C#大好きてんぷらです。ここでは、自分が普段よく使うC#の機能についてまとめたいと思います。
内容的にはすでに何らかのプログラム言語を一通り理解してる人向けです。
C#が他の言語と比べて好きな理由ってなんですか?
最近この質問をされました。その人はC#はおろかプログラム自体を最近始めたばかりで、一瞬どう答えようか固まりました。
自分はこう答えました。
プログラムは元々機械と会話するためのものでした。
機械と会話するためには日本語ではダメで、機械語で話さないといけません。
その機械語がプログラムです。
そして、昔は機械様のために会話していました。
しかし、それは苦行です。所詮、自分らはただの人間なので機械語は難しすぎるのです。
そんな苦労を見かねた偉い人がC#という言語を作りました。
C#は人間様が気持よく会話出来るものでした。
いわゆる人間よりの言語でした。
自分はここが他の言語と比べてC#が好きなところです。
型
C#の基本の型は、組み込み型とユーザ定義型がある。
組み込み型は以下の通り。
| 型 | 内容 |
|---|---|
| byte | 整数型 0 ~ 255 |
| sbyte | 整数型 -128 ~ 127 |
| short | 整数型 -32,768 ~ 32,767 |
| ushort | 整数型 0 ~ 65,535 |
| int | 整数型 -2,147,483,648 ~ 2,147,483,647 |
| uint | 整数型 0 ~ 4,294,967,295 |
| long | 整数型 -9,223,372,036,854,775,808 ~ 9,223,372,036,854,775,807 |
| ulong | 整数型 0 ~ 18,446,744,073,709,551,615 |
| char | 整数型(文字型) 'a' 'あ' '\n' |
| float | 浮動小数点型 ±1.5 × 10^-45~ ±3.4 × 10^38 |
| double | 浮動小数点型 ±5.0 × 10^−324 ~ ±1.7 × 10^308 |
| decimal | デシマル (-7.9 x 10^28 ~ 7.9 x 10^28) / (10^(0 ~ 28)) |
| bool | 論理型 true false |
| string | 文字列型 "てんぷら" |
| object | オブジェクト型 全ての型の親 |
C#の全ての型はobject型を継承している。
なのでこのようなことが出来る。
string str = "1";
int idx = int.Parse(str); // ← int という型にメソッドがある!?
str = idx.ToString(); // ← idx という数値にメソッドがある!?
この考え方、とても重要で、C#を使う上でのキーになっている。
コメント
下記3種類。使い分けは好みにもよるが自分は以下のように使用している。
// 1行コメント
/*
複数行コメント
*/
/// <summary>
/// ドキュメンテーションコメント(javaのjavadocのようなもの)
/// </summary>
/// <param name="arg">引数</param>
/// <returns>戻り値</returns>
/// ドキュメンテーションコメント
クラス、変数、メソッド、等、ドキュメント化する際に必要な箇所に必ず入れる。
// 1行コメント
コード内で分かりづらいところにのみ入れる(なるべく少ない方が良い)。
/* 複数行コメント */
あまり使用していない。複数行になる場合は1行コメントを行数分記述してる(コメントの書き方を統一したいから)。
定数
const と readonly の書き方がある。
class Demo
{
// よく使う使い方
const int Id1 = 1; // const -> コンパイル時定数(コンパイル時に値が決まる)
static readonly int Id2 = 1; // readonly -> 実行時定数(実行時に値が決まる)
// constはnewするものに使えない
const DateTime Time1 = new DateTime(2016, 11, 23); // NG
static readonly DateTime Time2 = new DateTime(2016, 11, 23); // OK
// constは宣言時初期化のみ。readonlyはコンストラクタで書き換えが可能
const int Id1 = 1; // 静的変数と同じ扱い
readonly int Id2 = 1; // staticじゃなくても使える
public Demo()
{
Id1 = 2; // NG
Id2 = 2; // OK
}
// constはローカル変数にも使える。readonlyはクラスのメンバ変数のみ
void Main()
{
const int id1 = 1; // OK
readonly int Id2 = 1; // NG
}
// 注意点:constはコンパイルしないと値が変わらない(外部参照を受けている場合危険)
public const int Id1 = 1; // constはなるべくpublicにしない方が無難
public static readonly int Id2 = 1; // readonlyは実行時に値が決まるのでpublicでも安心
}
私見
基本的にreadonlyのみ使う。
constはコンパイルしないと値が変わらないので外部参照を受けている場合、参照側もコンパイルし直さないといけない。コンパイル時に値が決まってなければいけないもの以外、使用は控えた方がいいと思う。
四角い配列 と 配列の配列
多次元のデータを扱うのに「四角い配列」と「配列の配列」の2種類がある。
// 四角い配列 -> 全ての列数が一緒
int[,] array0 =
{
// 初期化時にnew省略可
{ 1, 2 },
{ 3, 4 },
};
// 配列の配列 -> 列数を変えられる
int[][] array1 =
{
new[] { 1, 2, 3 },
new[] { 4 },
};
私見
自分は普段、配列の配列をほとんど使用しない。絶対に使用しないぞ!ってより、自然と四角い配列しか使ってないなーって感じ。
特に事情がない限りは四角い配列を使った方がパフォーマンスも良くなるのでいい。
for と foreach
ループ構文にこの2種類がある(whileは省略)。
string[] strs = { "赤", "燈", "レインボー" };
// for -> インデックスが取れる
for (int i = 0; i < strs.Length; i++)
{
string str = strs[i];
}
// foreach -> iがなくなる(変数が減る)
foreach (string str in strs)
{
}
私見
自分は以下のルールで使用している。
- for -> インデックスが必要な場合(最初の時点で必要なくても今後必要になるかもしれない場合も)
- foreach -> それ以外の使えるところ全部
foreachにした方が記述がスッキリするので好き。
キャスト
キャスト演算子、as演算子がある。
どちらもキャストする点は一緒だが、as演算子はキャストに失敗した場合nullになる(asキャストは例外がはかれない)。
object data = ***;
var user = (User)data; // キャスト演算子
var user = data as User; // as演算子
| キャスト演算子 | as演算子 | |
|---|---|---|
| 型 | 何でもOK | 参照型のみ |
| キャスト失敗時 | 例外 | null |
| 特徴 |
・どんな型でも使える ・例外処理が必要 ・型情報が左端 |
・参照型にしか使えない ・例外処理がいらない ・型情報が右端 |
私見
自分は以下のルールで使用している。
- 右辺の型が絶対に変わらない場合はキャスト演算子
- それ以外はas演算子
右辺の型が絶対に変わらない場合は、あえてキャスト演算子にして意図を明確にするのが好き。
それ以外はasで例外が吐かれないようにしておく。
ちなみに型判別だけしたい場合はis演算子を使用。
object data = ***;
if(data is User)
{
// 型がUserの場合
}
asしてからnullチェックするよりも、こちらの方が直観的なコードになる。
型推論(var)
型情報を右辺から推測して決める。
var user = (User)data; // キャスト演算子
var user = data as User; // as演算子
var user = Get<User>(); // ジェネリック
var user = User.Tempura; // enum
var user = User.Create(); // 型が予想できるもの
特徴
- コードを短く出来る
- 左辺が揃いやすく整ったコードになりやすい
- 型の識別には右辺の情報が必要
私見
自分は使えるとこ全てvarにしてる。当初は可読性が低下するのではないか不安だったけど、意外と大丈夫。それに、varで型がわかりづらくなるデメリットよりも、コードが冗長になるデメリットの方が大きいと感じる。
列挙型(enum)
名前付き定数の集まり。
// enum(通常)
enum CharaType
{
Yusha,
Monster,
NPC
}
// enum(型、初期値指定)
enum Job : int // 型(整数)
{
Hand = 1, // 初期値
Sword = 2,
Magic = 3
}
static readonly string[] CharaNames = { "勇者", "モンスター", "NPC" };
void Main()
{
var type = CharaType.Yusha;
var job = Job.Sword;
// 判定
if(type == CharaType.Yusha && job == Job.Sword)
{
// 勇者で剣士だった場合
}
// 要素名の取得(enumの値をインデックスに使用)
string name = CharaNames[(int)type];
// 文字列出力(分かりやすい)
Console.WriteLine(type.ToString()); // Yusha
Console.WriteLine(job.ToString()); // Sword
}
私見
とても便利。グループで扱われる定数は基本enum使う。
ビット操作
ビット操作はenum使うと便利。分かりやすく、管理もしやすい。
/// <summary>
/// じゃんけんの手
/// </summary>
enum Janken : int
{
Gu = 0,
Choki = 1,
Pa = 2
}
/// <summary>
/// じゃんけんのビット値
/// </summary>
[Flags] // 文字列出力を分かりやすくしてくれる属性
enum Pon : long
{
Gu = 1 << Janken.Gu,
Choki = 1 << Janken.Choki,
Pa = 1 << Janken.Pa,
Pistol = Choki | Pa,
}
void Main()
{
// じゃんけん・・・
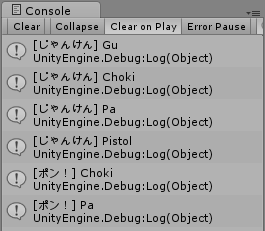
Console.WriteLine($"[じゃんけん] {Pon.Gu}");
Console.WriteLine($"[じゃんけん] {Pon.Choki}");
Console.WriteLine($"[じゃんけん] {Pon.Pa}");
Console.WriteLine($"[じゃんけん] {(Pon.Choki | Pon.Pa)}"); // Flags属性の効果でPistolと表示される
// ポン!
var pon = (long)Pon.Pistol;
if((pon & (long)Pon.Gu) != 0) Console.WriteLine("[ポン!] Gu");
if((pon & (long)Pon.Choki) != 0) Console.WriteLine("[ポン!] Choki");
if((pon & (long)Pon.Pa) != 0) Console.WriteLine("[ポン!] Pa");
}
私見
ピストルは卑怯だろ。。。
Nullable型
値型にnullを追加する。
void Main()
{
// データベースの値はnullが許容されてる場合がある
DateTime? dbTime = null;
DateTime appTime = Parse(dbTime); // アプリの時間にパース
}
DateTime Parse(DateTime? time)
{
// Nullable型にするとHasValueメソッドとValueプロパティを使用可能
return time.HasValue ? time.Value : DateTime.MinValue;
}
私見
- データベースでnullが許容されてる値をそのままパースする
- ライブラリなどカスタマイズ出来ない値型(enumや構造体)に「何もない」という状態を追加する
というところだが、自分はあまり使ってないかも。
??演算子(null合体演算子)
値がnullか判定し、nullでない場合は左側、nullの場合は右側を返す。
class Yusha
{
static Yusha instance = null;
public static Yusha Instance
{
get
{
// これが
instance = instance != null ? instance : new Yusha();
// こう書ける
instance = instance ?? new Yusha();
return instance;
}
}
private Yusha() {}
}
私見
nullなら初期化、nullなら取得、みたいな時によく使う。
可変長引数(params)
メソッド引数を可変にする。
void Main()
{
// 動的に引数の数を変えられる!
Create("て");
Create("て", "ん");
Create("て", "ん", "ぷ");
Create("て", "ん", "ぷ", "ら");
// ちなみに普段よく使う string.Format もこの仕組みを利用している
string.Format("{0}", "て");
string.Format("{0}{1}", "て", "ん");
string.Format("{0}{1}{2}", "て", "ん", "ぷ");
string.Format("{0}{1}{2}{3}", "て", "ん", "ぷ", "ら");
}
void Create(params string[] names) {}
特徴
- コードが短くなる(無駄な定義が減る)
- 内部的には配列に展開される(コストがかかる)
私見
見た目スッキリするが、その実よく知らないうちにnewされてることに注意。頻繁に通るような処理では使用を控えた方がいい。
(ちなみに string.Format は頻繁に使用するが、これについては実はコストを下げる工夫がなされている。興味がある人は string.Format の指定する引数の数をサンプルのように変化させてみて)
オプション引数と名前付き引数
メソッド引数に規定値を設定でき、引数を省略出来る。
void Main()
{
// オプション引数 -> 引数は必ず左から設定していく
Pos(1); // x=1, y=0, z=0
// 名前付き引数 -> 名前を指定するので左からじゃなくても良い
Pos(y:1, z:2); // x=0, y=1, z=2
}
void Pos(int x = 0, int y = 0, int z = 0) {}
私見
オプション引数はよく使う。名前付き引数は自分は使わない。
名前付き引数も便利なのだけど、引数名を変更すると呼び出し側も変更しないといけない。名前の変更が自分にとっては結構ハードルが高い感じ(あくまで好みだが)。
注意点として、規定値はconst同様コンパイル時に値が埋め込まれる。なので外部参照を受ける場合は危険。ただ普段の業務でそこまで厳密に問われる場面は少なく、オプション引数を使えないデメリットの方が勝るので使用している。
defaultキーワード
変数の基底値を取得可能。
void Main()
{
var id = default(int); // 0
var name = default(string); // null
var user = default(User); // null
var pos = default(Vector2); // Vector2(X=0, Y=0)
var obj = Create<bool>(); // false
var str = Get(1); // "1:0_0"
}
class User {}
struct Vector2
{
public float X;
public float Y;
}
T Create<T>()
{
// ジェネリックの規定値(型が定まってない)
return default(T);
}
// オプション引数に構造体を指定
string Get(int id, Vector2 pos = default(Vector2))
{
return $"{id}:{pos.X}_{pos.Y}";
}
私見
普段はあまり使う機会がないが、オプション引数に構造体を指定したい時にたまに使う。
引数の参照渡し(ref、out)
C#のメソッド引数は基本的に値渡しになる。メソッド内で値を変えても呼び出し元には影響しない。
ref out キーワードを使用することで、参照渡しを行うことが出来る。
class Yusha {}
class Monster {}
class Demo
{
void Main()
{
Yusha yusha = null; // refは渡す前に初期化されてる必要がある
Monster monster;
bool success = Create(ref yusha, out monster);
// yusha と monster に値が入力された状態になっている
}
bool Create(ref Yusha yusha, out Monster monster)
{
// outはメソッド内で必ず値を代入しなければならない(なので初期化)
monster = null;
try
{
yusha = new Yusha();
monster = new Monster();
return true;
}
catch
{
return false;
}
}
}
私見
- ref -> 保持している変数の値を変えたい
- out -> メソッドに複数の戻り値をもたせたい
名前空間(namespace)
フォルダ分けに似た仕組み。クラス名の重複を避けられる。
namespace Tempura.Yusha
{
// Partyクラス名が重複してるが名前空間が違うのでエラーにならない
class Party {}
}
namespace Tempura.Monster
{
// Partyクラス名が重複してるが名前空間が違うのでエラーにならない
class Party {}
}
// 名前空間を指定してPartyクラスを使用する
namespace Tempura
{
public class Demo
{
void Main()
{
var yushaParty = new Yusha.Party();
var monsterParty = new Monster.Party();
}
}
}
// using宣言でPartyクラスを使用する
namespace Tempura
{
using Yusha;
public class Demo
{
void Main()
{
// 名前空間の記述を省略出来る
var party = new Party();
}
}
}
私見
自分は以下のルールで使用している。
- 大規模プロジェクトやライブラリ作成などではnamespaceを細かく切る(サンプルだとTempura.Yusha、Tempura.Monster)
- 普段はnamespaceを1つだけ切る(サンプルでいえばTempuraだけ)
名前空間を切りすぎると、毎回名前空間の指定(もしくはusing宣言)が必要で面倒。普段の開発でそこまでの必要性を感じない。
ただ、大規模プロジェクトだと関わる人が多くなるので、クラス名重複を避けるために切る。また、ライブラリは自分以外の誰かが使うものなので、ライブラリ利用者が困らないように切る。
クラス、構造体、インターフェイス
// インターフェイス
interface ISavable
{
void Save();
}
// クラス
class Chara
{
public int Id { get; private set; }
public Chara()
{
Id = -1;
}
public Chara(int id)
{
Id = id;
}
}
class Yusha : Chara, ISavable
{
public Yusha(int id) : base(id) {}
public void Save() {}
}
class Monster : Chara, ISavable
{
public Monster(int id) : base(id) {}
public void Save() {}
}
// 構造体
struct Vector2 : ISavable // クラス継承不可
{
float x; // x = 1 のような宣言時初期化不可
float y;
public float X { get { return x; } set { x = value; } }
public float Y { get { return y; } set { y = value; } }
// public Vector2() {} // 引数なしコンストラクタ定義不可
public Vector2(float x, float y)
{
this.x = x;
this.y = y;
}
public void Save() {}
}
私見
クラスは参照型で構造体は値型。どう使い分けるかだが、自分はほとんどクラスを使用している。
構造体はクラスに比べて制限が多いのと、値型なので値の代入時にコピーが発生する。自分はパフォーマンスを余程気にする場面でしか構造体を使用していない。
インターフェイスも自分は使用頻度低め。様々なオブジェクトで同じように扱われる規約を定める時に使用を検討する(しかし結果クラスにすることが多い)。
プロパティ、インデクサー
プロパティはクラス外部から見るとメンバ変数のように振る舞い、クラス内部から見るとメソッドのように振舞うもの。
インデクサーはプロパティと似てるが、パラメータを受け取る事ができ、配列のように振る舞う。
class Monster
{
int id;
// プロパティ
public int Id
{
get
{
// 取得時の処理(必ず値を返す必要あり)
return id;
}
set
{
// 設定時の処理(valueが設定値)
if(id <= 0) throw new Exception("IDは1以上");
id = value;
}
}
// 自動プロパティ(中身を省略出来る)
public string Name { get; set; }
}
class MonsterParty
{
Monster[] monsters;
// インデクサー
public Monster this[int idx] // 引数指定可能
{
get
{
if(idx < 0 || idx >= monsters.Length) throw new ArgumentOutOfRangeException();
return monsters[idx];
}
set
{
if(idx < 0 || idx >= monsters.Length) throw new ArgumentOutOfRangeException();
monsters[idx] = value;
}
}
public MonsterParty(Monster[] monsters)
{
this.monsters = monsters;
}
}
class Demo
{
void Main()
{
// モンスター作成
var monsters = new Monster[2];
for (int i = 0; i < monsters.Length; i++)
{
var monster = new Monster();
// パラメータ設定
monster.Id = i + 1; // プロパティ使用(変数のよう)
monster.Name = "Unnamed Monster"; // プロパティ使用(変数のよう)
monsters[i] = monster;
}
{
// パーティ作成
var party = new MonsterParty(monsters);
// パーティの先頭モンスターを取得
var monster = party[0]; // インデクサー使用(配列のよう)
}
}
}
私見
オブジェクト指向ではメンバ変数をpublicにはせず、メソッドを介して隠蔽する仕組みが使用される。C#ではそれを機能としてサポートしている。
使ってみれば実感出来るが、たったこれだけで恐ろしいほどコードが綺麗になる。
インデクサーは、サンプルのようにそのオブジェクトがそのまま配列のように振舞ってほしい時に使うと便利(直感的なコードになる)。
演算子のオーバーロード
+ - ==などの演算子をオーバーロードして独自処理を実装出来る。
struct Vector2
{
public float X { get; set; }
public float Y { get; set; }
public Vector2(float x, float y)
{
X = x;
Y = y;
}
// +演算子をオーバーロード
public static Vector2 operator +(Vector2 a, Vector2 b)
{
return new Vector2(a.X + b.X, a.Y + b.Y);
}
// -演算子をオーバーロード
public static Vector2 operator -(Vector2 a, Vector2 b)
{
return new Vector2(a.X - b.X, a.Y - b.Y);
}
}
class Demo
{
void Main()
{
Vector2 from = new Vector2(3, 3);
Vector2 to = new Vector2(10, 10);
// 構造体同士の足し算引き算(演算子のオーバーロードで実現)
Vector2 add = to + from; // Vector2(13, 13)
Vector2 sub = to - from; // Vector2(7, 7)
// DateTimeは演算子のオーバーロードが使われてる
DateTime old = DateTime.Now.AddDays(-1);
DateTime now = DateTime.Now;
TimeSpan span = now - old; // DateTimeからTimeSpanが生まれてる(-演算子のオーバーロード)
}
}
私見
上手く使えばより直感的なコードが書ける。ただ、演算子本来の挙動を変更するので注意が必要。
よほど直観的に分かるもの以外は使用を控えた方がいい(乱用禁止)。
ジェネリック
型だけ違って処理の内容が同じようなものを作るときに使う。
class Chara
{
public int Id { get; set; }
public string Name { get; set; }
}
class Yusha : Chara
{
public string Skill { get; set; }
}
class Monster : Chara
{
public int AI { get; set; }
}
class Demo
{
void Main()
{
// ジェネリックでキャラの共通部分を作成
var yusha = Create<Yusha>(1, "Arus");
var monster = Create<Monster>(2, "Unnamed Monster");
// 固有パラメータを設定
yusha.Skill = "MEZORAGON";
monster.AI = 1;
}
// ジェネリックメソッド
public T Create<T>(int id, string name) where T : Chara // whereで制約条件付けられる
{
var chara = new Chara();
chara.Id = id;
chara.Name = name;
return (T)chara;
}
}
私見
一般的な用途はコレクションクラス(ListやDictionary)。
独自で定義する場合は汎用性が高い処理に使用すると効果大。
コレクション
ジェネリックはコレクションでよく使う。それでは、どのようなものがあるか紹介。
// List -> 配列を可変にしたい場合
var list = new List<int>() { 1, 2, 3 };
int value = list[2]; // 順番通りに入ってる(インデックスでアクセス可能)
// Dictionary -> キーで管理したい場合
var dic = new Dictionary<int, string>() { { 1, "a" }, { 2, "b" }, { 3, "c" } };
if (dic.ContainsKey(2)) // キーで検索出来る
{
string value = dic[2];
}
// SortedList/SortedDictionary -> キーでソートされる。ID管理はこれが便利
var sortList = new SortedList<int, string>() { { 2, "b" }, { 1, "a" }, { 3, "c" } };
var sortDic = new SortedDictionary<int, string>() { { 3, "c" }, { 2, "b" }, { 1, "a" } };
var value0 = sortList[2]; // b
var value1 = sortDic[2]; // b
// Stack/Queue -> 要素の出し入れが楽。アンドゥ、リドゥとか。
var stack = new Stack<int>(); // 後入れ先出し(本を積んでいって【上】から取る)
stack.Push(1);
stack.Push(2);
stack.Push(3);
foreach(int value in stack)
{
// 3
// 2
// 1
}
var queue = new Queue<int>(); // 先入れ先出し(本を積んでいって【下】から取る)
queue.Enqueue(1);
queue.Enqueue(2);
queue.Enqueue(3);
foreach (int value in queue)
{
// 1
// 2
// 3
}
// LinkedList -> Listよりも追加/削除が速い
var link = new LinkedList<int>();
link.AddLast(1);
link.AddLast(2);
link.AddLast(3);
foreach (int value in link) // インデックスアクセス出来ない
{
}
// HashSet/SortedSet -> キー管理のみ、重複時に例外が吐かれない。SortedSetはソートされる
var hashSet = new HashSet<int>() { 2, 1, 3 };
var sortSet = new SortedSet<int>() { 2, 1, 3 };
foreach (var value in hashSet)
{
// 2
// 1
// 3
}
foreach (var value in sortSet)
{
// 1
// 2
// 3
}
| メリット | デメリット | 私見 | |
|---|---|---|---|
| List | 順番保持 | 検索速くない | よく使う |
| Dictionary | キーアクセス | 順番非保障 | よく使う |
| SortedList | ソートされる | ソートコスト | ソートしたい時使う |
| SortedDictionary | ソートされる | ソートコスト | ソートしたい時使う |
| Stack | 出し入れ得意 | 保存順が特殊 | たまに使う |
| Queue | 出し入れ得意 | 保存順が特殊 | たまに使う |
| LinkedList | 追加/削除速い | インデックスアクセス出来ない | あまり使わない |
| HashSet | キー管理のみ行える | 重複時に例外が吐かれない | 使ったことない |
| SortedSet | キー管理のみ行える | 重複時に例外が吐かれない | 使ったことない |
デリゲート
メソッドへの参照を表す型。
class Dialog
{
// デリゲート宣言
public delegate void OnClick();
// デリゲート定義
OnClick onClick;
public Dialog(OnClick onClick)
{
this.onClick = onClick;
}
public void Click()
{
// クリックされたのでコールバックを呼ぶ(Demoクラスのメソッドが呼ばれる)
onClick();
}
}
class Demo
{
void Main()
{
// Demoクラスのメソッドを渡す
var dialog = new Dialog(OnClickDialog);
}
void OnClickDialog()
{
Console.WriteLine("Click Dialog");
}
}
私見
〜がクリックされたら、〜が成功したら、〜が終了したら、みたいなコールバックメソッドによく使う。
デリゲートの概念自体は大事。ただ実際には Action(Func)+ラムダ式 での利用が多い。
Action(Func) + ラムダ式
先ほどのデリゲート記述は面倒。なのでC#にはデフォルトで定義されている Action Func というデリゲートがある(Action → 戻り値なし、Func → 戻り値あり)。
そして、ラムダ式という匿名関数を利用することで、デリゲートが使いやすくなる。
class Demo
{
void Main()
{
// ラムダ式で作ったメソッドを渡す
var dialog = new Dialog(() => Console.WriteLine("Click Dialog"));
}
}
class Dialog
{
// デリゲート定義
Action onClick;
public Dialog(Action onClick)
{
this.onClick = onClick;
}
public void Click()
{
// クリックされたのでコールバック呼ぶ(Demoクラスのメソッドが呼ばれる)
onClick();
}
}
私見
デリゲートはこの使い方が多い。
ラムダ式は、最初は取っつきづらい印象があるかもしれないけど、慣れると無駄な記述を減らせるのでとても便利。
リソースの破棄
C#には使い終わったら自動でリソース破棄を行ってくれる機能がある。
class Demo
{
void Main()
{
// これが
FileStream fs = null;
StreamReader sr = null;
try
{
fs = File.OpenWrite("file.txt");
sr = new StreamReader(fs, Encoding.UTF8);
sr.ReadLine();
}
finally
{
if(fs != null) fs.Dispose();
if(sr != null) sr.Dispose();
}
// こう書ける
using (var fs = File.OpenWrite("file.txt"))
using (var sr = new StreamReader(fs, Encoding.UTF8))
{
sr.ReadLine();
}
}
}
私見
便利!
拡張メソッド
静的メソッドをインスタンスメソッドのように呼び出せる機能。
// 拡張メソッドは静的クラスにしか定義出来ない
public static class Extensions
{
static readonly Random Rand = new Random();
/// <summary>
/// ランダム要素を取得する拡張メソッド
/// </summary>
/// <param name="source">ソース</param>
/// <returns>ランダム要素</returns>
public static T Random<T>(this IEnumerable<T> source)
{
int idx = Rand.Next(0, source.Count());
return source.ElementAtOrDefault(idx);
}
}
class Demo
{
void Main()
{
// 配列からランダム要素取得(配列にRandomという新しいメソッドが追加されたように見える)
var nums = new[] { 1, 2, 3, 4, 5 };
var num = nums.Random();
var strs = new[] { "て", "ん", "ぷ", "ら" };
var str = strs.Random();
var dates = new[] { DateTime.Today.AddDays(-1), DateTime.Today, DateTime.Today.AddDays(1) };
var date = dates.Random();
}
}
私見
- ライブラリなどカスタマイズ出来ないクラスに後からメソッドを追加出来る
- こんなことも出来たり -> C#でenumをクラスのように扱う
- 主にLinqのようなパイプライン処理に使われる
実態はただの静的メソッドなので、乱用すると定義元が分かりづらくなるので注意。
属性
クラスやメンバに追加情報を加える。属性は自作することも可能。
# define DEBUG
//#define RELEASE
static class Debug
{
// 特定のシンボルが定義されてる場合だけ有効になる属性(DEBUG時だけログ出力)
[Conditional("DEBUG")]
public static void Log(string log)
{
Console.WriteLine(log);
}
}
class Demo
{
void Main()
{
// DEBUG時しかログは出力されない
Debug.Log("I'm tempura.");
}
}
私見
自分は大抵すでに定義済みの属性しか使用していない。たまにリフレクションが必要な用途で自作したり(属性情報はリフレクションで取得可能)。
プリプロセス
#で始まるコンパイラへの特別命令。
// #define -> シンボル定義
# define DEBUG
//#define RELEASE
public static class Util
{
// #region -> 畳める!
#region コモン
// #if -> シンボルで条件判定(条件を満たさない場合コンパイル時にコード自体消える)
#if DEBUG
public static void Log(string log)
{
Console.WriteLine(log);
}
#endif
#endregion
#region 拡張メソッド
static readonly Random Rand = new Random();
public static T Random<T>(this IEnumerable<T> source)
{
int idx = Rand.Next(0, source.Count());
return source.ElementAtOrDefault(idx);
}
#endregion
}
私見
#region #ifをよく使う。
#regionは畳めるので便利だが、「畳める=コードが多い」ということなので、そういう場合はコードの分割を検討すべき。
#ifはコード自体を消したい(変えたい)場合だけ使う。普通に条件判定したいならif文でいいわけだし、#ifはネストが増えてくると悲惨。
System.IO
よく使うIO。
void Main()
{
// ファイル操作
File.Exists(path); // File -> ファイル操作(簡略)
FileInfo fi = new FileInfo(path); // FileInfo -> ファイル操作(詳細)
// ディレクトリ操作
Directory.CreateDirectory(path); // Directory -> ディレクトリ操作(簡略)
DirectoryInfo di = new DirectoryInfo(path); // DirectoryInfo -> ディレクトリ操作(詳細)
// パス操作
Path.Combine("path0", "path1"); // path0/path1
Path.GetExtension("image.png"); // .png
// ファイル読み書き(簡略)
File.ReadAllBytes(path);
File.ReadAllText(path, Encoding.UTF8);
File.WriteAllBytes(path, bytes);
File.WriteAllText(path, text, Encoding.UTF8);
// ファイル読み書き(詳細)
using (var fs = File.OpenWrite(path))
using (var sr = new StreamReader(fs, Encoding.UTF8))
using (var sw = new StreamWriter(fs, Encoding.UTF8))
using (var br = new BinaryReader(fs, Encoding.UTF8))
using (var bw = new BinaryWriter(fs, Encoding.UTF8))
{
sr.Read(); // [読み] 1文字
sr.ReadLine(); // [読み] 1行
sw.Write("a"); // [書き] 文字列
sw.WriteLine("b"); // [書き] 文字列+改行
br.ReadInt32(); // [読み] int
br.ReadString(); // [読み] string
bw.Write(3); // [書き] int
bw.Write("c"); // [書き] string
}
}
私見
処理が少ない場合は簡略、複雑になりそうな場合は詳細、をよく使う。
とてもよく出来たライブラリだと思う。
LINQ
C#でデータベース言語のような操作が可能になる。
C#における最強機能。LINQなしにC#開発はありえない。
class Monster
{
public int Id { get; set; }
public int Hp { get; set; }
public bool IsAlive { get; set; }
}
class Demo
{
void Main()
{
var monsters = new Monster[5];
for (int i = 0; i < monsters.Length; i++)
{
monsters[i] = new Monster()
{
Id = i + 1,
Hp = 100,
IsAlive = i % 2 == 0,
};
}
var bosses = new[]
{
new Monster()
{
Id = 101,
Hp = 200,
IsAlive = true,
},
};
// Where -> 条件を満たすものを抽出
foreach (var monster in monsters.Where(m => m.Id >= 3))
{
// monster.Id = 3
// monster.Id = 4
// monster.Id = 5
}
// Select -> 射影
foreach (string id in monsters.Where(m => m.Id >= 3).Select(m => m.Id.ToString()))
{
// id = "3"
// id = "4"
// id = "5"
}
// First -> 最初の要素(ない場合は例外)
// FirstOrDefault -> 最初の要素(ない場合は規定値)
var monster1 = monsters.First(m => m.Id >= 3);
var monster2 = monsters.FirstOrDefault(m => m.Id < 0);
// monster1.Id = 3
// monster2 = null
// Last -> 最後の要素(ない場合は例外)
// LastOrDefault -> 最後の要素(ない場合は規定値)
var monster1 = monsters.Last(m => m.Id >= 3);
var monster2 = monsters.LastOrDefault(m => m.Id < 0);
// monster1.Id = 5
// monster2 = null
// Max -> 最大値
// Min -> 最小値
// Sum -> 合計
int maxId = monsters.Max(m => m.Id);
int minId = monsters.Min(m => m.Id);
int sumHp = monsters.Sum(m => m.Hp);
// maxId = 5
// minId = 1
// sumHp = 500
// Contains -> 含むか
if (monsters.Contains(bosses[0])) {}
// All -> 条件を全て満たすか
if (monsters.All(m => !m.IsAlive)) {}
// Any -> 条件を1つでも満たすか
if (monsters.Any(m => m.IsAlive)) {}
// Count -> 数
int count = monsters.Count();
// OrderBy -> 並び替え:昇順
// OrderByDescending -> 並び替え:降順
foreach (var monster in monsters.Where(m => m.Id <= 3).OrderBy(m => m.Id))
{
// monster.Id = 1
// monster.Id = 2
// monster.Id = 3
}
foreach (var monster in monsters.Where(m => m.Id <= 3).OrderByDescending(m => m.Id))
{
// monster.Id = 3
// monster.Id = 2
// monster.Id = 1
}
// Aggregate -> 値のシーケンスの計算
var ids = monsters.Select(m => m.Id.ToString());
var str = ids.Aggregate((a, b) => $"{a},{b}");
// str = "1,2,3,4,5"
// Concat -> 結合
foreach (var monster in monsters.Where(m => m.Id >= 3).Concat(bosses))
{
// monster.Id = 3
// monster.Id = 4
// monster.Id = 5
// monster.Id = 101
}
// ToArray -> 配列変換
// ToList -> List変換
// ToDictionary -> Dictionary変換
List<Monster> list = monsters.ToList();
Monster[] array = list.ToArray();
Dictionary<int, Monster> dic = array.ToDictionary(m => m.Id, m => m);
}
}
私見
LINQを導入することで、今まで何十行と書いていたコードが1行で書けたりする。
初めはループ処理を記述するところでLINQが使えないかと考える癖をつけると幸せになれる。
LINQまじ便利!
参考
C# プログラミング ガイド
C# リファレンス
C# によるプログラミング入門
smdn:総武ソフトウェア推進所/.NET Framework