概要
こんにちは。この記事は ZOZO Advent Calendar 2024 シリーズ5、16日目の記事です。
※内容が増えすぎたため、2回に分けて投稿します。後半の記事は以下です!
先日、ラスベガスで開催されたAWS re:Invent 2024にて、マルチリージョンの分散データベース「Amazon Aurora DSQL」が発表されました。
re:Inventには現地参加し、以下のセッションを受けたので個人的な参加レポートも兼ねてまとめたいと思います。
- DAT424 | Get started with Amazon Aurora DSQL
- DAT427 | Deep dive into Amazon Aurora DSQL and its architecture
- DAT421 | Build a multi-Region, active-active rewards app with Amazon Aurora DSQL
私はPostgreSQLにも、既存のNewSQL・分散データベースも詳しくないため、関連用語を整理するところから始めてみようと思います。(内容に不備あればぜひコメントください)
Aurora DSQLに関する具体的なアーキテクチャやアプリケーション実装例は後編でまとめます。
Aurora DSQLの特徴
まず、用語ありきでDSQLの特徴をまとめます。
- 互換性
- PostgreSQL16 互換
- 完全互換ではなく非対応の機能や制約も多く存在
- FK制約が使えない
- CREATE INDEXなど一部制約あり
- ビュー、一時テーブルなども使えない、など
- PostgreSQLのCLIやドライバーで接続可能
- 可用性
- マルチリージョンなActive/Active構成
- シングルリージョン構成でも構築可能
- マルチリージョン構成の場合は2リージョン+監視(Witness)リージョンの計3リージョン必要
- 1リージョンは3AZ分散
- 整合性
- 強い整合性とレイテンシを両立
- 分散トランザクションをサポート
- Amazon Time Sync Serviceによりms単位の時刻同期を実現
- 低レイテンシな分散合意アルゴリズム
- 線形可能性を満たす
- 分散トランザクションをサポート
- 書き込みはOCC(楽観的排他制御)
- 基本的にロックを取らずコミット時に競合していた場合にアボートされる
- アプリケーション側でリトライ処理が必要
- 読み取りはスナップショット分離によるMVCC
- ロックを取らず他トランザクションと競合しない
- ファントムリード、書き込みスキューは発生。アプリケーション側で考慮が必要
- 強い整合性とレイテンシを両立
- スケーラビリティ
- Serverlessでありスケールアウト/スケールインが可能
- 複数のコンポーネントに分かれており、内部的にそれぞれでスケール可能
用語の整理
DSQLのアーキテクチャを理解する前に、RDB、NewSQLの理解に必要な概念を整理をしましょう。
CAP定理
CAP定理とは、分散システムにおいて以下の3つの性質を同時に満たすことができないという理論です。以下の3つのうち、どれか2つを優先して設計しなければならないとされています。
- Consistency(一貫性)
- すべてのノードが同じデータを持つことを保証する
- ユーザーがどのノードにアクセスしても最新のデータを取得できる
- Availability(可用性)
- システムが常に動作しており、リクエストが失敗せず応答することを保証する
- Partition tolerance(分断耐性)
- ネットワーク障害などによりノード間の通信が途絶えてもシステムが動作し続けられること
NoSQLは一貫性を犠牲に可用性やパフォーマンスを重視した設計が多いですが、
NewSQLはそれらの特徴に加えてリレーショナルデータベースとしてのトランザクション制御もサポートする新しい形のデータベースです。
以下の星取表は、細かくは賛否ありそうですが、概ね以下の理解をしています。
| 特徴 | 単一のRDBMS | NoSQL | NewSQL |
|---|---|---|---|
| 一貫性 (C) | ○:強い一貫性 | ×:最終的な一貫性 | ○:強い一貫性 |
| 可用性 (A) | ○:高い | ○:非常に高い | △:妥協された可用性 |
| 分断耐性 (P) | ×:弱い(分散前提でないため) | ○:高い | ○:高い |
| スケーラビリティ | ×:制限がある | ○:高い | ○:高い |
| トランザクション | ACID | BASE | ACID |
NewSQL
強い整合性を持ち、ACID特性を持つトランザクション処理が可能、その上で地球規模の分散が可能なSQLデータベースとして、Google Spanner や TiDB など多くの製品が存在します。
CAPの優先度としては、スケーラビリティのため分散DBとしてPは必須要件です。また、RDBとしてACIDトランザクションを満たす強い一貫性が必要なためCも必須です。その上で可能な限りリージョン障害やネットワークにも耐えうるアーキテクチャとして登場したものが NewSQL です。
Aurora DSQLはマルチリージョン構成で 99.999% の可用性との説明があり、実際にはプロダクトとしてはAも満たせているように思われますが、上記の表では単純に表現できない細かいトレードオフは存在します。上記の表はあくまで目安として、それらに注意して製品選定する必要があります。
トランザクション処理におけるACID特性
ACID特性は、データベーストランザクションにおいてデータの信頼性を常に保証するための4つの特性を指します。
NoSQLでは、このACID特性を犠牲にしてスケーラビリティや可用性を重視していますが、NewSQLはこのACID特性を満たしています。
- Atomicity(原子性)
- トランザクションが「すべて成功する」か「すべて失敗する」かを保証します
- 部分的に成功した状態は存在せず、失敗時にはすべてロールバックします
- Consistency(一貫性)
- トランザクションの開始前後で、データベースは常にルールや制約を満たした状態を保ちます
- Isolation(分離性)
- 複数のトランザクションが同時に実行されても互いに干渉せず、あたかも1つずつ実行されたかのように見えることを保証します
- 分離性を実現する方法: OCCやMVCCなど
- Durability(永続性)
- トランザクションが成功した場合、その結果は障害が発生しても永続的に保存されます
- コミット時にログデータが永続化され、データの永続性が担保されます(ログ先行書き込み:Write-Ahead Logging, WAL)
同時実行制御
並行処理制御・排他制御とも言います。
これは通常のRDBにおける概念ですが、DSQLを理解する上でも理解が重要だと感じました。
多くのリレーショナルデータベースでは、悲観的同時実行制御(PCC)と呼ばれる手法が主流ですが、DSQLはデフォルトで楽観的同時実行制御(OCC)を採用しています。
これはDSQLの大きな特徴の1つですが、他のNewSQL製品でもOCCはサポートしているものが多いです。
PCC(悲観的同時実行制御: Pessimistic Concurrency Control)
トランザクションは他のトランザクションと競合する可能性が高いという前提での制御方法です。
事前にロックを取得して競合を防ぐことにより、トランザクションが他のトランザクションと干渉しないようにします。
つまり同じデータに対して同時に処理された他のトランザクションはロック解放を待ち後から処理されるため、結果的には後勝ちとなります。
- メリット: 競合が発生するリスクを回避でき、常に一貫性が保証される
- デメリット: ロックを取得するため、スループットや並列性低下の可能性。デッドロックが発生するリスクもある
OCC(楽観的同時実行制御: Optimistic Concurrency Control)
トランザクションは他のトランザクションと競合する可能性を低いという前提での制御方法です。
基本的にロックをかけることはなく、トランザクション終了時に競合が発生しなかったか検証します。競合が発生した場合はコミットせず処理をアボート(中断)します。
つまり同じデータに対して同時に処理された場合は先勝ちとなります。
- メリット: 高いスループットと並列性を実現でき、特に競合が少ない環境では効率が良い
- デメリット: 競合が多く発生する環境ではアボート率が増え再実行も必要になる

トランザクション分離レベル
トランザクション分離レベルは、データベースが複数の同時のトランザクションに対してどの程度の隔離(分離性)を提供するかを定義するものです。
逆に言えば、どこまでデータの不整合を許容するかの定義です。
よく見るトランザクション分離レベルの表です。
DSQLで重要になるSNAPSHOT ISOLATIONも合わせて記載します。
○が発生する不整合です。
| 分離レベル | ダーティリード | ノンリピータブルリード | ファントムリード | ライトスキュー |
|---|---|---|---|---|
| READ UNCOMMITTED | ◯ | ◯ | ◯ | ◯ |
| READ COMMITTED | × | ◯ | ◯ | ◯ |
| REPEATABLE READ | × | × | ◯ | ◯ |
| SNAPSHOT ISOLATION | × | × | ◯ | ◯ |
| SERIALIZABLE | × | × | × | × |

スナップショット分離(Snapshot Isolation)
スナップショット分離は、トランザクションが開始された時点でのデータの状態を「スナップショット」として取得し、そのスナップショットに基づいて読み取りを行う方法です。
トランザクションの読み取り結果は一貫しており、他のトランザクションが変更をコミットした場合でも、スナップショット分離を採用したトランザクションは開始時点のデータにアクセスし続けます。
MVCC (Multi-Version Concurrency Control )
スナップショット分離を実現するための代表的な排他制御アルゴリズムです。
MVCCはデータをバージョン管理することにより排他制御を実現します。
一般的に、バージョンはタイムスタンプやカウンタで制御されます。
これも通常のRDBでサポートされており、PostgreSQLでも Repeatable read がそれに相当します。

書き込みスキュー(Write Skew)
2 つの同時トランザクションが共通のデータを読み取るが、それぞれが共通のデータセットを変更する更新を行いますが、お互いに更新データは重複しない場合、更新は競合しないのでコミットが通ってしまいます。
これはスナップショット分離でも発生する不整合ですが、アプリケーション側で対応することができます。
SELECT FOR UPDATE を使うことで、SELECTに対しても同時実行制御を効かせることができます。
そのため、後からコミットしたトランザクションは、もう片方のトランザクションによる更新を検知してエラーになります。
OCCのため排他ロックを取るわけではありませんが、以下のエラーが出ます。
ERROR: change conflicts with another transaction, please retry: (OC000)
線形化可能(Linearizability)とは
線形化可能性は、分散システムにおける一貫性モデルの1つで、高い一貫性を実現していることを意味します。

以下のサイトの図が分かりやすいです。
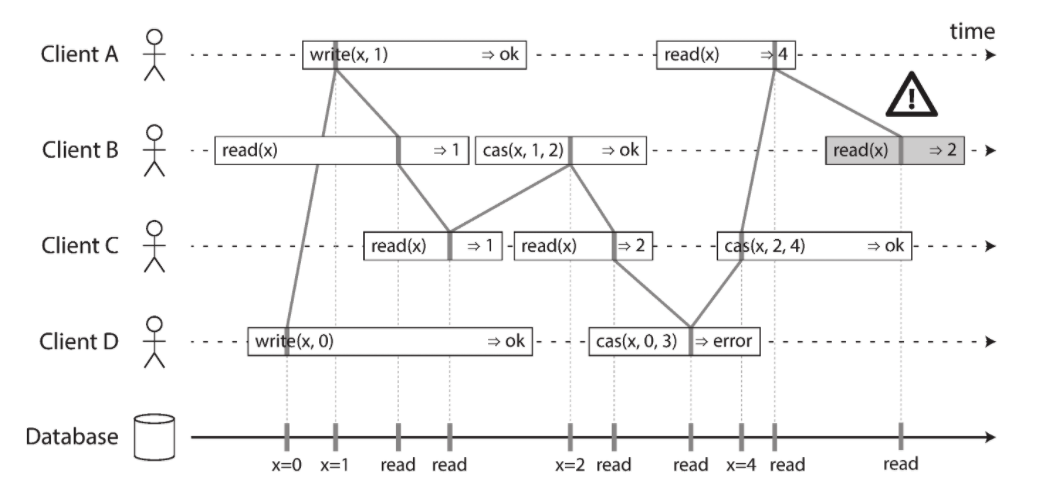
複数のトランザクションが同時に値を参照・更新していますが、特定の時刻で値は一意に決まっています。
つまり、分散システムにおいてすべての操作が1つのタイムライン上で発生したように見えることを保証していることになります。
DSQLにおいては、複数のリージョンで行われた書き込みが即座に他のリージョンに反映されるような一貫性を保ちます。
Amazon Time Sync Service
分散データベースにおいて最大の懸念は、異なるノード間のローカル時間にズレによって生じるクロックドリフトという問題です。これによりタイムスタンプを使用したトランザクション順序や整合性を保つことが困難になります。
そこで、Amazonは新たにTime Sync Serviceという機能を導入しました。
このサービスは、EC2インスタンスを衛星の原子時計と同期させることによって、マイクロ秒単位の精度でグローバルな時間同期を実現します。これによりクロックドリフトによる問題を解決し、分散データベースで整合性と短いレイテンシを両立させています。
GoogleのNewSQLデータベースである Google Spanner でも TrueTime API と言う機能によって時刻同期が実現されています。
分散合意アルゴリズム(2PL,Paxos,Raft, Calvin...)
以下のスライドがとても勉強になりました。
最もオーソドックスなアルゴリズムが2PC(Two Phase Commit)と呼ばれるものです。
このアルゴリズムはノードの障害時に破綻するケースがあり、Google Spanner ではそれを改良した Paxos というアルゴリズムを採用しています。
しかし、Paxosは複雑であるというデメリットからRaftというアルゴリズムが生まれ CockroachDB や TiDB はこちらを使っているようです。
Raftは、死活監視、リーダー選出、ログ複製といった機能によって分散合意を実現しているようで、比較的直感的に理解しやすい仕組みになっています。
Aurora DSQLはどうかと言うと、具体的なアルゴリズム名は明言されていませんでした。
しかし発表の中でリーダーの概念は存在しないと明言しており、Raftではないと思われます。
公式の発表ではないですが、X上で何人かの方がFaunaDBで採用されている Calvin というアルゴリズムかそれに近いもののではと発言しています。
1つ目のスライドの最後にも記載がありますが、Paxosと比較してCalvinの方がシンプルかつ速度的にも優位なようです。
この辺りはAWSからの公式発表を待ちたいと思います。
プッシュダウン
セッションの中で「プッシュダウン」と言う用語が分かりませんでした。
どうやらこれはパフォーマンス最適化の1つとして、PostgreSQLの拡張機能である外部データラッパー(Foreign Data Wrapper)という機能を指しているようです。
通常、SQLエンジンはクエリを解析し必要なデータをストレージエンジンから取得しますが、プッシュダウンを利用することで、WHERE句などの一部のフィルター操作をSQLエンジンではなくストレージエンジンに任せることで、不要なデータの転送を防ぎ、効率的な処理を実現します。
これにより、SQLエンジンとストレージエンジン間の通信回数が減り、パフォーマンスが大幅に向上します。
前半のまとめ
ゼロから分散データベース、Aurora DSQLを理解するには前提となる知識が多いですね。
re:Inventのセッションは、Youtubeで公開されています。この記事で紹介した用語を理解していれば、内容は理解できるかと思います。(私は少し理解できるようになりました)
後半ではDeepdiveセッションで説明されたアーキテクチャと、Workshopで学んだ実際のアプリケーション側の実装と注意点についてまとめようと思います。
その他参考文献
- DSQLセッションを担当していた Marc Brooker さんのブログ
- DSQLの同時実行制御に関するブログ
- 各DBMSのトランザクション分離レベルの詳細な一覧
https://github.com/ept/hermitage/blob/master/README.md - MVCC、スナップショット分離、書き込みスキューについて