山田です。
スーパーコンピュータポエムAdC、五日目となりました。
昨日のロボ太先生の記事は皆さんご覧になられましたか? まだ見てない方は必読ですよ。
具体的になぜ必読かというと、「スパコンとどう向き合うべきか(二位じゃダメなんですかって言ってもいいのか?)」 というのを理解するのに非常に重要なことが書かれていると思います。
こういうのを読めただけで最高だと思いますねほんとに。あと二十何日か頑張ります…
さて、本日もヌルく、変なアーキテクチャについて語っていきましょう(スパコンは?
Day5 ASTRA

Armのスパコンについて話すとは言ったが、富岳とは言っていない。
ASTRA とは?
アド・アストラって観ました? ブラピがひたすらモノローグする映画。面白いのでぜひ。
というわけで、今回はNov/2020にて#281 となった、Sandia National LaboratoryのASTRAというシステムです。

(引用元: https://vanguard.sandia.gov/astra/)
トップページに燦然と輝く、"World's First Petascale Arm-Based Supercomputer"の文字がアツいですね。
さて、Sandiaは先日ピックアップしたTrinityと同じ、DOEの研究所の一つです。あと、いろいろな面白論文を出すことでも知られています(個人の感想です)
俺の学生時代とか並列計算機の論文をあさってたらSandiaにたどり着いて、またSandiaかみたいになることが多かったですね……
そしてやっぱり側面にはASTRAの文字。かっこいいですね。DOEの伝統なのかしらやっぱり……
ローンチ時のSNLからのプレスリリースはこちら。
https://share-ng.sandia.gov/news/resources/news_releases/arm_supercomputer/
ASTRAのスペック
と、
をソースに見ていきましょう。
表にまとめるとこんな感じ
| Spec | |
|---|---|
| Processor | Cavium Thunder-X2 CN9975 |
| Sockets | 2 |
| Memory Controllers per Socket | 8 |
| Memory Speed | DDR4-2666 |
| Node interface | Mellanox InfiniBand EDR |
まず最初に目を引くのが、ASTRAのCPUはx86ではなく、Armであるということです。
使っているのは、ローンチしたときはCavium、のちにMarvellにチームが買われることとなったThunderX2です。
日本では、さくらインターネットさんの関連会社、プラナスソリューションズさんが、このCPUを使用したインスタンスを提供されています。リリースされたときに少し話題になったので、ご存じの方も多いのではないでしょうか?
CPUについてはあとで深堀するとして、引き続きノードスペックを見ていきましょう。
Socket/Nodeは2.デュアルソケットの端末です。そしてメモリチャネルはソケットあたり8と、Xeonの倍あります。ThunderX2ローンチ当初としてはこれはXeonの倍(理論値ですが) あるということで、memory-intensiveなアプリケーションであればThunderX2を選んだほうがいいのでは? という議論が若干ありました。とはいえ、すぐにx86陣営も追いつきましたが(主にEPYCが。Intelがんばれ。超がんばれ)
メモリ帯域が若干広めなので、実アプリケーション()に近いHPCGにも(相対的に) 強めといえる構造ですね。
ノード間接続はMellanoxのInfiniband EDRを使用。ノード間接続としては高速ですね。Apollo70のブロックダイアグラムが入手できなかったんですが、ソケットあたり1または2のEDRが接続されていると思われます。Top500のサイトによれば4xEDRとか書いてあるので、ソケット2かな? PCIeのレーン数的にもそのあたりの数字が妥当かなと思います。
と考えると、外部帯域は割とリッチな気がします。ノードあたり4のEDRがあるとして、ノードあたりの性能は2.3PFlops/2592 = 890GFlops. 890GFlopsに対して400Gbps = 50GB/sとかなので、Flops比で考えると0.1を超えている…
つまるところ、ノード間通信をそこそこ行うGraph500あたりにも強いアーキテクチャになってると言えるでしょう。メモリ帯域の件も合わせて、HPCG, Graph500と、流行のアプリケーションの要点を押さえた作りになっています。
HPLの理論ピーク性能と実効性能はというと、2.3PFlopsに対して1.83PFlopsなので、約78%。これは結構いい数字といえるのではないでしょうか。
さて、それでは恒例の(?)ThunderX2を深く掘り下げていきましょう。
Marvell(Cavium) ThunderX2
ThunderX2のアーキテクチャWhitepaperがあんま見つからんのよね…
この辺、NVIDIAとかIntelとかはアーキテクチャWhitepaperをちゃんと出してるからマジでえらいと思います(ブーメラン
一応、ThunderX2の公式サイトは
https://www.marvell.com/products/server-processors/thunderx2-arm-processors.html
にありまして、軽い説明が書かれたのは
https://www.marvell.com/content/dam/marvell/en/public-collateral/server-processors/marvell-server-processors-thunderx-cn99xx-product-brief-2019.pdf
にあります。
ASTRAで使われていたプロセッサはCN9975だそうなので、28コアモデルですね。
先述の通り、メモリチャネルは8、PCIeはUp To 56。仮にEDRでx16を2消費しても24レーンは残る計算になります。
どこからその情報を得てるのかマジでわからないですが、Wikichipさんによれば、マイクロアーキテクチャはBroadcomのVulanだそうです。
https://en.wikichip.org/wiki/cavium/microarchitectures/vulcan
ただこれはよくよく考えればその通りで、BroadcomがAvagoに買収されてBroadcomになり(!?) そこからパージされたチームが開発しているわけで、さもありなんというか、業界狭いというか…
Vulcanのチップ内構造は
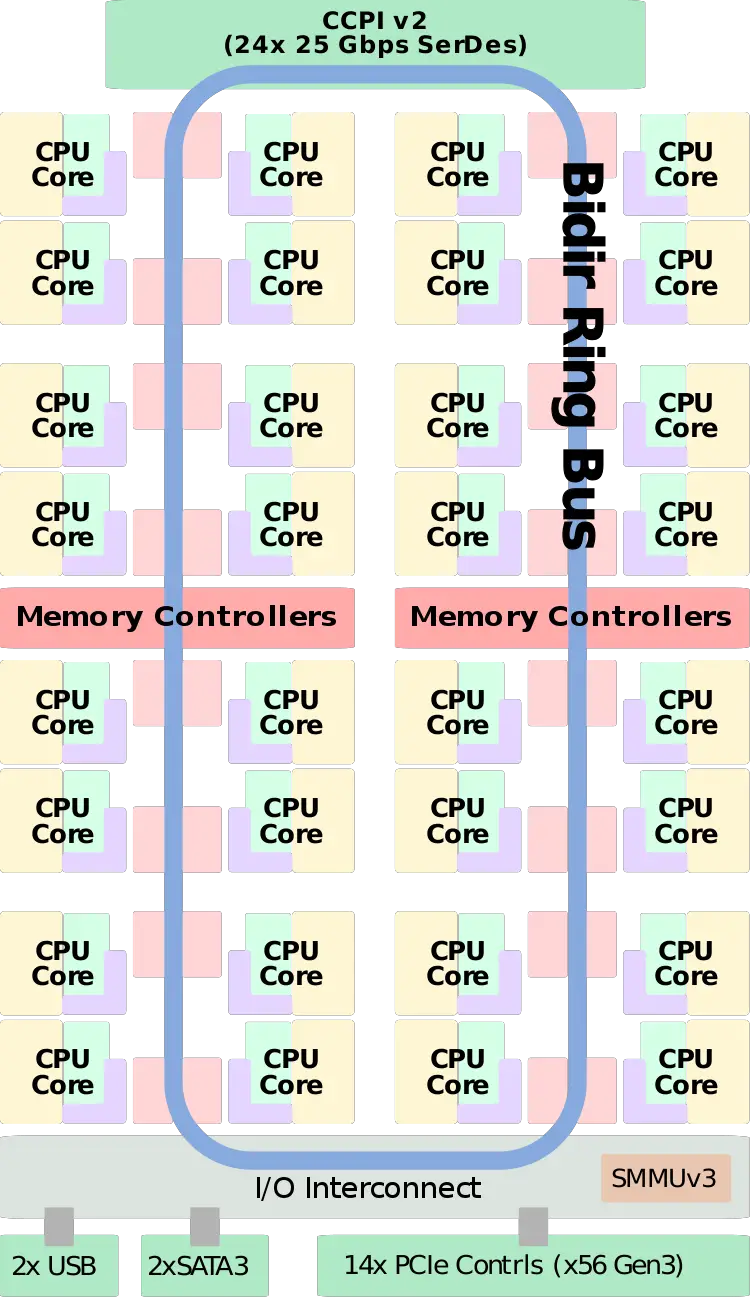
(引用元: https://en.wikichip.org/wiki/cavium/microarchitectures/vulcan)
となっており、各コアがリングバスで接続されているというものです。どっかで見たことある構造ですね。これKNCで見たやつだ…!!!!!!
リングバスはCavium Coherent Processor Interconnect 2(CCPI2) というコヒーレントバスとなっており、75GB/sの速度で駆動している模様です。ほんとか? なんか見間違えてるような気がするぞ…
コア内は
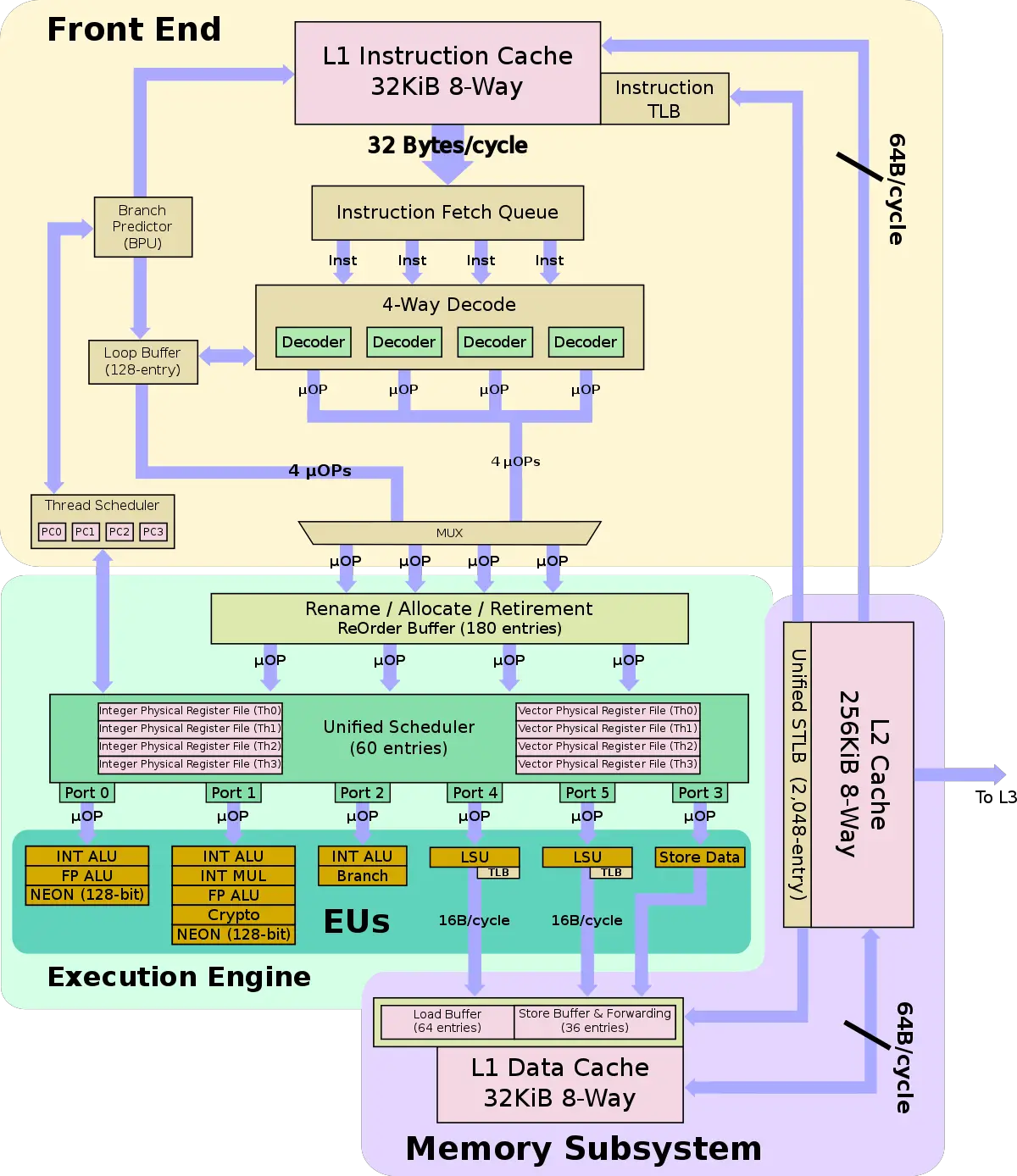
(引用元: https://en.wikichip.org/wiki/cavium/microarchitectures/vulcan)
となっています。
こんなに内部情報出てるのすごいなー(他人事
さて、ThunderX2は4-issueの石になっており、1サイクルに2ロード1ストア出る命令発行ポートになっていますね。これは近代のハイパフォーマンスプロセッサとしてはよくある構成。
SIMD命令セットとしてはNEONを採用しており、それが2ポートから出ます。(NEONといえばNEONひとりアドベントカレンダーが開催中なのでこちらもどうぞ)
FMAが出るので、サイクルあたりの浮動小数点演算数は2(port) * 2(64 * 2 bit) * 2(FMA) = 8 Flop/cycleです。CN9975はコア数が28、クロックが2Gなので、8(Flop/cycle) * 28(core) * 2(clock) = 448GFlops/socketとなります。ノードあたりだとデュアルソケットなので、448(GFlops) * 2(Socket) = 896GFlops/node。ノード数が2592だから合計で2,322,432 = 2.3PFlops。計算合った。よしよし。
問題は、僕はこの石触ったことないということでして…正確に言うと触る機会があったのにちょっといろいろサボってたら逃してしまったというか。えー関係者の皆様には深く謝罪を致します…
ただまぁ、Armだから速いとかそういう感じというより、このチップは、コア内にしろチップ内にしろ、堅実にちゃんと作れば、x86と同等、あるいはそれ以上のマイクロアーキって作れるんだなというのが正直な感想だったりします。まぁ、x86は過去のしがらみにとらわれている(おもにデコーダ回りとか…) という話があったりなかったりするんだろうなぁ…
↑のコアブロック図を見ればわかる通り、デコーダ通り過ぎた後はuOpなんで、近代のプロセッサってもう命令セットってほとんど関係ないんですよねぶっちゃけ。なので、あとはReOrderBufferだとかSchedulerだとかReservationStationだとかが賢いかどうかっていう話になるんで…
となると無論、ソフトウェアスタックどうなってんのというのが議論に上がるところですが、この辺っていうのはSNL、Marvellをはじめとした人々によって
https://www.marvell.com/content/dam/marvell/en/public-collateral/server-processors/marvell-server-processors-thunderx2-energy-oil-and-gas-on-thunderx2-white-paper-2019-06.pdf
とか
https://www.marvell.com/content/dam/marvell/en/public-collateral/server-processors/marvell-server-processors-thunderx2-geosciences-and-climate-on-thunderx2-white-paper-2019-06.pdf
とか
https://www.marvell.com/content/dam/marvell/en/public-collateral/server-processors/marvell-server-processors-thunderx2-manufacturing-applications-on-thunderx2-white-paper-2019-06.pdf
というように、ちゃんとソフトウェアが移植されていたので、あともう少し…あともう少し生き残れれば一気に戦いの土壌に乗れたのではないか…と思わずにはいられません。
ThunderX3
何でいきなりRIPな感じになっているかというと、ThunderX2の後継機であるところのThunderX3ですが、2020年の夏までは
https://www.anandtech.com/show/15995/hot-chips-2020-marvell-details-thunderx3
といって、Hotchipsで発表とかしていたのに、
ARM64 server processor ThunderX3 from Marvell has been cancelled. The team was laid off yesterday.#armserver #DataCenter @CDemerjian @IanCutress @RyanSmithAT @Patrick1Kennedy @PatrickMoorhead
— HardwareInfo (@tpains) October 30, 2020
となってですね、ThunderX3がキャンセルされて、あまつさえチームも解散になってしまったからです。
これだけ素晴らしいチップが作られていたにも関わらず、こんな結果になってしまったことは非常に残念極まりない結果です。やっぱりチップビジネスってのは厳しいんですね……(特大ブーメラン)
「ASTRAはSuper cool」
このセクションは完全に思い出話。
SC17だったかな…?あちこちを放浪していたら、ちょうどこのSNLのブースがあったので、ふらっと寄っていったら、Armのスパコン!とこいつが大々的に広告されていました。
Armでスパコンやるのすごいですね、という話をしていたら、「HPEとCaviumとSNLのスタッフがめっちゃ頑張ったんよ」と広報のおじさんにこにこ。「Super coolなシステムになったからよかったら使ってってな」というアツいArm推しを受けてブースを後にしました。
なお、そのあとCaviumのブースに行ったら「NDA案件だからあとでメールするわ」って言われて放置されたんですけどね。

在りし日のCavium ThunderX2(SC17 Caviumブースにて撮影)
そう思うと、このASTRAというSuper coolなシステムが先行き不透明になってしまった(というわけではないのかも。a64fxあるし) のが、やや残念ではあります。
まとめ
- 初のArmスパコン、ASTRAについて述べました。
- Arm用ハイパフォーマンスチップ、ThunderX2について述べました。
- 触ってないので変なところあったらすいません。もし評価環境をお貸しいただける方いたら貸していただけたらいろいろ動かしてみたい…
- あと触られたご感想とかあったらお聞かせ願えると嬉しいです。
- ThunderX3がキャンセルされたのが悲しいという話をしました。
- 明日も山田の担当(の予定)で、そろそろGPUの話とかします。