PolityLink(ポリティリンク)は政治の「原文」へのポータルサイトです。
私たち国民が、政治に関する「正確」で「中立」な情報に簡単にアクセスできるように、
国会や行政機関の公式サイトに散らばった情報を、互いに関連付けてまとめ直しています。

PolityLink では、サービスが提供している情報をユーザーが自由に使えるように、 GraphQL と呼ばれる Web API の規格に則って公開しています。公開しているGraphQL エンドポイントの URL はこちらです。例えば特定の条件で法律案、委員会の議事録を絞りこんで取得し、その情報を元に統計解析に用いることができます。具体的な解析例については PolityLinkを活用した分析チュートリアル をご参照下さい。また、PolityLink に関わる開発者の思いは 政治のポータルサイトPolityLinkを作った話 をご参照下さい。
現状では、 GraphQL はまだ日本語での情報が少なく、どのように GraphQL サーバーを立てるべきかという知見が不足しているという側面があります。ここでは、なぜ GraphQL を PolityLink では採用したかという理由と、 GraphQL サーバーを運用するにあたって実装上の Tips をいくつか紹介します。
なぜ GraphQL を選んだのか?
Web API の必要性
PolityLink では、法律案、委員会議事録、議員といったさまざまな情報を整理して提供しています。このデータは動的に収集しており、必要な情報だけを取得できるようにするためには、データを整理して格納しておく必要があります。
このようにウェブ上において提供するデータのうち、動的に書き換えることがあり、またカスタムなクエリによって取得したいようなデータはデータベース管理システム (DBMS) の上に格納することが効率的であると考えられます。DBMS として、 MySQL や PostgreSQL といったオープンソースの実装が、リレーショナルデータベースの中では知られています。
ところで、ユーザーに蓄積した情報を使ってもらいたいと考えたときに、こうした DBMS のポートを公開し、SQL をユーザーが直接実行できるようにしたほうが便利でしょうか。
実際には、これにはいくつか問題があります。思いつくままに挙げてみますと、
- DBをそのまま公開してしまうと、DBに脆弱性があるときにすぐに弱点を突かれてしまうおそれがある。
- 後からデータベースのスキーマを変えると、今までアクセスしていたユーザーが困るので変えにくくなる。
- 任意のSQL文の実行を許してしまうと、計算が重いクエリを投げられて負荷がかかるおそれがある。
- ユーザーがアクセスできるリソースの制御をデータベース上で行う必要がある。
このような懸念があることが考えられます。こう考えると、単純にデータを公開するだけの目的であったとしても、外部からアクセスできるリソースを制限、整理して提供したほうが、何かと便利であると考えられます。このとき、Web API と呼ばれる、外部とデータをやりとりする窓口(実際にはウェブ上のエンドポイント)を介して、データをやりとりするような実装にすることが一般的です。
つまり Web API は、
- データを外部のエンジニアやサービスに自由に使ってもらう場合
- Webサービスのバックエンドとフロントエンドを独立に実装する必要がある場合
に実装する必要があります。このとき Web API 開発者は、ユーザーからアクセスして良い情報だけを、ユーザーがアクセスしやすいように提供できる Web API を設計したいと考えられます。そのために前もって、どこにアクセスすると何が入手できるかを定義しておく必要があります。ここからは2のケース、つまりフロントエンドで呼び出したいようなWeb API をどのように設計するかについて、議論します。
REST API の問題点
PolityLink では、まずフロントエンドとバックエンドを疎結合にするという実装方針としました。この理由としては、これは PolityLink に限った話ではありませんが、近年のフロントエンド技術の急速な発展に伴い、フロントエンドとバックエンドを独立に実装することで得られる自由度が、密結合で連携して実装するのに比べて高い、というのが挙げられます。(ここではその具体的な説明は措きます。)
また、 PolityLink がサービスの柱として掲げているものの1つに、集約したデータをユーザーが自由に利用できるようにするというのがあります。そのためには、蓄積されているデータはデータとして利用できる Web API を公開しつつ、 PolityLink サービス自体がその Web API の利用例であるという仕組みのほうが、 Web API をドッグフーディングしつつ改良できるという利点があると考えたためです。
フロントエンドとバックエンドを別々に実装するアプリケーションでは、フロントエンドとバックエンドの間のデータのインターフェースは、 REST API と呼ばれる規格で実装することが、現状では広く使われる方法です。
ここで、PolityLink が現在どのようなサービスを提供しているかをみてみましょう。PolityLink の 会議録ページ では、会議録情報だけでなく、そこで審議された法律案情報、あるいは発言者の議員情報、委員会情報、ニュース情報も同時に掲載されています。一方で委員会ページ には会議録情報が、法律案ページ にも同様に会議録情報が掲載されています。こうすることによって、ユーザーは政治の情報に対して様々な切り口から見ることができるようになります。
さらに、 PolityLink のイチオシの機能として、タイムラインページ というページがあります。
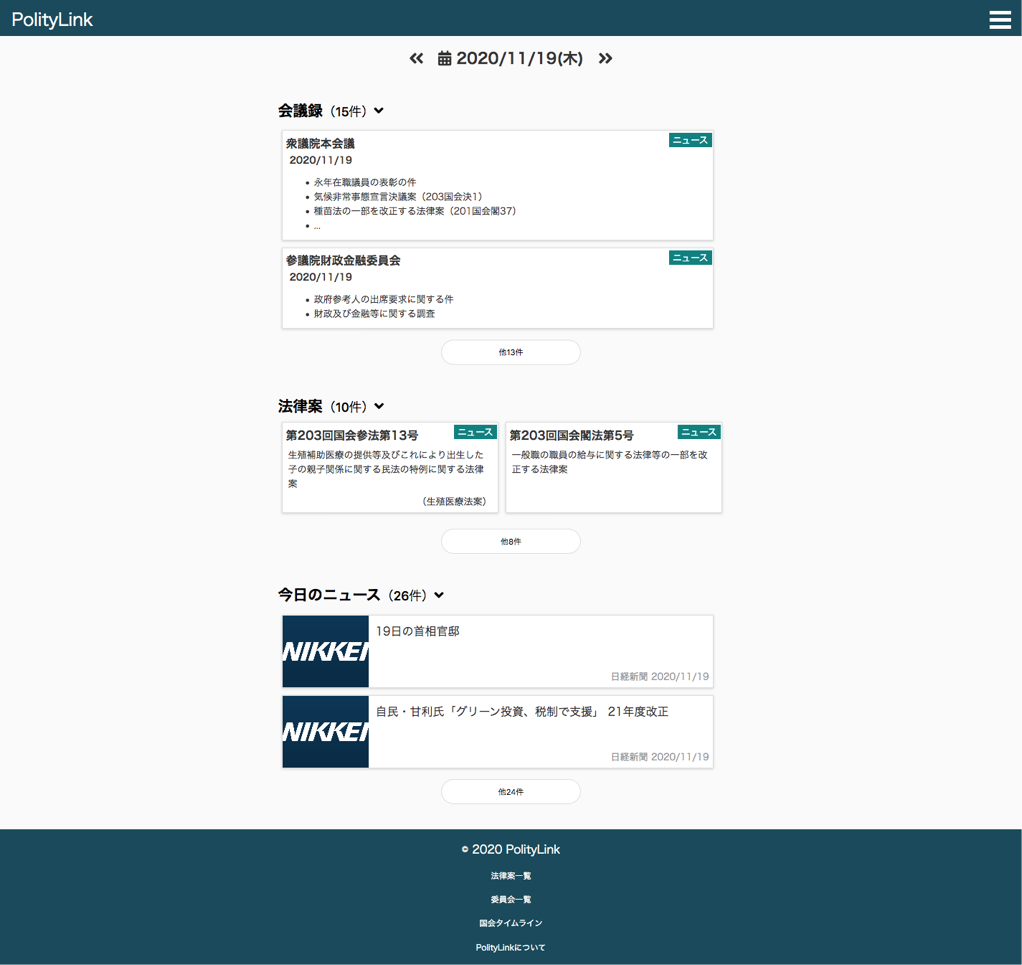
上記のページでは、会議録・法律案といった様々なリソースの情報を1つのページとして集約しています。実装したいページと、バックエンドのデータベースで管理されるリソースの関係性を、二部グラフで整理するとこのようになるでしょう。
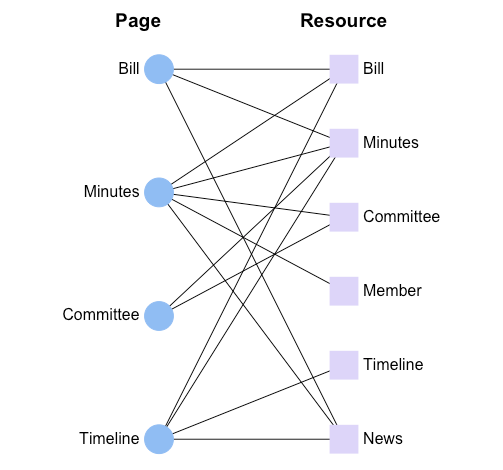
このように、バックエンドのデータベースでは異なるモデルとして定義される会議録や法律案、議員といった情報を、フロントエンドの様々なページで取捨選択し、異種データを統合して表示しているのが PolityLink ですので、このようなサイトを構成できるような Web API を実装するという要件を開発時に定義しました。
このとき、どのようにバックエンドの Web API を実装する方法があるでしょうか。REST API として定義する場合、大きく分けて2つの方法が考えられるかと思います。
- 会議録や法律案をそれぞれ独立したエンドポイントで実装し、フロントエンドからは個別に呼び出すようになる
- (+) 簡潔なエンドポイント
- (-) 一つのページを作るのに複数回エンドポイントを叩く必要がある
- (-) フロントエンドのページには直接必要ない情報も返り値に含まれてしまいがち
- (+) リソースに新たに情報を追加するには一つのエンドポイントを拡張するだけで良い
- それぞれのフロントエンドページごとに、専用のエンドポイントを作成する
- (-) 複雑なエンドポイント
- (+) 一つのページを作るのに一度のリクエストですむ
- (+) 予めリソースを定義しておくので、過不足なくデータを取得できる
- (-) リソースに新たに情報を追加するには関連する全てのエンドポイントを拡張する必要がある
メリット、デメリットをそれぞれ (+) 、 (-) で記載しました。REST API で実装すると、よほどうまく実装しない限りは上記のように、実装上のデメリットが発生してしまうと言えます。
このことの根本的な原因としては、 REST API 自体には、別に実装上の指針があるわけではなく、バックエンドエンジニアが好みに基づいて実装することが多いということと、REST API は、リソースごとにエンドポイントを分けるというのがベストプラクティスであるのに対して、フロントエンドが複雑化してきた現代においてはリソース横断的に単一のフロントエンドを構成したり、またユーザーが複数のリソースを横断的に情報を取得したいことが増えてきたため、従来の REST API の枠組みでは対応しづらいような状況が発生してきたと考えられます。
GraphQL の登場
そこで、この問題に対する解決策として提案されているのが、 GraphQL という仕様です。 GraphQL の日本語資料として、 RedHat の提供する説明 が簡潔にまとまっています。
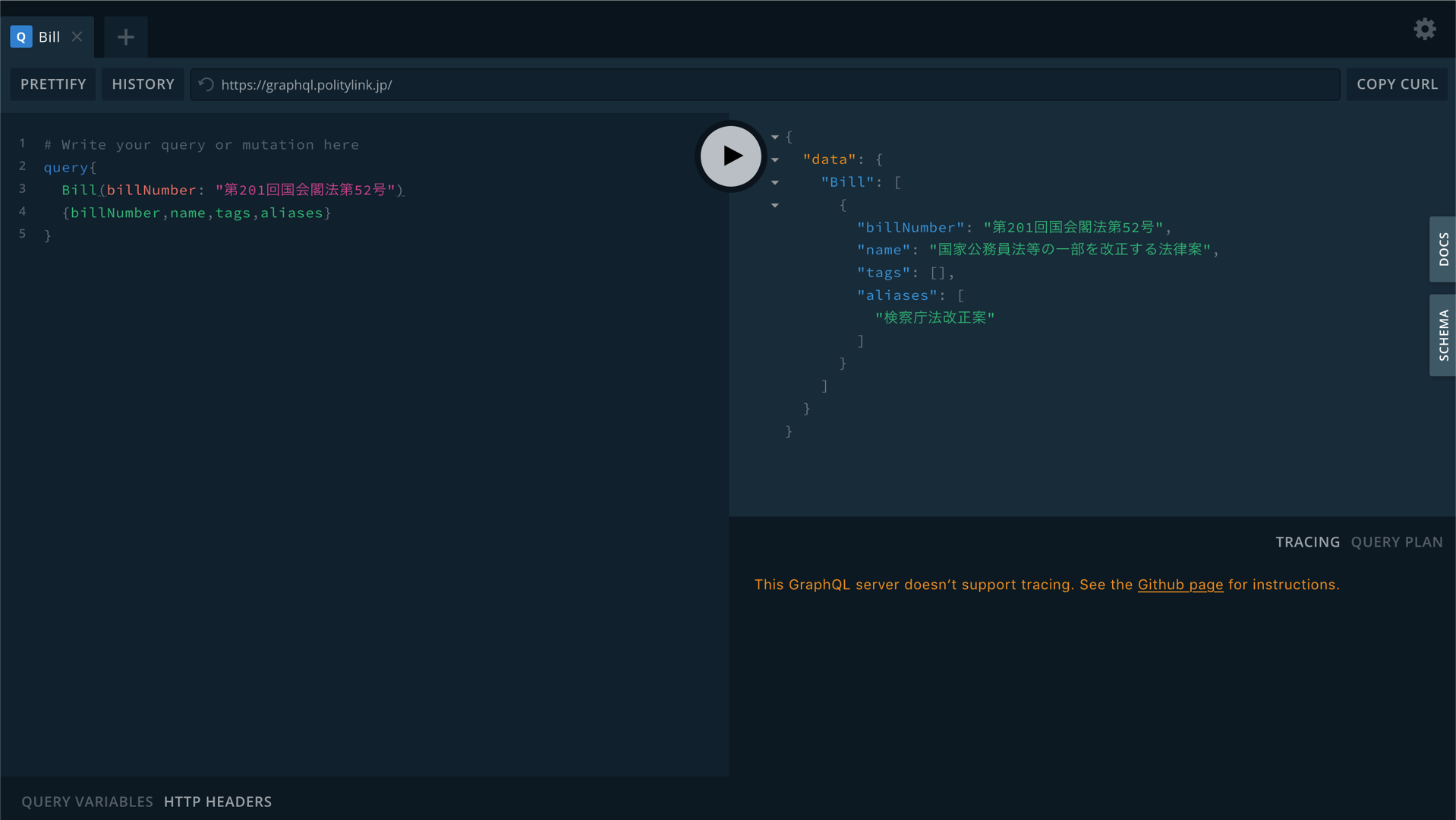
PolityLink では、実際のクエリの実行をGraphQL Playground で試すことができます。
GraphQL では、クライアントが必要なリソースを要求すると、それが JSON 形式で返ってくる単一のエンドポイントを提供するという点で、クライアント側からみるとシンプルな Web API になっています。クライアント側からすると、常に同じエンドポイントにクエリを発行すると、そのクエリに対応した JSON が返ってくるため、戻り値を予測するのがかなり容易になります。これが、フロントエンド側でデータ形式を変換するといった手間を省き、フロントエンドエンジニアの負担を減らすことにつながります。
予めスキーマを定義しておくと、そのスキーマに基づいてトップダウンでエンドポイントの入出力が一意に定まるという性質、またリクエストに必要なオブジェクト・フィールドを定義すると、その情報だけを選択的に得ることができるという性質が、PolityLink の Web API を提供する上で役に立つと考えました。例えば、タイムラインページを GraphQL で実装する場合は、先ほど述べた REST API によるデメリットが GraphQL フレームワークの中で回収されるため、以下のようになります。
- GraphQL で実装する場合
- (+) 簡潔なエンドポイント
- (+) 一つのページを作るのに一度のリクエストですむ
- (+) 要求したフィールドだけ返り値に含まれるため、過不足なくデータを取得できる
- (+) リソースに新たに情報を追加するにはそのリソースのschemaを変更するだけで良い
実際に上述のタイムラインページでは、1つの GraphQL Query によってこのページを構成するのに必要な全ての情報を 単一の GraphQL エンドポイントから取得しており、またスキーマの変更も即座にドキュメントに反映されるため、そのドキュメントをみながらクエリを書き直すことが容易にできるようになっています。
先ほどのものとあわせて、それぞれの設計における実装の長所と短所を整理してみましょう。
| 星取り表 | リソースごとのREST API | ページごとのREST API | GraphQL |
|---|---|---|---|
| エンドポイントの複雑さ | + | - | + |
| 1つのページを作る時のリクエストの回数 | - | + | + |
| 必要なフィールドだけレスポンスに含まれるか? | - | + | + |
| スキーマ変更の容易性 | + | - | + |
GraphQL に肩入れしているかもしれませんが、サービスの規模が大きくなり、APIに触れるエンジニアが増えれば増えるほど、規格化された Web API としての GraphQL の利点が出てくるのではないかと考え、 PolityLink では GraphQL を選択することにしました。
GraphQL クエリの実例
GraphQL では、以下のような2種類のクエリを実行できます。このうちPolityLink では、 query のみを一般ユーザーが利用可能な形で公開しています。
- query: 読み出すためのクエリ (SQLにおける Select に対応する)
- mutation: 書き換えるためのクエリ (SQLにおける Update / Insert / Delete に対応する)
フロントエンドエンジニアは、SQL文を書かなくても、「どのオブジェクト(SQLでいうテーブルに相当する)の、どのフィールドが必要か」ということを HTTP リクエストによって要求すると、そのオブジェクトとフィールドだけを取得することができます。例えば、2020年1月20日に提出された3つの法律案の名前をリクエストするためのクエリは以下です。
query {
Bill(filter: {submittedDate: {year: 2020, month: 1, day: 20}}) {
name
}
}
結果は、このように JSON フォーマットで得ることができます。
{'data': {'Bill': [{'name': '特定複合観光施設区域の整備の推進に関する法律及び特定複合観光施設区域整備法を廃止する法律案'},
{'name': '地方交付税法及び特別会計に関する法律の一部を改正する法律案'},
{'name': '平成三十年度歳入歳出の決算上の剰余金の処理の特例に関する法律案'}]}}
ここで注目すべきは、戻ってくる JSON フォーマットの構造は、クエリで投げたものそのままになっていることです。data keyの中には Bill オブジェクトがあり、その中身は name を key とするオブジェクトの配列となっていますが、それはクエリで、 Bill について、それぞれの name を返すようにリクエストしたから、指定した条件の Bill の、 name フィールドのみを配列として返ってきているのだ、と考えることができます。
参考までに、先ほどの Timeline ページは、以下のクエリを発行しています。
query($timelineId: ID!){
politylink {
Timeline(filter:{id:$timelineId}){
date {year, month, day}
totalBills
totalMinutes
totalNews
bills {
id
name
billNumber
isPassed
aliases
totalNews
submittedDate {formatted}
}
minutes {
id
name
topics
totalNews
startDateTime {year, month, day, formatted}
}
news {
title
url
isPaid
publisher
thumbnail
publishedAt {year, month, day, formatted}
}
}
}
}
このように、複数のオブジェクトにまたがる、ネストした情報をリクエストすることができます。戻り値が階層化されたJSON であることが JavaScript で記述されるモダンなフロントエンドとの親和性が高いといえるでしょう。
GraphQL スキーマはどう管理するのか?
では次に、このようなクエリを実現するためのスキーマについて考えてみましょう。
今の説明では、フロントエンドやクライアント側が便利になる一方で、このようなバックエンドを実装する手間が必要になると考えられます。なぜならば、バックエンドデータベースよりも、 Web API 側の制約が強い実装となるため、バックエンドデータベースからのデータのマッピングの手間が増えると考えられるためです。このことを考えると、フロントエンドやクライアント側の負担がバックエンドエンジニアに転嫁されてしまうだけなのではないか、という懸念が生じると思います。
しかし、一からこうした Web API を設計するとしたときに、 GraphQL のデータ構造(すなわちスキーマ)が決まっているならば、それにあわせたデータベースを自動で構成することが可能なのではないかと考えられます。実際にこれを実現したものが、次に紹介する GRANDstack の基本的なアイディアとなります。
GRANDstack の登場
GRANDstack は、バックエンドのデータベースとしてグラフデータベースである Neo4j を採用して、 GraphQL サーバーをスキーマから自動構築してくれるボイラープレートを提供するライブラリです。

GRANDstack には、上図にあるように4つのシステムが組み込まれています。
- GraphQL: Web API のモデルとして GraphQL を利用している。
- React フロントエンド: GRANDstack の上にフロントエンドを実装したい場合に用いる。
- Apollo: GraphQL サーバーの nodejs 実装。
- Neo4j Database: GraphQL のバックエンドが格納されている。
PolityLinkでは、 この中の GraphQL、 Apollo、 Neo4j Database を利用しています。現状では、 PolityLink のフロントエンドは、 Gatsby と呼ばれるサイトジェネレータを利用して静的な HTML として生成しているので、 React フロントエンドは GRANDstack と別立てで利用しています。
バックエンドエンジニアは、フロントエンドエンジニアと協力して、責任分界点として We bAPI の仕様を定義します。 GraphQL の世界では、スキーマがそれに対応します。PolityLink におけるスキーマは、 GitHubのリポジトリ で管理しているので、そちらを参照するとどのようなクエリが実行できるかをみることができます。
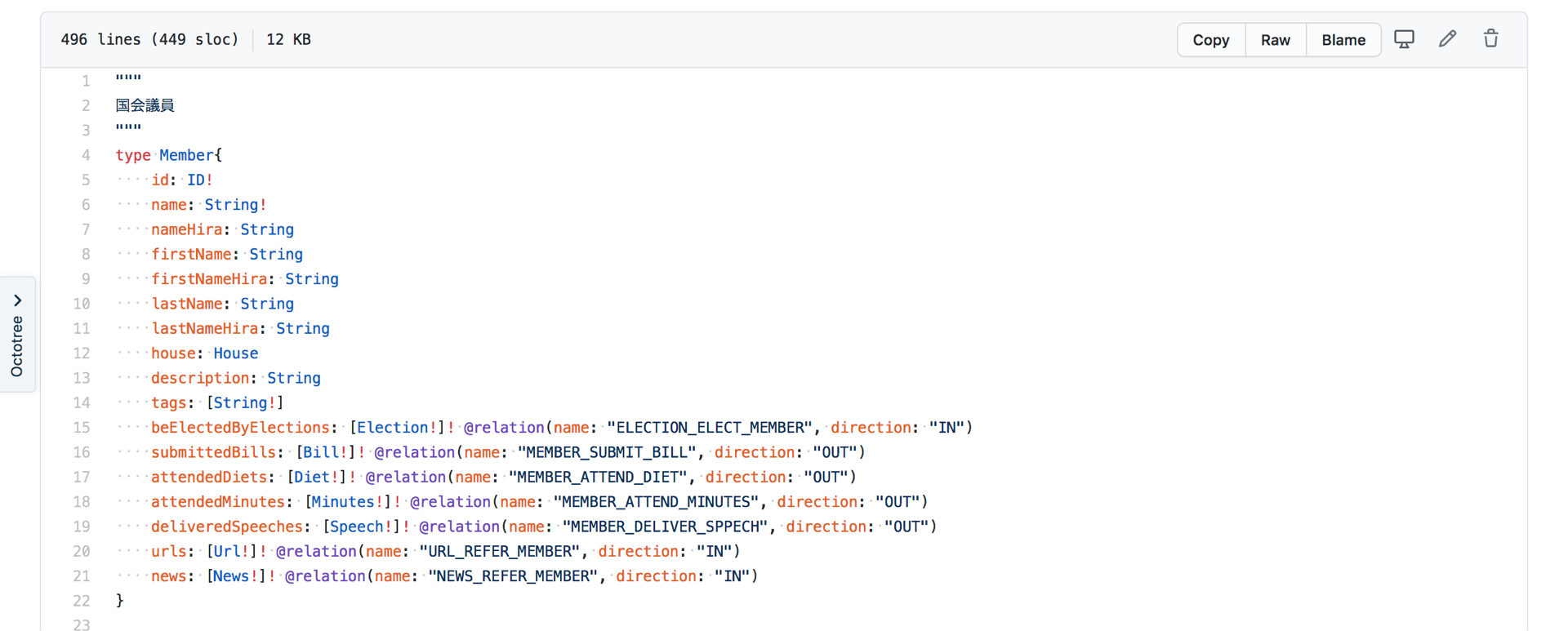
これを schema.graphql として定義すると、この GraphQL スキーマにあうように、Neo4j データベースのノード・エッジ構造との関連づけを自動で行ってくれるのが、GRANDstack の利点です。バックエンドでは Neo4j がデータベースとして動作していますが、明示的に Neo4j Cypher クエリを定義する必要はありません。従って、理想的にはノーコードで GraphQL API ができるはずです。
実装は、クエリのインターフェースは GraphQL で定義していますが、そのバックエンドとしてはグラフデータベースである Neo4j が動いています。データの追加・削除は GraphQL の mutation を介して行っており、 Neo4j を外部から直接触ることはありません。
ここで注意すべき点として、 GraphQL は必ずしもバックエンドがグラフデータベースであるという必要はないというところです。 一般に、 Web API を作る場合には、様々な選択肢があります。
- データベースの選択肢: RDBMS, NoSQL, Graph Database, NewSQL ……
- Web API 設計の選択肢: REST, GraphQL, ……
このなかで、 GRANDstack は Neo4j + GraphQL という組合せを選択してボイラープレートを提供しているものだ、というように考えることができます。
PolityLink で必要となった GRANDstack への拡張
さきほど、理想的にはノーコードで GrahpQL API を提供出来ると書きましたが、実際に PolityLink で用いる際には、いくつか拡張する必要がありました。ここでは、その内容を紹介します。
GRANDstack では、 単純な参照系操作、あるいは CRUD な操作に対しては自動的にスキーマが定義されます。自動生成される定義については、GraphQL Schema Generation And Augmentation をご参照下さい。
しかしながら、そのカテゴリに何件の要素が含まれているかということを問い合わせたいことがあります。その場合、そのような値を返す GraphQL のフィールドを、スキーマ定義ファイルである graphql.js に記述する必要があります。 GRANDstack では、バックエンドのデータベースとして Neo4j を採用しているので、この場合では Neo4j のクエリ言語である Cypher を用いて、クエリを記述する必要があります。
集計のカスタムクエリを提供する
例えば PolityLink では、それぞれの議員に対して、何件の委員会に出席しているか、何件のアクティビティ(ここでは発言履歴)があるかという情報を、議員詳細ページに記載しています。それを計算するのは、もともとの機能では提供されていなかったので、 schema.graphql に、以下のように定義しています。
"""
国会議員
"""
type Member{
id: ID!
/* 中略 */
totalMinutes: Int! @cypher(
statement: """MATCH (this)-[]-(n:Minutes)
WITH COUNT(n) AS count
RETURN count""")
totalActivities: Int! @cypher(
statement: """MATCH (this)-[]-(n:Activity)
WITH COUNT(n) AS count
RETURN count""")
}
このように、 statement にディレクティブとして cypher クエリを書くことで、クエリを実行する際に自動的にその cypher クエリが実行され、実行結果は GraphQL のフィールドに統合されて取得することができます。
Neo4j の cypher クエリと異なる点として、現在選択しているノードを this として記述する必要があります。
削除のカスタムクエリを提供する
これは PolityLink 内部のみで開発用に利用しているため、外部のユーザーは利用できない機能ですが、リソースに属するすべての要素を削除するクエリがなかったので、このように定義しました。
type Mutation {
DeleteAllMembers: [ID!]! @cypher(
statement: """
MATCH (n:Member)
WITH n, n.id AS id
DETACH DELETE n
RETURN id
"""
)
DeleteAllElections: [ID!]! @cypher(
statement: """
MATCH (n:Election)
WITH n, n.id AS id
DETACH DELETE n
RETURN id
"""
)
}
schema{
query: Query
mutation: Mutation
}
リソースにフィールドを追加するようなクエリは、 type で定義されるフィールドに追記する形になりますが、このように新しい query や mutation を追加するような場合は、 Mutation という type を作り、そこにクエリを記述します。今回の場合は、更新系のクエリであるため、 mutation のメソッドとして Delete を定義しました。
IDがユニークになるように制約をつける
PolityLink では、既に登録されているオブジェクトのフィールドを更新することがあります。 GraphQL を介してデータを更新する際には、 SQL における Update に対応するものは、 GraphQL において Merge とよばれる mutation クエリになります。ところで、 GRANDstack で Merge mutation を実行すると、もしオブジェクトの内容が書き換えの前後で変更される場合に、新しいオブジェクトが複製されてしまうという挙動がみられます。なぜ更新ではなく複製になってしまうかというと、Merge する前の要素と、今 Merge しようとしている要素が同一であるかどうかを、このままでは判断できないためです。
これを防ぐために、バックエンドのデータベースである Neo4j 上で、 id にユニーク制約をかけています。ここでは id が同じオブジェクトの種類のあいだではユニークになるように指定することで、同じ id の要素を Merge する場合には、上書きして保存されるようになります。これを実現するために、 GRANDstack の起動時に常にこのデータベース初期化命令が実行されるようにしています。
実装の詳細は、以下の通りです。
export const initializeDatabase = (driver) => {
const resources = ["Member", "Election", "Diet", "Law", "Bill", "Committee", "Minutes", "Url", "Timeline", "News"]
const initCypher = resources.map(key => `CREATE CONSTRAINT ON (n:${key}) ASSERT n.id IS UNIQUE`)
const executeQuery = (driver, cypher) => {
const session = driver.session()
return session
.writeTransaction((tx) => tx.run(cypher))
.then()
.finally(() => session.close())
}
initCypher.forEach(cypher =>
executeQuery(driver, cypher).catch((error) => {
console.error('Database initialization failed to complete\n', error.message)
})
)
}
これも、この機能を実現するためには Neo4j の知識が必要となる例でした。このように、GRANDstack を利用する上ではバックエンドデータベースの構造を知らないと修正が難しい箇所もあります。
まとめ
- GraphQL: ユーザーが便利に使える Web API の新しい規格であり、異種データを組み合わせたフロントエンドページの実装に効果的。
- GRANDstack: Neo4j で GraphQL APIを立てるスターターキット
- GraphQL をみんなが使いこなせれば、今後需要が高まると考えられます。
- ただし Neo4j の Cypher クエリを書く必要があるなど、工夫をしなければならないところもあります。
- PolityLink は攻めた技術選択をすることで、 GovTech / CivicTech にイノベーションを巻き起こしていきます!!
- PolityLink の提供する GraphQL エンドポイント は、データ解析やGraphQLの練習等の目的で自由にご利用いただけます。