この記事は ZOZO Advent Calendar 2022 Vol.4の13日目の記事です。
今年の11月に入社した@tenn25です。
ZOZOTOWNでは、TECH BLOG等にあるようにSQLServerを利用しており、セールなどの大量のトラフィックを捌いています。
私自身SQLServerは利用経験があるものの、高頻度のアクセスによる待機処理やラッチについてあまり気にしたことがなかったため、良い機会なので調べてみました。
記事の内容
- ローカル環境でラッチ競合を再現する
- 待機待ちの挙動を確認する
- PAGELATCHの仕組み理解して対策を実施する
再現環境
- Windows11
- SQLServer 2016 Developer Edition
- jMeter
ラッチ競合を理解するための前提知識
SQLServerにおけるデータ領域の仕組みと、それらを制御するための同時実行制御の仕組みを理解する必要があります。
さらにどのような待ち事象があるかの理解も必要です。
もっと丁寧な解説記事がたくさんありますが、自分の言葉で簡単にまとめます。
データページ
SQLServerのデータファイルは、内部的に8KBに論理的な区切り(ページ)で管理されています。
一般的なテーブルは1レコードが8KBにも満たないので、基本的に1ページ内に同じテーブルのレコードが複数格納されます。
データの更新や参照によるIOはページ単位で行われるため、1レコードを取得するだけでもページ単位での取得が行われます。
ロックとラッチ
ページアクセスの排他制御のために、DB内部で取得される小さなロックのようなものです。
最小単位が行単位であるロックと異なり、ラッチはページ単位で発生します。
基本的にラッチの取得時間は非常に短いため問題になりませんが、大量の更新や参照が同一ページに集中するとラッチの取得待ちが発生し、積み重なるとボトルネックとなるケースがあります。
こうしたラッチは、テーブルのユーザーデータが入ったページだけでなく、ページの利用状況を管理する内部的なページ領域や、インデックス領域、ログ領域でも同様に発生します。
また、ディスク上のデータアクセスでもメモリ上のバッファへのアクセスでも起こります。
ラッチ競合を再現する
適当なテーブルを作成します。カラムが2つだけの容量の少ないテーブルです。
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'dbo.HeavyInsert') AND type in (N'U'))
DROP TABLE dbo.HeavyInsert
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'dbo.HeavyInsert') AND type in (N'U'))
CREATE TABLE dbo.HeavyInsert(
ID int IDENTITY(1,1) NOT NULL
, col1 VARCHAR(50) NOT NULL)
GO
CREATE UNIQUE CLUSTERED INDEX CIX
ON dbo.HeavyInsert (ID)
GO
大量のアクセスを再現するために、今回はjMeterを使います。
100以上のスレッドで以下のクエリを実行します。
SET NOCOUNT ON
DECLARE @i int = 1
BEGIN TRAN
WHILE @i <= 1000
BEGIN
INSERT INTO [AdventureWorks2017].dbo.[HeavyInsert] (col1) VALUES ('testing heavy')
SET @i += 1
END
COMMIT
※ループの外側でBEGIN TRANで明示的にトランザクションを張らないと、トランザクションログの書き込みがINSERT毎に発生し、WRITELOGという待機事象が大量発生してしまったので、上記のようにしています。
再現結果
実行中のクエリの待機状態を確認
確認クエリ
SELECT
der.session_id as spid, der.blocking_session_id as blk_spid, wait_resource, wait_type,
last_wait_type, datediff(s, der.start_time, GETDATE()) as elapsed_sec, der.status, dest.text
FROM
sys.dm_exec_requests der
JOIN sys.dm_exec_sessions des ON des.session_id = der.session_id
OUTER APPLY sys.dm_exec_sql_text(sql_handle) AS dest
OUTER APPLY sys.dm_exec_query_plan(plan_handle) AS deqp
WHERE
des.is_user_process = 1
ORDER BY
blk_spid
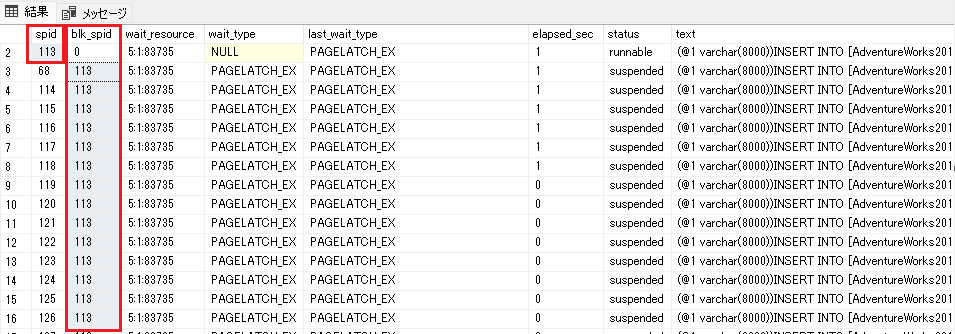
1つのINSERT処理(spid=113)がブロッカーとなって、他のINSERTがPAGELATCH_EXで待たされていることが確認できました。
発生した待ち事象の長さを種類別で確認
確認クエリ
--DBCC SQLPERF("sys.dm_os_wait_stats",CLEAR); //事前に計測値をクリアしておく
--DBCC SQLPERF("sys.dm_os_latch_stats",CLEAR); //事前に計測値をクリアしておく
SELECT *
FROM sys.dm_os_wait_stats
WHERE wait_type IN ('LATCH_EX','LATCH_SH','PAGELATCH_EX','PAGELATCH_SH','PAGEIOLATCH_SH','PAGEIOLATCH_EX')
ORDER BY wait_type
SELECT *
FROM sys.dm_os_latch_stats
WHERE latch_class IN ('BUFFER','ACCESS_METHODS_HOBT_VIRTUAL_ROOT')
ORDER BY wait_time_ms desc
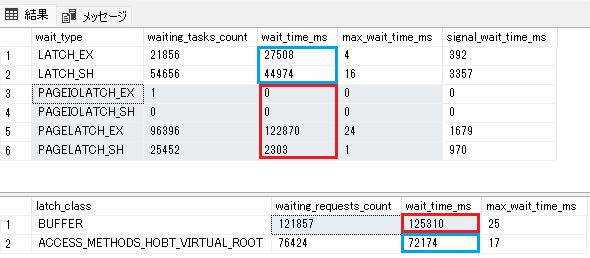
このクエリで発生しそうな主要なwait_typeに絞っています。
赤枠と青枠はそれぞれだいたい同じ合計値となり、概ね同じものを表しています。
赤枠がバッファーに関するラッチ(バッファーラッチ)
青枠がそれ以外に関するラッチ(非バッファーラッチ)です。
上のsys.dm_os_wait_statsは
- バッファーラッチの内訳詳細を見ることができます。
- 非バッファラッチは
LATCH_**としてまとめられています。
下のsys.dm_os_latch_statsは
- 非バッファラッチの内訳詳細を見ることができます。
- バッファラッチは、
BUFFERとしてまとめられています。
今回のクエリでは、PAGELATCH_EXというバッファラッチと、ACCESS_METHODS_HOBT_VIRTUAL_ROOTという非バッファラッチが多いです。
何が起きてるのか
PAGELATCH_EX
ページラッチは、メモリ上にキャッシュされているデータ領域を保護するために取得されるラッチです。
よくある例としては、ページ領域を管理するためのGAMという特別なページでこのPAGELATCHが発生することがあるようです。
今回はIDの連番キーでINSERTしているため、このテーブルの最終ページに対して大量の排他制御が集中したことでラッチ待ちが発生しているようです。
1レコードが小さいため、1ページに大量のレコードが含まれていることもあり、ページラッチが発生しやすいテーブルと言えます。
ACCESS_METHODS_HOBT_VIRTUAL_ROOT
公式ドキュメントには「内部 B ツリーのルート ページ抽象化へのアクセスを同期するために使用されます。」とあるのですが、
調べたところ、大量のINSERTによりデータ量が増えるに伴いインデックスのB-Treeを分割していく際に取得されるようです。
ラッチ競合(PAGELATCH_EX)の対策
調べたところ複数の対策法が出てきましたが、
今回はパーティション分割とHashキーの利用によってPAGELATCH_EXの競合を減らしてみます。
要は最終ページにInsertが集中しなければ良いので、INDEXにハッシュ値を含めた複合インデックスにすることでINSERT先のページを分散させるという手法を取ります。
IF EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'dbo.HeavyInsert_Hash') AND type in (N'U'))
DROP TABLE dbo.HeavyInsert_Hash
IF NOT EXISTS (SELECT * FROM sys.objects WHERE object_id = OBJECT_ID(N'dbo.HeavyInsert_Hash') AND type in (N'U'))
CREATE TABLE dbo.HeavyInsert_Hash(
ID INT IDENTITY(1,1) NOT NULL
, col1 VARCHAR(50) NOT NULL
, HashID AS CONVERT(tinyint, ABS(ID % 8)) PERSISTED NOT NULL)
GO
--Hash値をパーティション境界とする
CREATE PARTITION FUNCTION pf_hash (tinyint) AS RANGE LEFT FOR VALUES (0,1,2,3,4,5,6,7)
GO
--パーティションを作成する
CREATE PARTITION SCHEME ps_hash AS PARTITION pf_hash ALL TO ([PRIMARY])
GO
-- Hash値を含めた複合インデックス(この場合クラスター化インデックス)を作成する
CREATE UNIQUE CLUSTERED INDEX CIX_Hash
ON dbo.HeavyInsert_Hash (ID, HashID) ON ps_hash(HashID)
GO
このテーブルに対して、同様のINSERTを並列数を上げて試してみました。
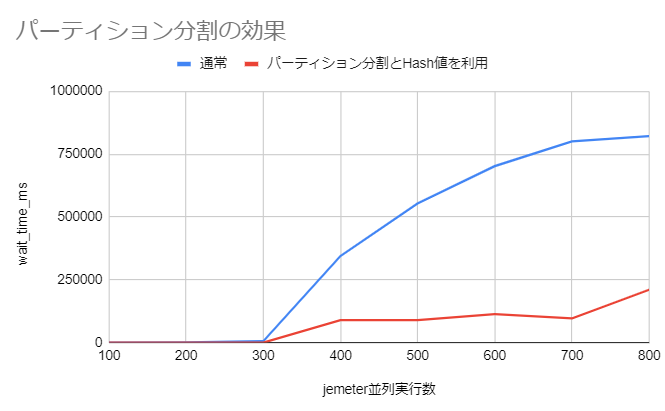
試行回数が少ないのであくまで参考値ですが、パーティション分割によりラッチ待ちが減っていることを確認できました!
ドキュメントを読んでいるだけだとイマイチ理解が難しいですが、手を動かしながらだと理解しやすいですね。
今後余裕があれば、PAGELATCHやPageIOLatchなども再現してみたいです。