背景
Rustという言語がとても気になっていた。
まだ登場してから長くない言語なのに、Oracleのコンテナランタイム環境として採用されたり、MicrosoftがC++の後継として採用したりと、主要企業が続々と取り入れている。
いったい何が魅力的なのかと思い、軽く調べてみたところ、どうやら多くのメリットがあるらしい。
所有権やら借用やら聞きなれない言葉で溢れており、かなり難しそうなイメージだったRustだが、そのメリットを理解したいと思い、何かしらのツールを実装しながら習得しようと思った。
「Cコンパイラ」を選んだ理由は難しすぎず、簡単すぎずで丁度良いと思ったから。
作成したコード
仕様
input
C言語で書かれたファイル。
output
inputのC言語ファイルをMIPSアセンブリ言語に変換したファイル。
できること
- main関数内の処理記述(引数なし、返り値はvoidとint)
- int型の変数宣言
- for文
- while文
- if・else文
- 四則演算
- return
- コンパイルエラーメッセージ(エラー箇所含め)出力
実装
概要
下記のような手順で実装する。
字句解析 ⇒ 構文解析(構文木生成) ⇒ 意味解析、コード生成
lex.rs(字句解析)
字句解析とは
コンパイラの入り口。
プログラムの文字列を、意味のあるトークン(字句)に分割する処理。
日本語で説明すると、「私は元気です。」という文であれば、「私」、「は」、「元気」、「です」に分割されるようなイメージ。
プログラミングでは、「int abc;」という文の場合、「int」、「abc」、「;」に分割される。
ちなみに、この段階でエラーとして弾くことができるコードは、「1-2_3.abc」のように、字句のまとまりとして存在しえない文字列が記載されているコードである。
実装のPoint!
Rustでは、nomというライブラリが使えた。
字句解析をするのにベストなライブラリだった。
下記のように、宣言し、nomライブラリを使用する。
use lex::nom::{
Err,
IResult,
error::ErrorKind,
bytes::complete::{tag, take_until},
character::complete::{multispace0, digit1, alpha1, alphanumeric0, one_of},
branch::alt,
combinator::rest_len
};
トークンについては、enumを用意し、呼び出し元にはenumの配列を返すようにした。
pub enum Token {
Variable(String),
Figure(String),
Arithmetic(String),
Comparison(String),
Type(String),
VOID,
WHILE,
FOR,
IF,
ELSE,
EQ,
L_P,
R_P,
L_CB,
R_CB,
L_SB,
R_SB,
COMMA,
SEMICOL,
RETURN,
None
}
Varible(String)とか、Figure(String)とか、ちょっと見慣れないenumの要素がある。
これについては後述する。
とにかく、Variable(String)は英数字の文字列、Figure(String)は数列を表しており、「意味のまとまり」である。
そして、下記にnomライブラリを使った実装の一部を記載する。
fn get_word(input: &str) -> IResult<&str, Token> {
let token:Token;
let (input, first) = alt((tag("_"), alpha1))(input)?;
let (input, after) = alphanumeric0(input)?;
let word:&str = &(first.to_string() + after);
match word {
"int" => token = Token::Type(String::from("int")),
"char" => token = Token::Type(String::from("char")),
"void" => token = Token::VOID,
"while" => token = Token::WHILE,
"for" => token = Token::FOR,
"if" => token = Token::IF,
"else" => token = Token::ELSE,
"return" => token = Token::RETURN,
_ => token = Token::Variable(word.to_string())
}
Ok((input, token))
}
上記の関数は、int、ifなどの予約語や、変数名・関数名になるであろう英数字の文字列を解析する関数である。
alt()やalphanumeric0()などがnomライブラリの関数である。
一般的な形式として、関数を実行すると、(var1, var2)のようなタプル型が返ってくる。
例えば3行目のalt((tag("_"), alpha1))(input)?;は、引数inputで与えられた文字列の先頭の1文字が_(アンダーバー)か、アルファベットかを判定している。
条件にマッチした場合は、タプルの1つ目の変数にマッチした箇所以降の文字列、2つ目の変数にマッチした文字列が入る。
このような形式のおかげで空白の除去や、改行の除去、英数字の文字列と数列の分類などが簡単にできる。
そして、先ほど宣言したenumに従い、Token::〇〇のようにしてトークン化している。
ここで、Token::Type(〇〇)やToken::Variable(〇〇)のような記述がある。
これが非常に便利で、Rustでは、enumに任意の型の値を付属させることができる。
このおかげで、「int a;」をただ「int」、「a」、「;」に分けるのでなく、「Type("int")」(型の"int")、「Variable("a")」(英数字列のa)、「;」に分けることができる。
後の構文解析がやりやすくなる。
parse.rs(構文解析)
構文解析とは
字句解析で生成されたトークン列をもとに、構文木を生成する。
下図のようなイメージをしてもらえば分かりやすい。
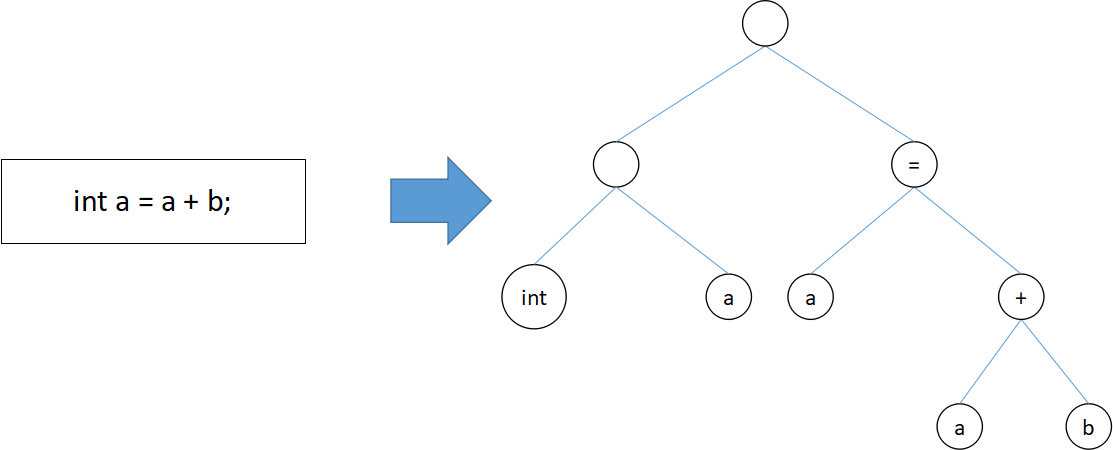
プログラム全体を木構造として表し、意味のまとまりを階層的に表すことができる。
これがコード生成の前準備として必要な手順である。
ちなみに、この段階でエラーとして弾くことができるコードは、「int 3;」のように、文法的に誤っている部分が存在するコードである。
実装のPoint!
下記のようなenumを用意する。
pub enum Node {
Number(i32, ErrorInfo),
Variable(String, ErrorInfo),
FuncName(String, ErrorInfo),
Type(String, ErrorInfo),
Branch {
left: Option<Box<Node>>,
right: Option<Box<Node>>,
branch: (String, ErrorInfo)
},
StatusNode(ErrorInfo),
None
}
葉ノードとして、「数字」、「変数名」、「関数名」などを定義しており、内部ノードとして、左右に子ノードを持つBranchを定義している。
最初は、Token列として渡された配列をそのまま一つずつノード化し、解析&結合を繰り返すことによって、最終的に一つの木になる。
トークン列やノード列を走査するために実装した関数について下記に記載する。
fn is_match(&mut self, comp:Vec<&str>) -> bool {
self.back();
let mut iter = comp.iter();
while let Some(x) = self.next() {
match iter.next() {
Some(y) if y.to_string() == x.status => {},
None => {return true;},
_ => {return false;}
}
}
if let None = iter.next() {return true}
else {return false}
}
impl Iterator for ParseNodes {
type Item = ParseNode;
fn next(&mut self) -> Option<ParseNode> {
if self.end < self.nodes.len() {
let node = self.nodes[self.end].clone();
self.end += 1;
Some(node)
} else {
self.end += 1;
None
}
}
}
is_matchの引数に、マッチしているかどうかを走査したい文字列の配列を与える。
マッチしているときにtrue、していない場合にfalseが返ってくる。
ここで、Iteratorトレイトなるものを実装している。
「トレイト」とは、従来のオブジェクト指向言語でいう「インタフェース」に近い。
文字列の配列を走査するうえで、マッチしていたらマッチ後の文字列の次の要素に、マッチしていなかったらマッチ判定前の要素に、現在位置を設定したかったため、トレイトを実装した。
例えば乗算、除算の式を構文木に変換する場合、上記のis_match()を使用し、下記のように記述する。
fn to_mulexp(&mut self) -> bool {
if self.is_match(vec!["MULEXP", "MULTIORDIV", "PRIMARY"]){
if let Node::Branch{branch: (x, _), ..} = self.fetch_parse_node_by_index(1).node {
let node = self.make_node(NodeOrIndex::index(0), NodeOrIndex::index(2), &*x, "MULEXP");
self.overwrite_nodes(node, 0, 0);
}
true
}else if self.is_match(vec!["PRIMARY"]){
self.overwrite_node_status(0, "MULEXP");
true
} else {
false
}
}
- MULEXP : 乗算・除算の式、または()で囲まれた式、または数値
- MULTIORDIV : * または、/ または、%
- PRIMARY : ()で囲まれた式、または数値
ノード列が、MULEXP MULTIORDIV PRIMARY の並びになっていた場合、左の子ノードを「MULEXP」、右の子ノードを「PRIMARY」とし、新たに「MULEXP」という親ノードを作成する。
このような関数をパターンの数だけ作成する。
つぶやき
parse.rsについては、綺麗に書けた自信がない。
というかとても汚いコードに仕上がったな、と自分自身では思った。
BNF記法をそのまま理解してくれる「yacc」のようなライブラリが、見つけられなかった。
いや、C言語と連携できるみたいなので、「yacc」ライブラリも使えたかもしれないが、今回はそこまで踏み込まなかった。
こういうのってどういう風に実装するのが良いのだろうか?
私レベルのエンジニアには分からない。
make_code.rs(意味解析、コード生成)
意味解析とは
構文解析で生成した構文木を探索しながら、プログラムの意味として正しいかどうかを解析する。
例えば、宣言、または初期化されていない変数が、突然式で出てきたら、当然ながらCコンパイラはエラーを吐かなければならない。
これまでの段階で、文法として誤っているコードは弾かれている。
この段階では、プログラムの意味として誤っているコードを弾くことができる。
コード生成について
意味解析と並行に行っていくので、流れとしては同様に、構文木を探索しながらコードを生成する。
探索については、根ノード⇒左の子ノード⇒更に左の子ノード という風に見ていくわけだが、各ノードについて、
- 一番最初に見たら探索するのか?(前置)
- 左の子ノードの探索が全て終了したら探索するのか?(中間)
- 全ての子ノードの探索が終了したら探索するのか?(後置)
を気にする必要がある。
例えば下図では、後置順で探索を行っている。
このようにコントロールすることにより、計算や処理を優先順位に従って行う正しいアセンブリ言語に変換することができる。
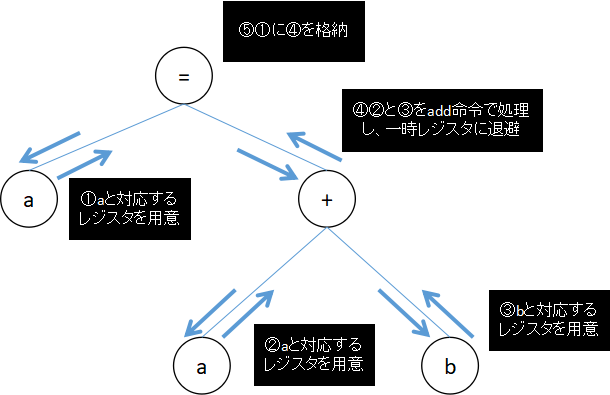
MIPSアセンブリ言語は、レジスタと呼ばれるデータの格納領域と、あらかじめ用意されているadd(加算)、sub(減算)などのいくつかの命令セットから構成される。
例えば上図の場合、下記のようなアセンブリ言語を生成できる。(変数aと対応するレジスタを$a0、変数bと対応するレジスタを$a1とする)
add $t0 $a0 $a1 (4)
mv $a0 $t0 (5)
実装のPoint!
下記が、木を探索する部分である。
fn explore_node(&mut self, node: Node) -> Result<(), ErrorInfo> {
match node {
Node::Branch{left:_left, right:_right, branch:_branch} => {
if let (b, _) = _branch.clone() {
self.analyze_branch_enter(b);
}
if let Some(l) = _left {
self.explore_node(*l)?
}
if let (b, _) = _branch.clone() {
self.analyze_branch_center(b);
}
if let Some(r) = _right {
self.explore_node(*r)?
}
if let (b, err) = _branch.clone() {
self.analyze_branch_leave(b, err)?
}
},
x @ _ => {
self.analyze_leaf(x)?
}
}
return Ok(());
}
引数にノードを与え、再帰的に探索を行う。
- analyze_branch_enter : 前置で処理をするもの
- analyze_branch_center : 中間で処理をするもの
- analyze_branch_leave : 後置で処理をするもの
という風に分け、それぞれの処理を行っている。
Rustのmatch文では、パターンマッチを行うことができる。
どういうことかというと、2~3行目のような記法で、Node::Branch{left: 〇〇, right: △△, branch: ☆☆}のパターンにマッチしているかどうかを判定し、更にその内部で〇〇、△△、☆☆をそのまま使用できる。
複雑なデータ構造のマッチ判定と、データの取得を同時に、簡潔に記載できる。
これがRustでは重宝され、上記のような用途以外でも使われている。
Rustは非常に「安全」を意識した言語であるからだ。
具体的に言うと、返り値に「null値」を返すようなことを許さない。
返り値を、あらかじめ用意しておいたenumで用意した型に包み込む。
先ほど、Rustのenumでは任意の型の値を付属させることができると記述したが、それを用いてRustでは例えば下記のような型を用意している。
- null値でない場合に、Some(値)を返し、null値(とか)の場合に、Noneを返すOption型
- 何かしらのErrorの場合に、Err(エラーに関わる値)を返し、正常の場合に、Ok(値)を返すResult型
このような返り値を判定&取得するときなどにも使われる。
話が逸れた。
あとは、それぞれの関数内で、適当なMIPアセンブリコードを出力ファイルに書き込んでいるだけである。
所感(主にRustについて)
所有権
所有権については一応理解できたつもりでいる。
簡単に言うと、1つの変数のみが値の所有権を持っているため、下記のような記述ができない、ということだ。
let s1 = String::from("hello");
let s2 = s1;
println!("{}, world!", s1);
こうすると何ができるのか、というと(少し飛躍するが)
- C言語みたいな言語の、開発者がメモリを手動で管理することによる、メモリ破壊等のリスクの増加、かつ手動管理のコードの冗長化(めんどくささの増加)
- JavaやPythonなどの言語が動作する環境に備わっているガベージコレクションの負荷の増大
の双方を解決することができる(ということだと思う)。
ヒープ領域にあるデータだから、使わなくなったら解放が必要だよね。みたいなことがなく、スコープを外れたらメモリを解放してくれる。
そしてそれがガベージコレクションの機能下で動いているものではない、ということに純粋にびっくりさせられる。
なぜこれができるのかというと、値を保持する変数が一つしかないので、ヒープ領域に格納された値の終わりを追えるからであると思う。
そもそも、値の責任元が一つの変数のみである、というのが本来あるべき姿だったのではないかと思う。
これまでの言語は責任が分散しすぎて、様々なバグの温床となっていた。
確かに、複数の変数に格納できない、という点は今までの言語を比較したときに、新たに「コーディングの面倒くささ」というデメリットを生んでいるかもしれない。
しかし、そこは「借用」や「clone文」などでどうとでもなるし、安全を最優先にすべきだと考えれば、これが普通の形だったのではないだろうか?
ということで、私的にはこの所有権ルールだけでもRustって革新的な言語だなあという風に感じる。
ライフタイム
上述した「借用」について、これにもかなり厳格なルールがある。
詳しいルールは公式ドキュメントが良いが、例を記載する。
fn test<'a>(x: &'a i32) -> &'a i32 {
let z: i32 = 2;
&z //メモリ破壊
}
fn main() {
let x = 1;
test(&x);
}
上記のコードはRustでは動かない。
同じ処理をC言語で記載すると、
int* test(int* x) {
int z = 2;
return &z; // メモリ破壊
}
int main(void){
int x = 1;
test(&x);
}
これは動く。
では、ただ単にできることを制限して「メモリセーフ」と言っているだけではないか?となるかもしれないが、それは違う。
下記のコードは動くのだ。
fn test<'a>(x: &'a i32) -> &'a i32 {
let z: i32 = 2;
&x // ←←←ここが違う
}
fn main() {
let x = 1;
test(&x);
}
つまり、返却値は全く同じ「借用」の値であるが、メモリセーフな値かどうかによって、コンパイラがエラーを出すかどうかが異なる。
実は「'a」というのが肝になっていて、これがまさに「ライフタイム」を表している。
test関数の引数と返り値に「'a」がついているが、これが借用された値のライフタイムを保証している。
今回の例でいえば、「test関数の返り値は、1つめの引数で与えられた引数のライフタイムと同じですよ~」ということを保証している。
だから、1つ目のRustのコードは、返り値に与えたzという変数が、保証されたライフタイムを守っていないじゃないか!ということになってコンパイルエラーが吐ける。
感動した。
これは確かにメモリセーフだ。(?)
Rustまとめ
私なりに一番大きなところをまとめると、
所有権ルールで、値に対して責任の所在を限定。メモリ管理の楽ちん化&安全化。
⇒所有権を奪わず、値を参照したいときは「借用」をする。
⇒ところかまわず借用できてしまうと、やはり「安全」とはいえない。借用のルールを厳格化(その一つがライフタイム)。
みたいな感じかな~と思った。
その他にも色々細かいところでメリットがあり、
- パターンマッチに強い。
- Option、Result型のようなenumの活用で、安全性・利便性を担保している。(上述)
- オブジェクト指向プログラミングにも強い(クラス・オブジェクトという概念ではないが)。
- ルールに従った安全な記述が推奨されている言語だが、実際やろうと思えばなんでもできる。
などが挙げられる。
今回の開発では、予想通りコンパイルエラーが多発した。
最初は目眩がした。
Rustって何がいいんだ?!って思っていた。
だが実装していて、実行時エラーがほとんどないことに気づいた。
特にメモリを破壊するような危険な動作は全くない。
コンパイルエラーさえ解消してしまえば後はスイスイ動く、みたいなそんな感じで、開発の負担が少ない。
C言語での開発でセグメンテーションエラーに悩まされる時間より遥かに少ない。
てなわけでまとめると、
習得はかなり難しいですが、そのコストの倍以上の恩恵が得られる言語である
と思った。
最後に
私自身、記事は書いてみたものの全く自信がございません。
全く分からない中から独学で勉強しましたが、まだ中級者にすら届いていないレベルだと思います。
めちゃくちゃなことを書いてしまっている可能性もございます。
記事に誤っている内容や、コード中に好ましくない作法等がございましたら、教えていただけると幸いです。