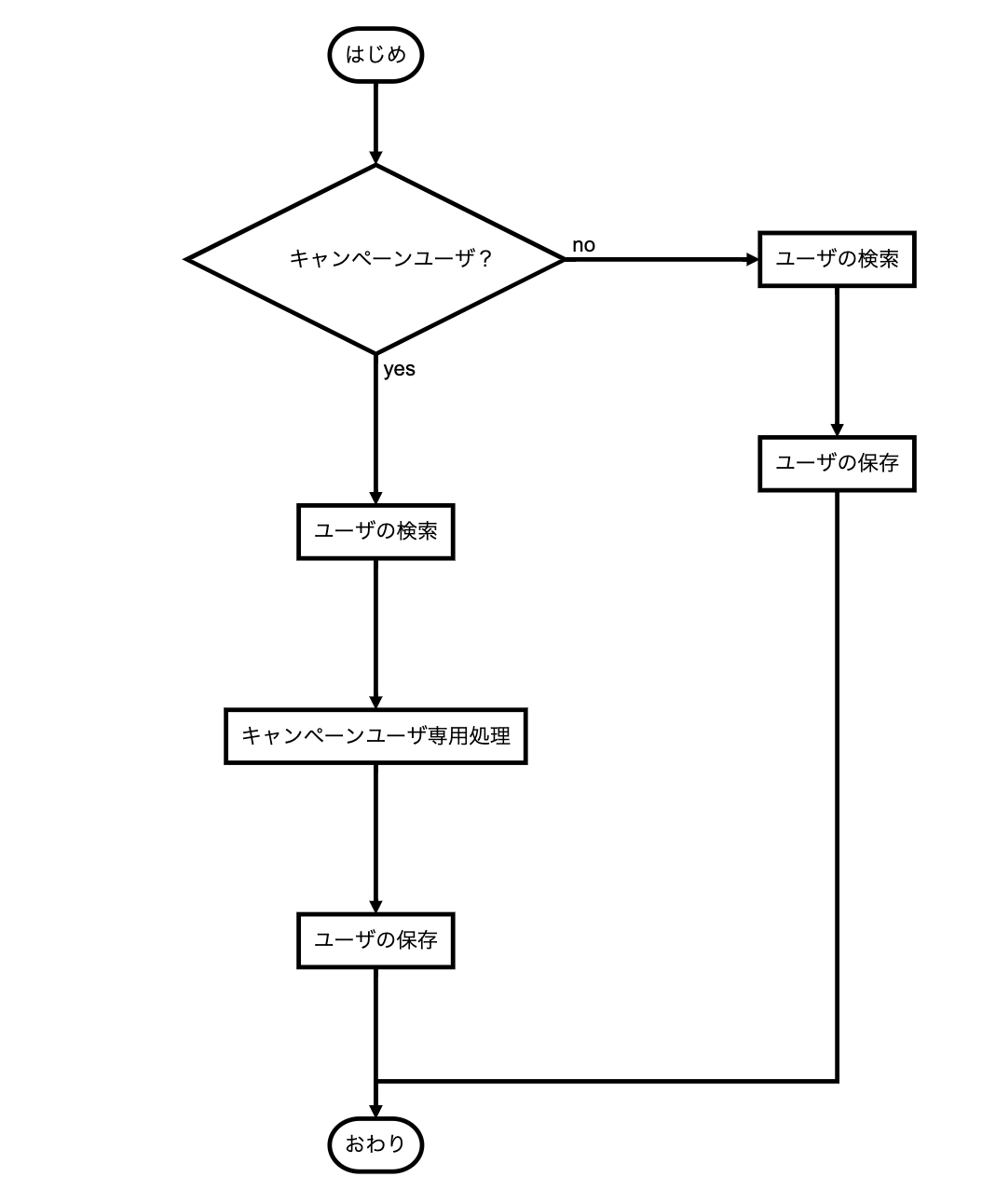
ユーザを更新するというupdate関数だとしましょう。

ここに何らかのキャンペーンを実施して特別なロイヤリティユーザを作成するという要件が加わるとします。
普通に対応すると現行のuserのupdate関数に条件分岐を埋め込む場合が多いのではないでしょうか?
最初は問題ないのかもしれませんが、これを素直に条件分岐を増やしていくといずれ死にます。

さらに期限切れの処理を実装しようとして同じ関数内に条件分岐が追加されるとします。

もう駄目ぽ(^p^)・・・
※あくまで一例です。駄目な長ったらしい関数にありがちなのが通常ユーザもキャンペーンユーザも対応するために条件文が入り混じったスパゲッティコードになります。
上位レイヤーを作り、ドメインで関数を分ける
さて根本的な問題は通常のユーザ更新と特別なユーザ更新が同じ関数に混在していることが原因だとわかります。

上位のレイヤーを設けることでドメイン単位で早々に処理を分離することができます。
この分け方はAPIレベルなのか、APIの最上位で関数を2つ作り分離するのかは状況とか好みが分かれると思います。
肝心なのはドメインが分かれた早期のタイミングでこの形に分離すると後々苦しまなくてすむかもしれません
多くの人はここでDRY(Don't Repeat Yourself)の原則を浮かべると思います。
ただしこの場合、要件が異なる以上、コピペコードではなく変更可能性を秘めたものになります。
2重メンテになるという考え方もあると思うのですが、
そもそも修正はドメイン単位で入るわけなので、適切にドメイン単位で分離できていれば
修正は片方で済む場合が多いです。(両方必要な場合ももちろんありますが)
また、ドメインで関数を分けた後に内部関数を共通化すれば問題ないはずです。
このやり方のもう一つのメリットとしては特別なユーザが不要になったタイミングで該当ドメインの関数ごと削除で済みます。
デッドコードが残り続けるという事態を減らしていくのが健全なプロダクトとして大事なことだと思います。
もちろんある程度上位のPMやPdMなどは常に施策をトラッキングしておき、インパクトが低い施策だとわかった際には積極的に該当ビジネスロジックを消していく(という組織文化を作るというのが大事だと思います)
リファクタリングは一気にやるな、死ぬぞ
負債の量が大きいほど修正にかかる時間は比例します。
(要は常日頃からできる限り良い実装とレビューしましょうということなんだけど)
負債が大きくなる前に返せるものは返していく、ライブラリのバージョンを上げることが大事です。
ライブラリのバージョンを上げることを恐れると後でサポートが切れたり、ドキュメントの参照が大変になったりと手痛いしっぺ返しを食らうことになるかもしれません。
また、ライブラリのバージョンを上げることによるBreaking Changeにも気を配る必要があります。
そのためにもテストを書くわけですが・・・
分けた関数の共通内部処理を関数化する
ビジネスロジック的に早々に変更が入らないだろうという箇所で共通化できる箇所はもちろん関数化すべしです。(主にビジネスロジックの分岐を除いた処理、複雑な判定条件は判定条件のみの関数を作っておくと良いです)
気をつけたいのは共通処理の関数は1関数に1機能以上持たせないということです。
1機能以上になるのだとしたら関数を分けましょう。
まとめると
- ビジネスロジックは本質的に汚い
- 安易な共通化(条件の継ぎ足し)は複雑度を増し、可読性を落とし修正工数を増やし、事故の要因となる
- まずドメインで関数を分ける、処理の共通化はその後
- ビジネスロジックのフロー処理をする関数と共通化する関数を分ける