こんにちは。
この記事は ZOZO Advent Calendar 2024 シリーズ5 22日目の記事です。
AWS re:Invent 2024に現地参加し、新サービスであるAurora DSQLについて学んだことをまとめます。
New SQLを理解する上で必要な前提知識は前半にまとめてますので合わせてご覧ください。
Aurora DSQLのアーキテクチャDeep dive
DSQLはマルチリージョンの分散データベースです。複数のリージョンから書き込みが可能で、かつ高い可用性と低レイテンシを両立しています。
まずはDSQLのアーキテクチャ全体像を見てみましょう。
Witnessリージョン
Aurora DSQLはシングルリージョンでも利用できますが、マルチリージョンで構築することにメリットがあります。
マルチリージョンの場合、データをレプリケーションする2リージョンと、障害時の可用性を担保するためにWitnessリージョンの計3リージョン必要になります。
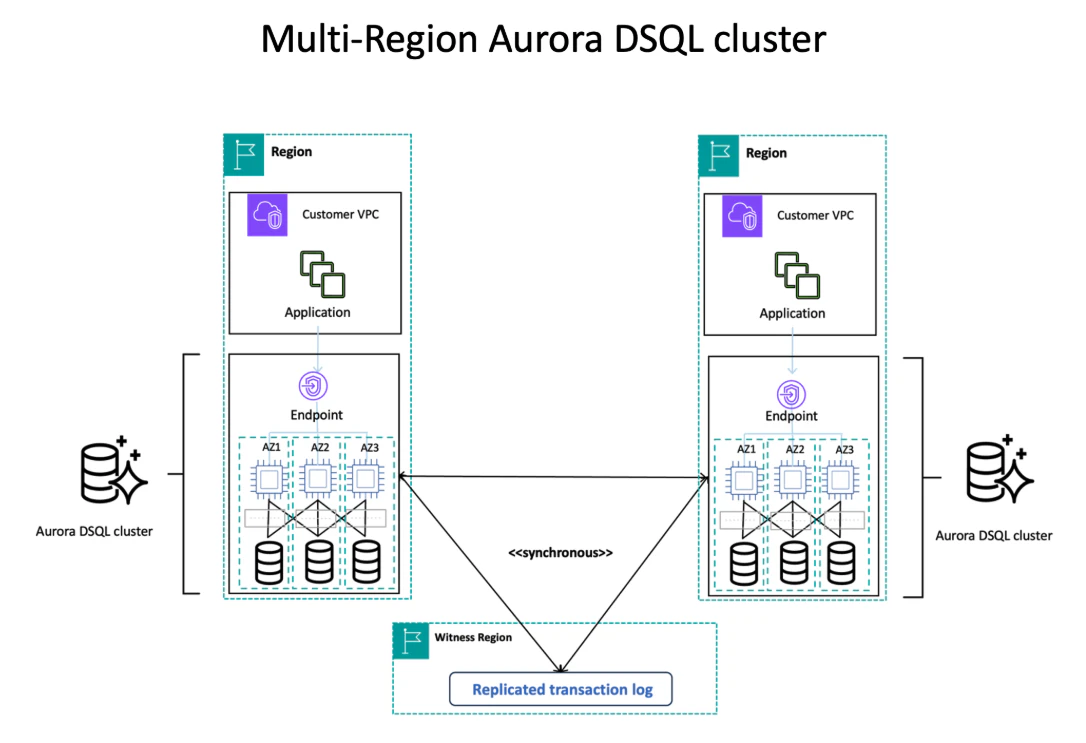
Witnessとは証人という意味です。Witnessリージョンは、Raftなどの分散合意アルゴリズムにおいて、合意のプロトコルには参加するがデータの複製を持たないノードを指します。
Raftなどの分散合意アルゴリズムではノードの過半数の合意によって処理が決定します。そのため1リージョンで障害が発生しても機能するためには最低3リージョン必要です。
データは2リージョン間で複製されていれば高可用性が担保されるため、Witnessリージョンはデータを持ちませんが、トランザクションのログはレプリケーションされるようです。
プレビュー時点ではまだ日本リージョンには対応していませんが、日本には2リージョンしかないため最低1つは海外リージョンを選ぶ必要がありそうです。
内部アーキテクチャ
re:Invent 2024のセッションでは、Aurora DSQLのアーキテクチャ詳細について解説がありました。特徴はレイヤー間の独立性です。各レイヤーは特定のワークロードの要求に基づいて、水平方向に独立してスケールします。

読み取りが多いワークロードではStorageレプリカが増加し、書き込みが多い場合はJournalというコンポーネントが分割され水平にスケールします。
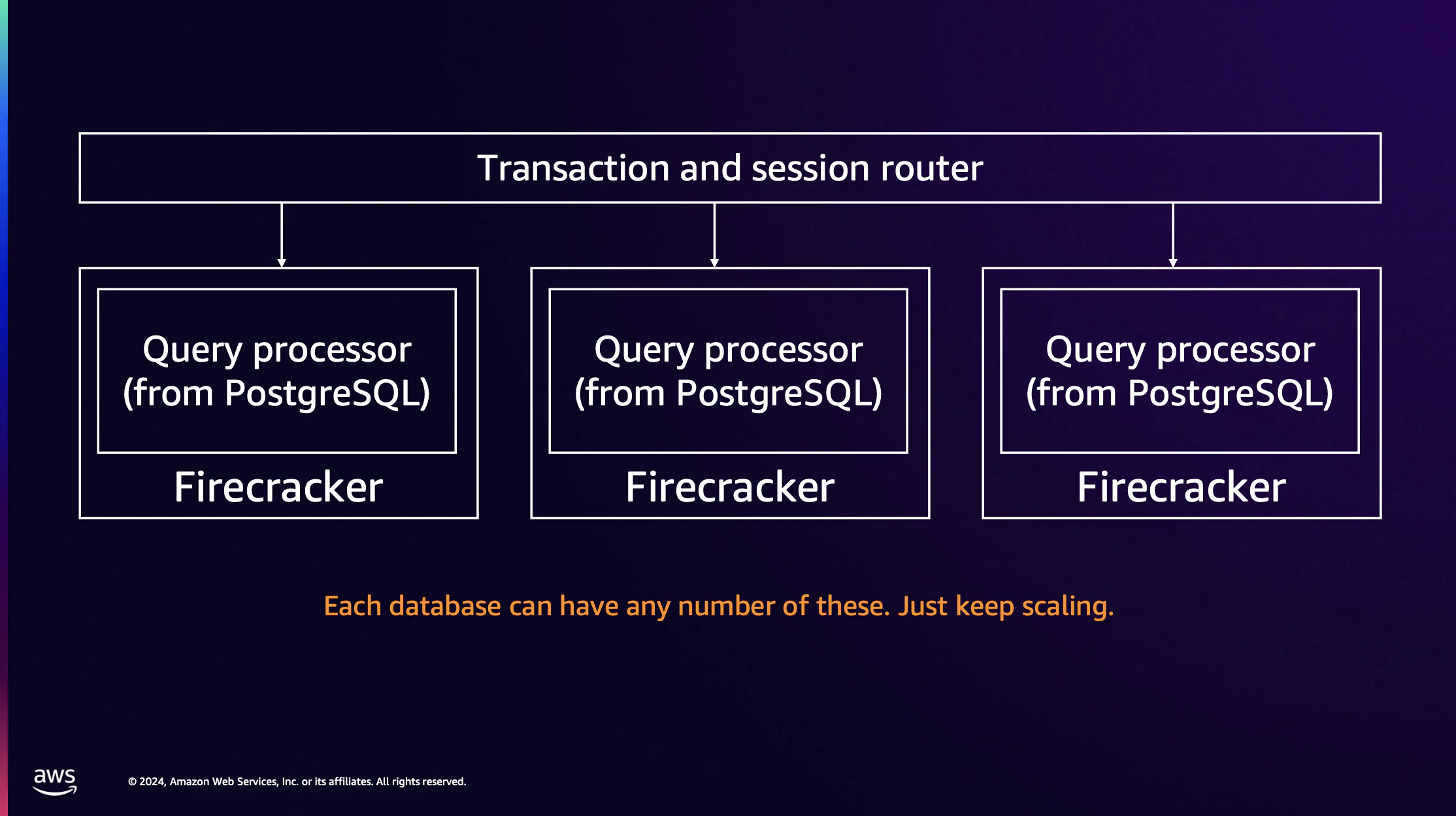
1.Transaction and Session Router
PostgreSQLのプロトコルでをリクエストを受け取り、トランザクションの開始時に各接続を適切な場所にルーティングします。また、PG Bouncerのように接続プーリングを提供します。
2.Query Processor
リクエストはSession Routerを通してQuery Processorへ流れます。Query ProcessorはPostgreSQLのデータベースエンジンにあたり、Firecracker上で稼働しています。FirecrackerはAWS LambdaやFargateなどで使われている軽量VMで、高速なスケーラビリティを可能にしています。
読み込みはQuery ProcessorからStorageにアクセスします。
前編でまとめたように、読み取りはスナップショット分離で実行されるため、読み込みではロックは発生せず他のトランザクションを気にせず実行されます。
トランザクションの開始時にその時の時刻(t)を読み取ります。そのトランザクションが読み取るデータは時刻(t)のものとなり、どのノードに問い合わせても時刻(t)の同じ結果が返ります。
そのため読み取り処理ではノード間の調整は不要で、2フェーズコミットやRaftのような分散合意は不要です。
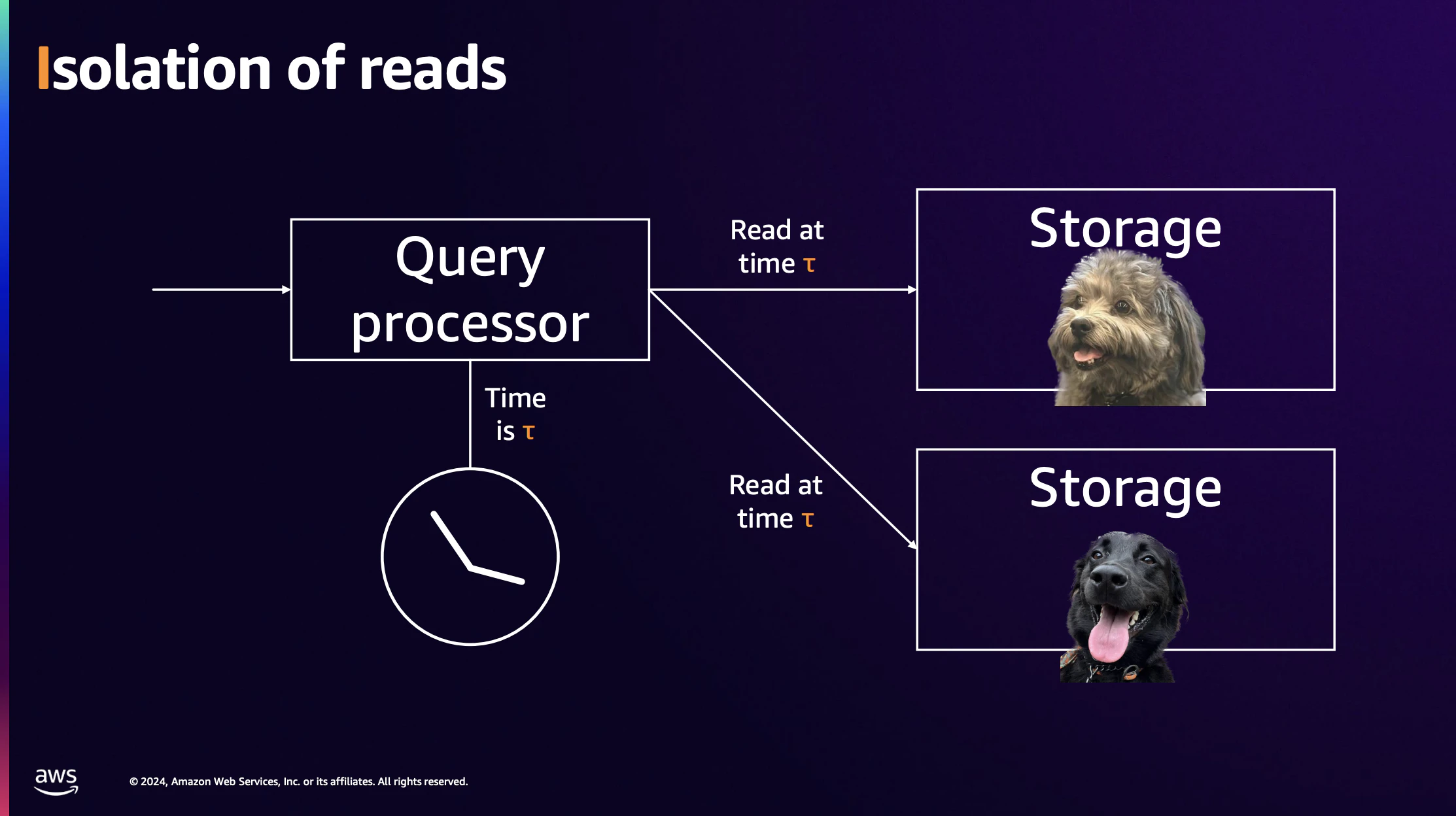
「t(3)でこのデータをリードしてください」と指示されると、ストレージノードはt(3)のデータを探します。既にt(4)のデータが存在してもそれは無視されますが、逆にt(2)までのデータしかない場合は、時刻(3)の状態がJournal(後述)によって反映されるまで少し待つようです。

読み取りの処理
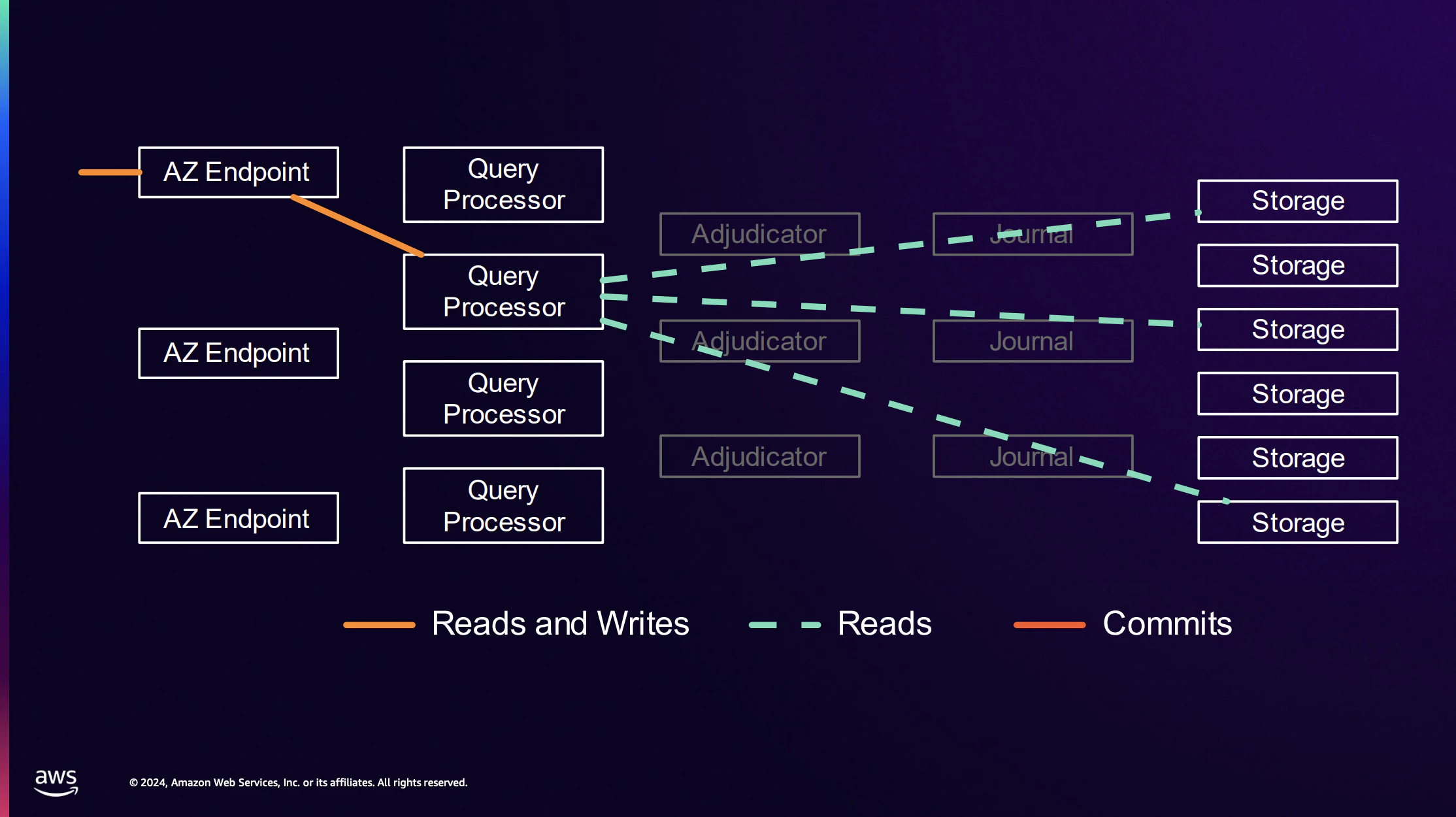
書き込みは一旦Query Processor内に留まり直接Storageへはアクセスせず後述のAdjudicatorとJournalによって行われます。
書き込みの処理
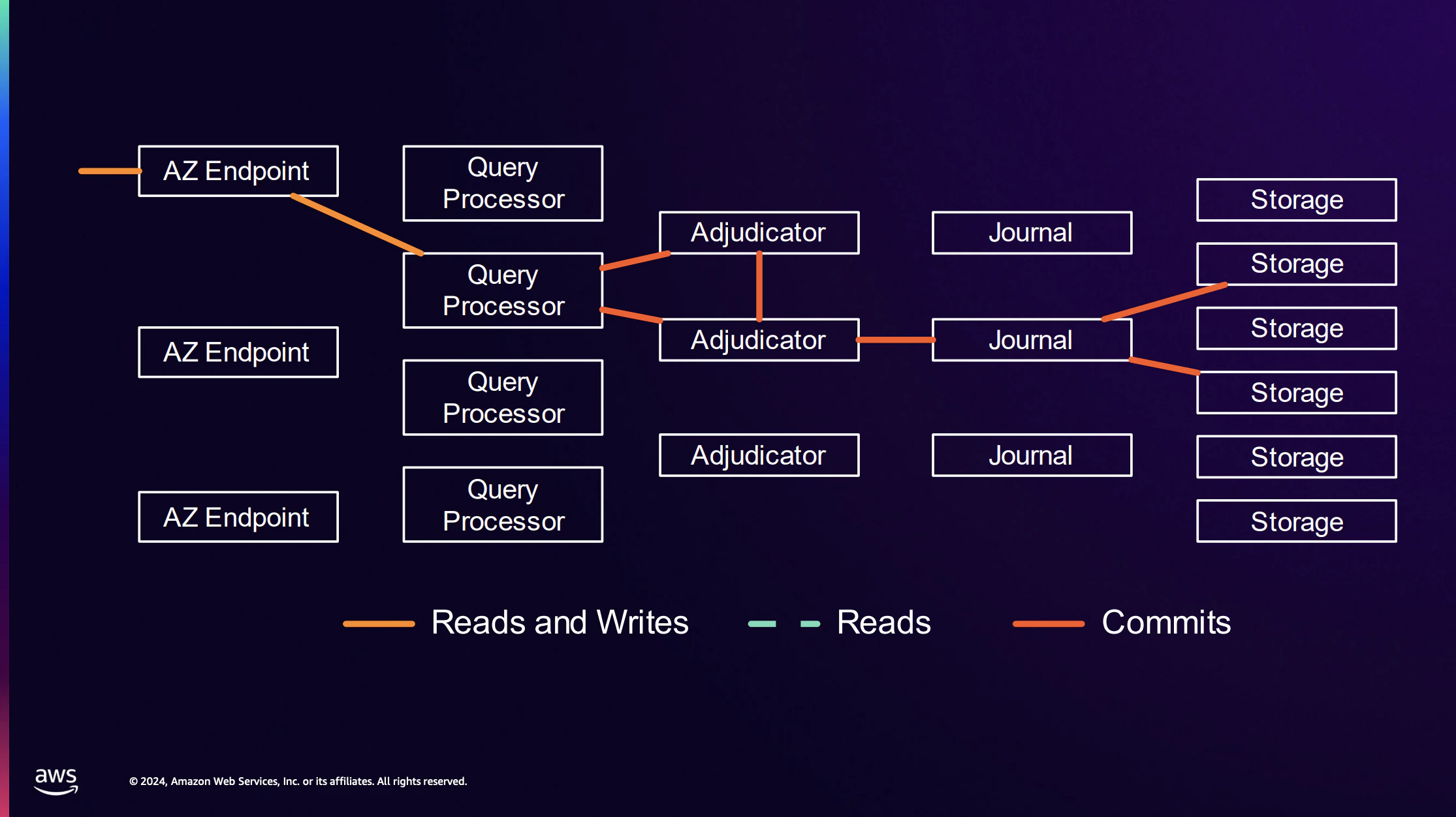
3.Adjudicator
Adjudicatorは、書き込み時の分散合意を担いデータの一貫性を保証します。書き込み時に複数のトランザクション間の競合を検証し処理の分離性を確保します。Query Processorは複数のAdjudicatorに対して「このトランザクションをコミットしても良いか?」と問い合わせます。競合がなく問題ないと判断されればAdjudicatorがJournalへログを書き込むよう指示しコミットが完了します。
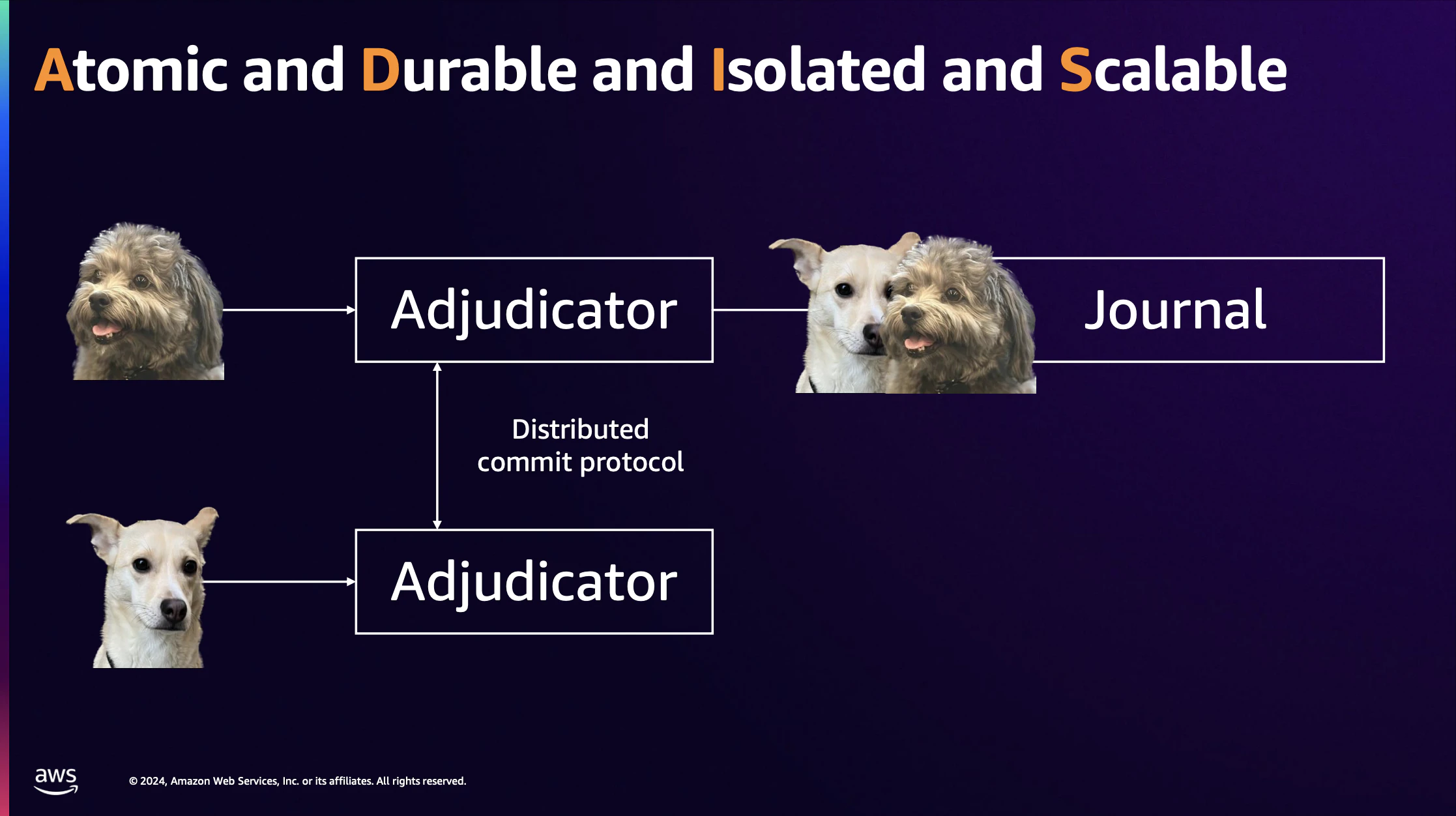
4.Journal
Journalはデータの永続性と原子性を保証します。必ず1つのJournalがログをStorageへ書き込むことで原子性が保たれます。
すべての読み取り操作は上述のt(start)で実行され、データベースに書き込む際のコミット時は別の時刻t(commit)で処理します。トランザクションがコミットできるのは、t(start)とt(commit)の間に他のトランザクションが同じキーへの書き込みを行っていない場合のみです。競合がない場合はt(commit)でJournalに書き込まれコミットされます。
トランザクションをコミットした後は、より小さなt(commit)が選択されることはなく、読み取りと書き込みの一貫性が保たれます。
5.Storage
効率的なデータ検索に特化したストレージエンジンです。役割が分離されているためACID特性のいずれの責任も負いません。
パフォーマンス最適化策の1つとして、本来Query Processor上で行われる一部の処理をStorage側にプッシュダウンできます。WHERE句のフィルター操作などをストレージノード側で行うことにより、通信にかかるラウンドトリップとデータ量の削減に繋がりレイテンシが向上します。
DSQLにおける同時実行制御の整理
ここまでアーキテクチャの話をまとめましたが、同時実行制御について整理します。
DSQLでは、読み取りのトランザクションに MVCC (Multi-Version Concurrency Control) を採用しています。他のトランザクションがデータを変更しても、そのトランザクションが開始された時点のデータのバージョンを参照するため、読み取りのトランザクションは競合を回避でき常に一貫性のあるデータを返します。
以下のポストではMVCC+TOと書かれていますが、Transaction Orderingの略と思われます。
書き込みトランザクションには OCC(楽観的同時実行制御) を採用しています。これにより書き込み時にもロックを取らず、トランザクション終了時に競合を確認して、競合が発生した場合にロールバックされます。
DSQLを実際に触ってみる
Workshopにも参加したため、設計やアプリケーション側の実装例も紹介します。
DSQLの構築
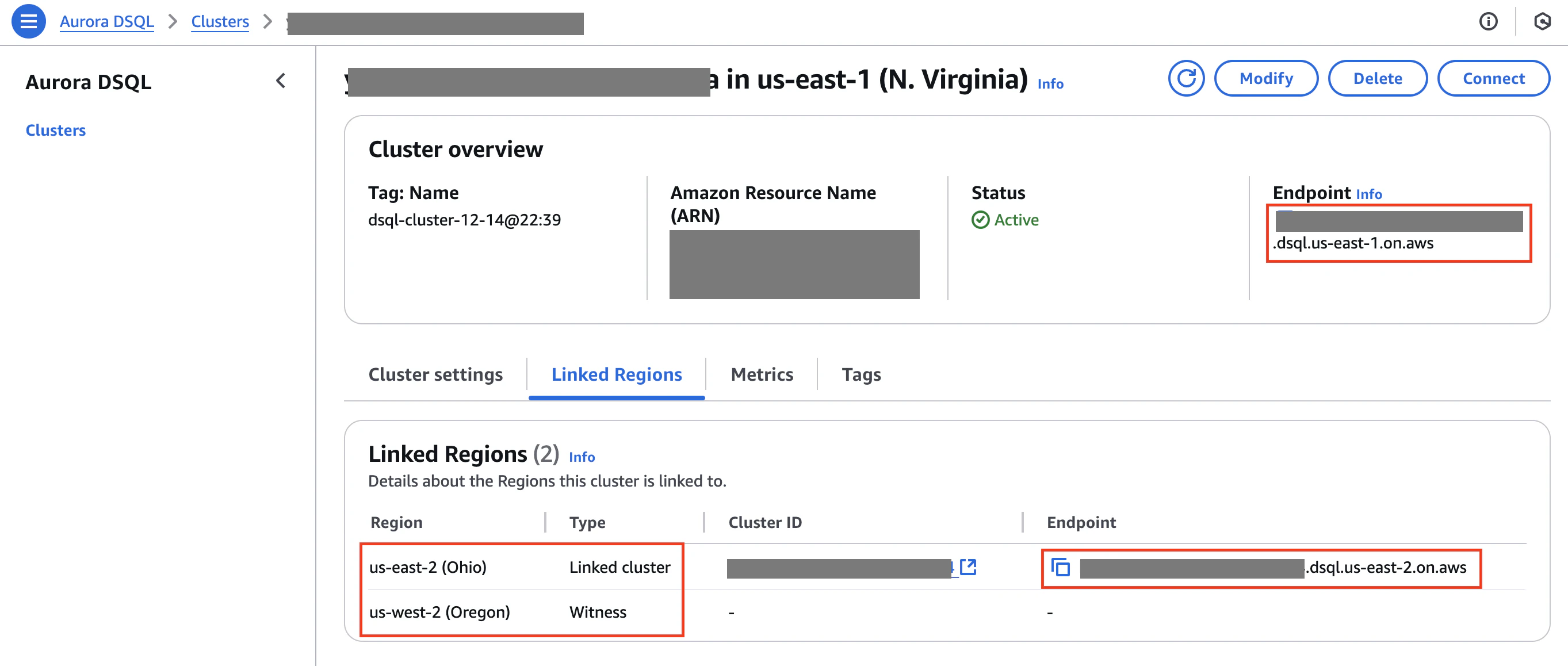
マネジメントコンソール上ではAuroraとは別リソースとして表示されます。
構築時にリージョンを複数選択する必要があります。
以下のキャプチャは1つ目のリージョンの画面で、Linked Regionに2つ目のリージョンとWitnessリージョンの記載があり、Clusterの存在するリージョンにそれぞれエンドポイントが割り当てられています。
接続方法
Aurora DSQL ではパスワード認証はできず、AWS CLIやSDKによって生成できる一時的な IAM 認証トークンでのみアクセスができます。
以下のようなIAMポリシーが必要になります。
{
"Version": "2012-10-17",
"Statement": [
{
"Sid": "AuroraDSQLDatabaseConnect",
"Effect": "Allow",
"Action": [
"dsql:DbConnectAdmin"
],
"Resource": "arn:aws:dsql:us-east-2:111122223333:cluster/*"
}
]
}
CLIで接続する場合、以下のように一時的なトークンを発行します。
DSQLへの接続はPostgreSQLの通常のドライバーで接続できます。
export CLUSTER_ENDPOINT=<<YOUR_CLUSTER_ENDPOINT>>
export PGPASSWORD=$(aws dsql generate-db-connect-admin-auth-token --hostname $CLUSTER_ENDPOINT --expires_in 14400)
export DBNAME="postgres"
export USER="admin"
export HOST=$CLUSTER_ENDPOINT
psql --dbname $DBNAME --host $HOST --username $USER --set=sslmode=require
書き込み処理の確認
更新が競合した場合先勝ちとなり、コミット時に競合が発生したトランザクションはエラーとなります。
-- リージョンAでSELECTを実行
postgres=> begin;
postgres=*> select address from xpoints.customers where username = 'carlos_salazar_125@example.edu';
address
---------------
4550 Z Street
(1 row)
-- リージョンAでUPDATEを実行
postgres=*> update xpoints.customers set address = '123 Main Street' where username = 'carlos_salazar_125@example.edu';
UPDATE 1
postgres=*>
-- -> まだコミットしないでおく
-- リージョンBでSELECTを実行
postgres=> begin;
postgres=*> select address from xpoints.customers where username = 'carlos_salazar_125@example.edu';
address
---------------
4550 Z Street
(1 row)
postgres=*>
-- -> リージョンAのUPDATEが未コミット状態なので更新前の値が取れた
-- リージョンBでUPDATEを実行してコミット
postgres=*> update xpoints.customers set address = '201 Rocky Blvd' where username = 'carlos_salazar_125@example.edu';
postgres=*> commit;
COMMIT
postgres=>
-- リージョンAでUPDATEをコミット
postgres=*> commit;
ERROR: change conflicts with another transaction, please retry: (OC000)
postgres=>
-- -> UPDATEが競合してエラーとなる(OCCの挙動)
読み込み処理の確認
MVCCによるバージョニングの挙動も確認しましょう。
同一トランザクション内では他のトランザクションによる更新の影響を受けません。またロックも発生しません。
-- リージョンAでSELECTを実行
postgres=> begin;
postgres=*> select age from xpoints.customers where username = 'carlos_salazar_125@example.edu';
age
-----
65
(1 row)
-- リージョンBでUPDATEを実行
postgres=> begin;
postgres=*> update xpoints.customers set age = 99 where username = 'carlos_salazar_125@example.edu';
UPDATE 1
postgres=*> commit;
-- コミットする
-- リージョンAでSELECTを実行
postgres=*> select age from xpoints.customers where username = 'carlos_salazar_125@example.edu';
age
-----
65
(1 row)
-- 結果は変わらず。MVCCの挙動によって他トランザクションで更新された値は読み取らない。
postgres=*> commit;
-- コミット成功。データを更新しないトランザクションに対して同時実行性をチェックしない
postgres=>
DSQLにおける設計や制約
主キー
DSQLの主キーはシャーディングによるレコードの分散にも使用されます。主キーを指定しない場合、Aurora DSQL は各行に非表示の UUID が割り当てます。テーブル作成後に主キーを変更または追加することはできません。
主キーは可能な限りランダムに分散するカラムにするべきです。
incrementする連番のキーを主キーにすると更新が特定ノードに集中してしまうためアンチパターンです。
この辺りは他の分散DBの注意点と同じです。
外部キー
DSQL は外部キー制約をサポートしていません。テーブルの依存関係を制御したい場合は、独自の操作順序を強制できます。通常のRDBでは、外部キーが付与されている親テーブルの行が削除されるたびに従属するレコードを同じトランザクション内で削除します。
分散DBでは、AWS Lambdaなどのイベント駆動型のアーキテクチャを採用して、異なるデータストア間でデータの一貫性を維持したり、カスケード操作を非同期で実行することが推奨されるようです。
その他制約など
データが既に存在するテーブルに対して、通常のCREATE INDEXでインデックス作成ができないようです。
DSQLでは、CREATE INDEX ASYNCを使うことで作成可能なようです。
このようにPostgreSQL互換とは言え、細かい違いが無数にあります。
現時点の細かい制約やPostgreSQLとの違いは、他の方の検証記事が参考になります。
リトライの実装と処理
DSQLではOCCを採用しているため、コミット時に競合した場合処理がアボートされます。
その場合は、アプリケーション側でリトライするなどの実装が必要になります。
Javaの例を見てみましょう。
package software.amazon.dsql;
import org.postgresql.jdbc.SslMode;
import software.amazon.awssdk.auth.credentials.DefaultCredentialsProvider;
import software.amazon.awssdk.regions.providers.DefaultAwsRegionProviderChain;
import software.amazon.awssdk.services.dsql.DsqlUtilities;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.PreparedStatement;
import java.sql.SQLException;
import java.util.Properties;
import java.util.UUID;
public class HelloDSQL3 {
private static final double JITTER_BASE = 20d;
private static final double JITTER_MAX = 1000 * 5d;
private static void backoff(int attempt) {
long duration = (long) (Math.min(JITTER_MAX, JITTER_BASE * Math.pow(2.0d, attempt)) * Math.random());
try {Thread.sleep(duration);} catch (InterruptedException ignored) {}
}
public static void main(String[] args) {
if (args.length == 0) {
System.err.println("Cluster endpoint URL is required");
System.exit(-1);
}
String dbEndpoint = args[0];
try {
Class.forName("org.postgresql.Driver");
} catch (ClassNotFoundException e) {
throw new RuntimeException("Unable to load PostgreSQL driver", e);
}
DsqlUtilities utilities = DsqlUtilities.builder()
.region(DefaultAwsRegionProviderChain.builder().build().getRegion())
.credentialsProvider(DefaultCredentialsProvider.create()).build();
String password = utilities.generateDbConnectAdminAuthToken(builder -> builder.hostname(dbEndpoint));
Properties props = new Properties();
props.setProperty("user", "admin");
props.setProperty("password", password);
props.setProperty("sslmode", SslMode.REQUIRE.name());
String jdbcUrl = String.format("jdbc:postgresql://%s:5432/postgres", dbEndpoint);
try (Connection conn = DriverManager.getConnection(jdbcUrl, props);
PreparedStatement stmt = conn.prepareStatement("update xpoints.customers set age = ? where id = ?");
AutoCloseable cleanup = conn::rollback) {
conn.setAutoCommit(false);
int attempt = 0;
while (attempt++ < 5) {
if (attempt > 1)
backoff(attempt);
try {
System.out.println("Attempt #" + attempt);
stmt.setInt(1, 40);
stmt.setObject(2, UUID.fromString("02bd4416-0759-4763-b256-2d97dccf37aa"));
stmt.executeUpdate();
//
// Do all sorts of interesting business logic here!
//
System.out.println("Sleeping for 15 seconds before committing...");
try {Thread.sleep(15000);} catch (InterruptedException ignored) {}
conn.commit();
System.out.println("Successful commit!");
attempt = 5 + 1; // Force attempts above the max
} catch (SQLException e) {
try {conn.rollback();} catch (SQLException ignored) {}
if ("40001".equals(e.getSQLState())) {
System.err.println("Concurrency collision!");
System.err.println();
}
if (attempt == 5 || !"40001".equals(e.getSQLState())) {
throw e;
}
}
}
} catch (SQLException e) {
System.err.println("MESSAGE: " + e.getMessage());
System.err.println("ERROR CODE: " + e.getErrorCode());
System.err.println("SQL STATE: " + e.getSQLState());
} catch (Exception e) {
e.printStackTrace();
}
}
}
この例ではクエリPreparedStatementとしてUPDATE文を1つ実行しているだけですが、自動コミットをオフにして、トランザクション境界を自分で設定できるようにしています。
DSQL基礎セッションでも以下のような説明がありました。可能な限り同一トランザクションに処理をまとめることで通信回数が減りパフォーマンスが上がるようです。
アプリケーションの制約の範囲内で、複数の処理を1つのトランザクションをまとめるようにしましょう。Auto Commitやそれに相当する方法を使用している場合、DSQLからレイテンシパフォーマンスを得られていない可能性が高いです
また、多くの更新処理により競合が多発する場合、リトライ処理によって余計に競合が増えてしまう懸念があります。よく取られる対策としてエクスポネンシャルバックオフとジッターという仕組みがあります。
エクスポネンシャルバックオフとは、リトライの間隔を指数関数的に増やしていく手法で、ジッターは、リトライの待機時間にランダム性を加える手法です。これらによりリトライが一斉に発生するのを防ぎます。
上記のコードの場合以下のような設定でリトライされます。
- ベース待機時間 (JITTER_BASE):20ms
- 最初のリトライ待機時間の基準値
- 最大待機時間 (JITTER_MAX):5秒
- 待機時間がこれを超えないように制限
- リトライ回数 (attempt):最大 5回
- 5回までリトライ
- ジッター(ランダム性)の設定
- Math.random() を 0.0~1.0 の倍率で待機時間にばらつきを加える
まとめ
前後編に分けて分散DBの基礎用語からDSQLのアーキテクチャ、設計や実装時の注意点まで簡単に見てきました。
私に取っては真新しい内容でしたが、既存の分散DB・NewSQLとも特徴は近く、新しい要素はそこまで多くない印象を受けました。
DSQLで最も特徴的なのはOCCを採用している点だと思います。OCCの特徴や挙動に注意して設計・実装する必要がありそうです。
その他参考文献
- セッション動画
- ジッターを伴うリトライについて(DSQLのセッションを担当していた方の記事)
- スライド写真引用元