はじめに
昨年末からシーバス釣りにはまり、割と情報の収集と分析が必要なゲームと気づきました。
せっかくIT関係のSEなのでスマートに情報を収集・分析して釣果をあげたいと思いました。
ついでにDXにもはまり中なのでそのお勉強も兼ねます。

情報の収集
使うツールは以下。
- IFTTT(イフト)
- Googleスプレッドシート
まずはTwitter上で**「シーバス釣り」**を検索キーワードとしてIFTTTで収集し、Googleスプレッドシートに落とし込みます。このあたりはGUIですべて完結するので簡単です。
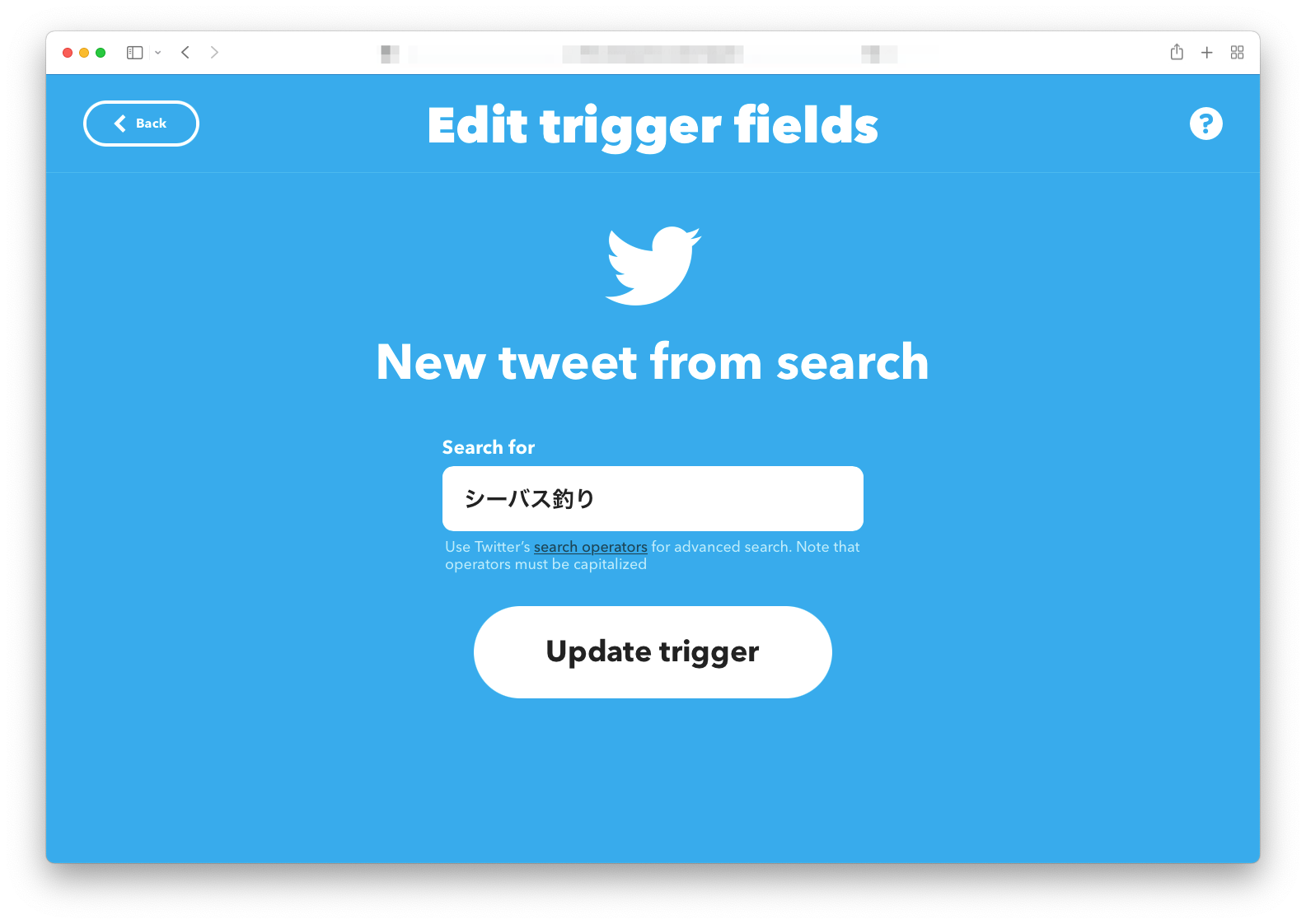
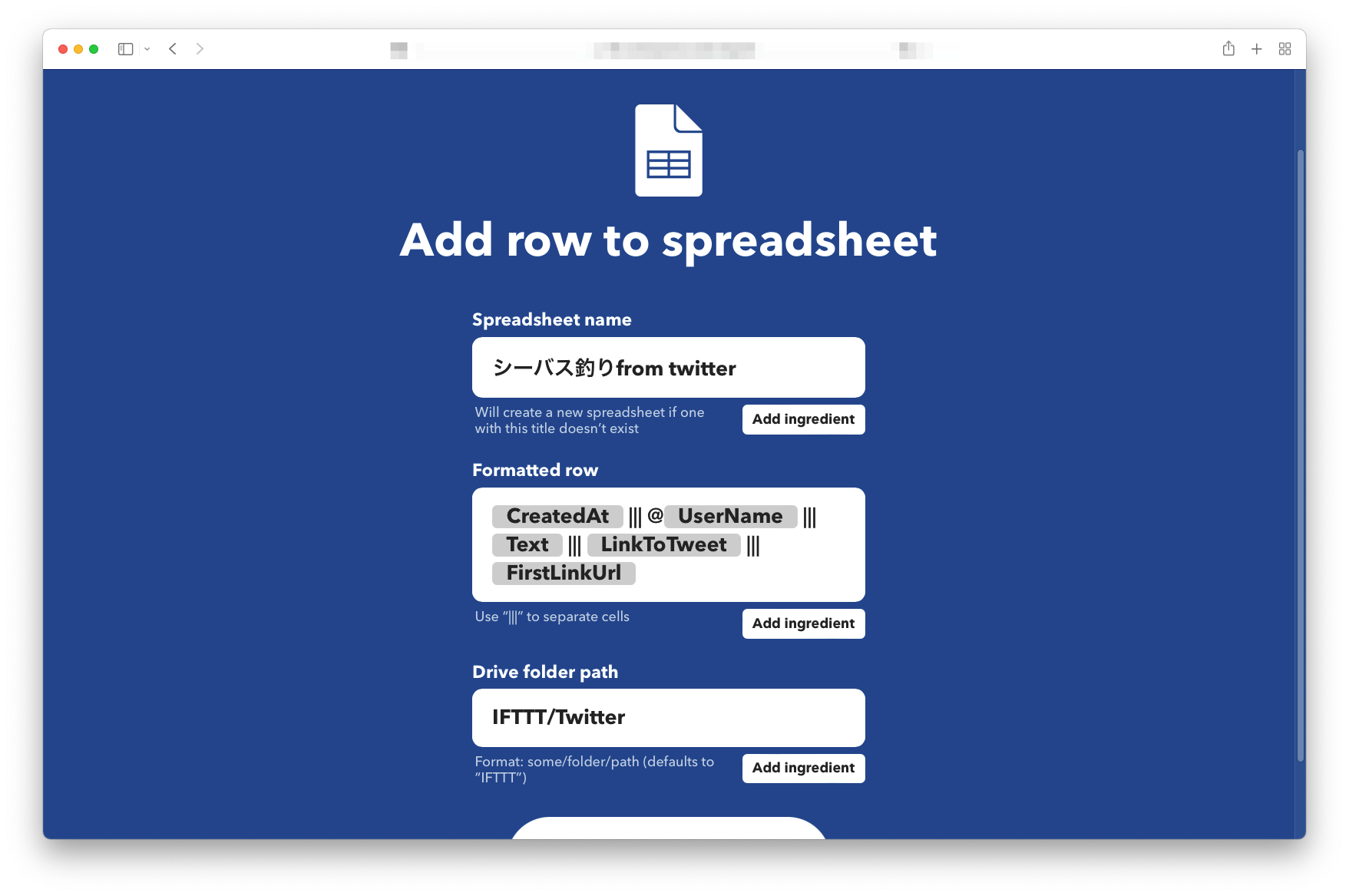
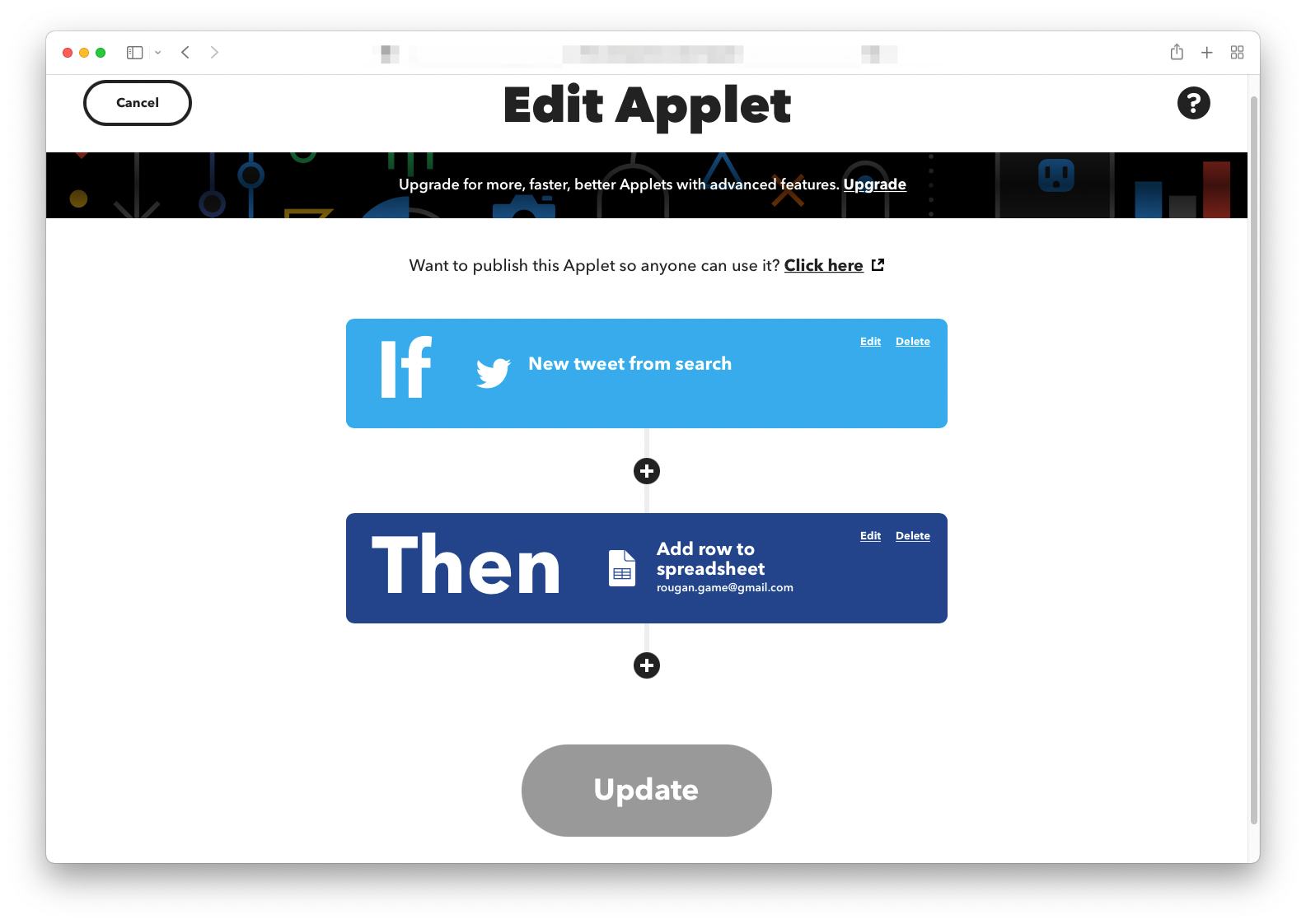
結果としてGoogleスプレッドシートにツイートされた内容が保存されます。
情報の分析
シーバス釣りはルアーのチョイスが重要です。ですが、安い買い物でもないので慎重に購入を検討する必要があります。今回は今の時期よく呟かれてるルアーの集計をしてみます。
単純な単語の抜き出しだけなので、「釣れたルアー」という分析ではなく単に話題にあがっているという分析になります。(釣れたルアー分析はまた別途)
使うツールは以下
- Janome
- Colaboratory
Janomeは形態素解析エンジンで日本語をきれいに分解してくれます。
Janomeで呟きを「単語に分解」し「名詞」だけ抽出してみます。
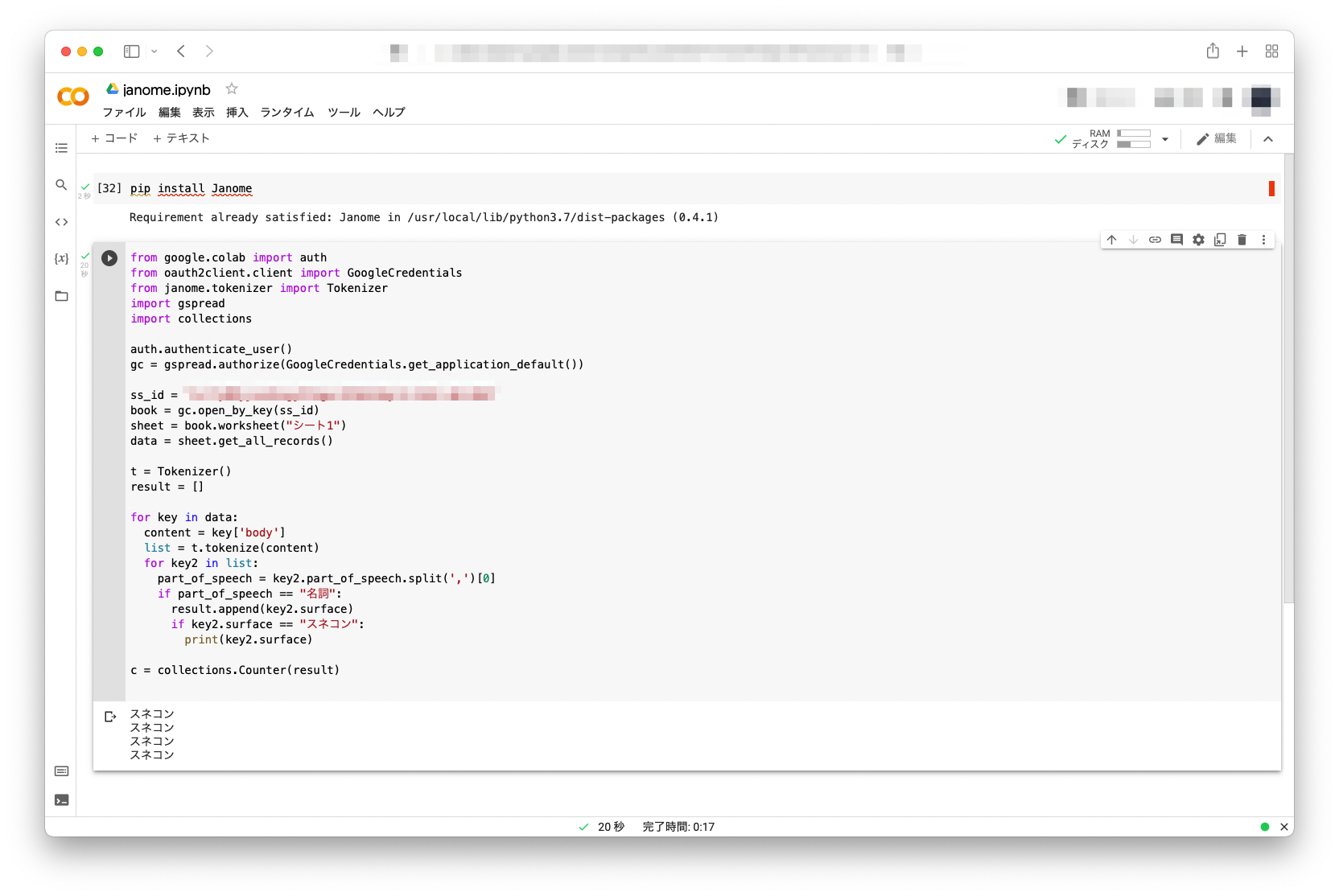
スプレッドシートを読み込み、呟きをJanomeに食わせて名詞だけ抜き出すというシンプルなコードです。
(コードや変数名は美しくありません!)
from google.colab import auth
from oauth2client.client import GoogleCredentials
from janome.tokenizer import Tokenizer
import gspread
import collections
auth.authenticate_user()
gc = gspread.authorize(GoogleCredentials.get_application_default())
ss_id = "****"
book = gc.open_by_key(ss_id)
sheet = book.worksheet("シート1")
data = sheet.get_all_records()
t = Tokenizer()
result = []
for key in data:
content = key['body']
list = t.tokenize(content)
for key2 in list:
part_of_speech = key2.part_of_speech.split(',')[0]
if part_of_speech == "名詞":
result.append(key2.surface)
if key2.surface == "スネコン":
print(key2.surface)
c = collections.Counter(result)
print(c.items())
試しにスネコンが抽出できてるかハードコーディングで出力してます。
結果は以下の通り。無事にルアーの名称も単語として抽出できています。
(2000件のうち4件呟かれていたようです)
ひとまずここまでデータが抜き出せたら、あとはスプレッドシートに落とし込むなりし、見やすいデータに加工するだけです。
次回以降
このデータではルアーを買ったか、釣れたのかよく分からないデータなので、なんとかして釣果につながる分析をしてみたいと思います。