山田です。
スーパーコンピュータポエムアドベントカレンダー2020です。
引き続きヌルいのをやっていきます。
Day3 Trinity
三位一体とはまたαにしてΩな名前を…と思わずにはいられないスーパーコンピュータです。
Trinityとは?
Trinityというスーパーコンピュータは、DOEはLANL(ロスアラモス国立研究所) においてあるスーパーコンピュータです。
https://www.hpcwire.jp/archives/4965
DOEというのはアメリカ合衆国エネルギー省のことで、シン・ゴジラにも名前が出てきたことで有名ですね(?
ロスアラモスを筆頭に、ローレンス・バークレー、ローレンス・リバモア、サンディア、オークリッジ等々の名だたるスパコンセンターを抱える国家機関です。お金あるっていいですね。俺も欲しいですお金。
Nov/2020では#13, 最高では#6につけたことがあるスーパーコンピュータです。
外見がかっこいいんですわ。天板に文字書くのはDOEの流行りなのかしら?

(引用元: https://en.wikipedia.org/wiki/Trinity_(supercomputer))
日本でも某所のスパコンでやってた(日本のが先という説もあり) ので、まぁスパコンの天板は不愛想よりはかっこいいほうがいい。京とかね。
LANLはTrinityの完成PVなんかも作っていて
https://www.youtube.com/watch?v=z9eZs2GBn9c
とかあるので、まぁよろしかったらぜひ…(スパコンのPVというので古傷を抉られた人の顔
Trinityのスペック
を参照すると、
CRAY XC40という製品を使用して建造されたスパコンです。CRAY、いいですよね。もはやCRAYって何って感じですけど。買収に次ぐ買収で看板だけが生き残る伝説…まぁ名前が残らないよりは残ったほうがいいです。
ノード数は19420。使っているCPUはIntel Xeon E5-2698v3がなんと301952個。さらにはIntel XeonPhi 7250が678912と、XeonPhiがXeonの倍以上使用されているんですね。これはすごい物量。
総メモリ量は2PBとなっていて、これだけ見ると相当な物量。ノードあたりでラフに換算すると、約108GB程度となります。まぁアバウトな数字ですが、ノードあたりで見ると結構な量持っているので、いろいろと使いやすそうです。あと、たぶんこれはXeonPhiのMCDRAMの数字とかもはいっているので、一概には色々言えないでしょう。
ノード間インターコネクトは、CRAYのAries interconnect。このインターコネクトに関してはあんまり資料がないのですが、なんかアルゴンヌ国立研究所がマニュアルを公開しているのでそちらをご覧ください。
CRAYはインターコネクト自前でちゃんと作っててえらいなって気持ちになります。いや本当に。次なるフロンティアはインターコネクトにありますよ。MellanoxもNVIDIAに買収されたことですし、次のスタンダードを作りにいかねばならないですよ(何の話や
さて、Wikipediaによると
a significant performance increase
を引き起こした主要因であるところの第二世代XeonPhi、開発コードKnightsLandingについて、つらつらと述べたいと思います。
第二世代XeonPhiについて
KNLアーキテクチャ
第二世代XeonPhiは、XeonPhiファミリーの二世代目です(進次郎構文
開発コードをKnightsLanding、通称はKNLです。結構採用数の多かったXeonPhiなので、わりといろいろなところで目にした人もいらっしゃるのではないでしょうか?
https://twitter.com/geno_qcpass/status/1162919170712821760
こういうのとかね。おお哀しい哀しい…
さて、こちらの石の評価ですが、Tianhe-2に搭載されていた第一世代XeonPhiと比べると、随所に改善点が見られます。Intelのこういうステップアップして改善していく姿勢は大変すばらしいと思いますね。
詳細はこれまたPCWatchの後藤さんの記事(https://pc.watch.impress.co.jp/docs/column/kaigai/1006546.html, https://pc.watch.impress.co.jp/docs/column/kaigai/1008665.html) をご覧になるのが最も良いと思いますが、箇条書きで書くと
- コアのマイクロアーキテクチャが
Pentium ProPentium(が正しいです。fujita_d_hさんありがとうございます!) からSilverMontベースに変更された - 命令セットがメインストリームCPUと互換になった(つまりバイナリ互換が得られるようになった)
- SIMD命令がAVX-512となった
- コア間接続がリングバスから2Dメッシュに変更になった
- 外部メモリがDDR4 6ch + MCDRAM 4chになった
といった改良が行われており、着実な改善が見られます。あまりにも堅実すぎて、この形を最初に聞いた時はKNLはしばらく覇権を取れるのでは?と思ってしまったレベル。
ベースとなっているSilvermontアーキテクチャですが、これは当時のAtomのアーキテクチャとして採用されていたものでした。今日でいうとGeminiLakeシリーズとして採用されているGoldmontの先祖です。*mont系の基礎はこのSilvermont世代で築かれたといっても過言ではないでしょう(たぶん
Silvermont系のアーキテクチャについてはこれまた後藤さんの記事ですが
https://pc.watch.impress.co.jp/docs/column/kaigai/598346.html
https://pc.watch.impress.co.jp/docs/column/kaigai/601519.html
に詳しく、インオーダーからアウトオブオーダーに変更になったというのが最も大きい変更点になるでしょう。
これをめっちゃカスタマイズして、AVX-512パイプを実装したり、SilvermontではオミットされたHyperThreadingを追加したのが、KnightsLandingで使っているコアになります。
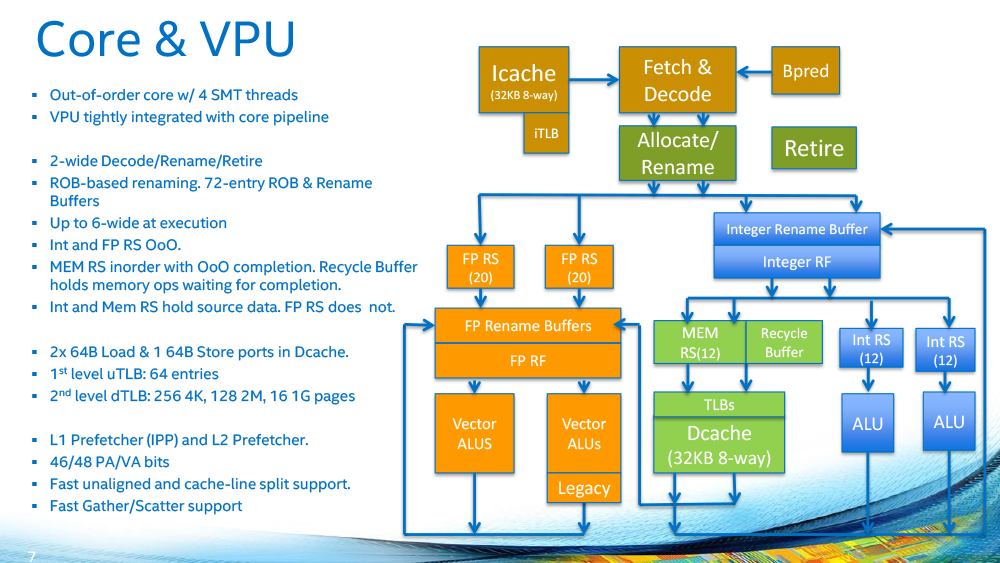
(引用元: https://pc.watch.impress.co.jp/img/pcw/docs/1008/665/html/Intel-06.png.html)
と
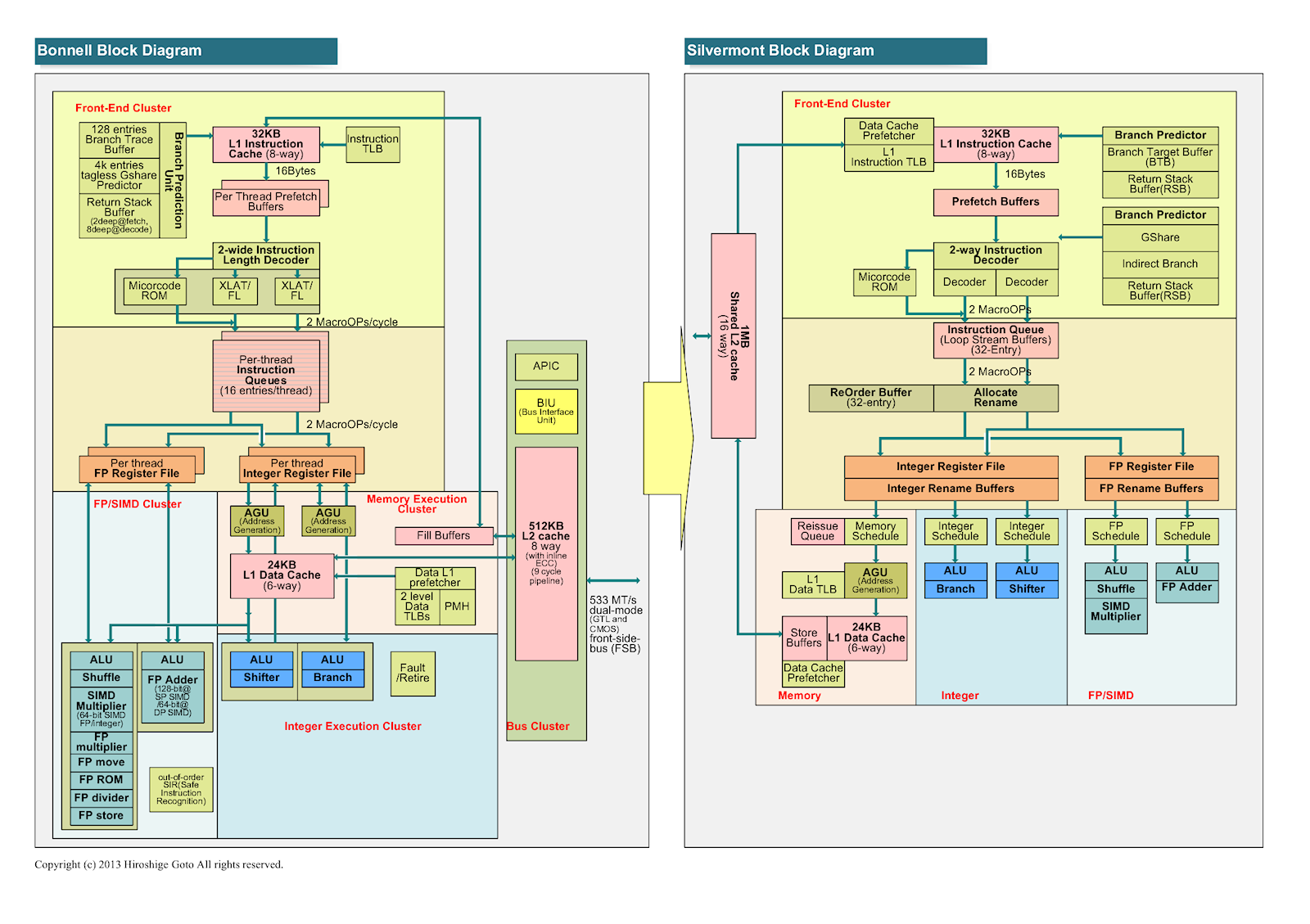
(引用元:https://pc.watch.impress.co.jp/img/pcw/docs/601/519/html/01.png.html)
の右側を比較すると、よく似ていることがわかると思います(ほんとか?
さて、KNLを語る上では避けて通れないのがMCDRAMの存在です。
当時…というかずっと、メモリ帯域のなさには悩まされていたわけですが、KNLは高速なメモリを搭載してくるということが分かっていました。この帯域が、~~理論値ではありますが、~~なんと490GB/sにもなろうというのですから、なんともワクワクしたものです。
(2020/12/03修正)
490GB/sは実測値だそうです。むしろ理論値は非公開。(@xmmymmzmmさんありがとうございます!)
さらにはこのMCDRAM、以下のような三つの使い方が提案されており、
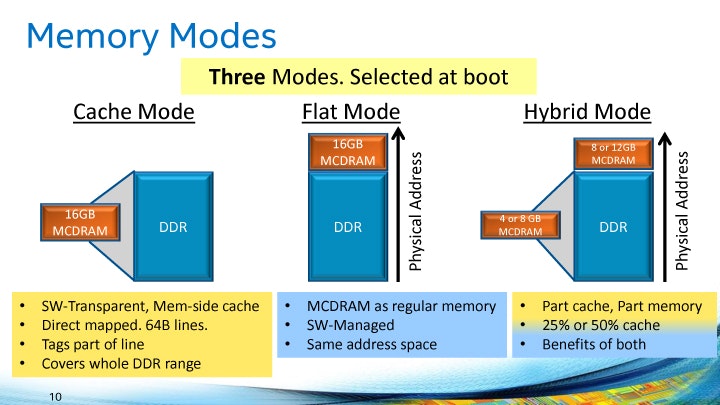
(引用元: https://pc.watch.impress.co.jp/img/pcw/docs/1006/546/html/15.jpg.html)
DDR4のキャッシュとして振る舞うモード、メモリとしてアドレッサブルなモード、そしてその両方のハイブリッドモードがありました。
これはアプリケーションに応じて変えてねということで、500GB/sのラストレベルキャッシュが追加されると思えば、なかなかに魅力的には聞こえてこないでしょうか。
KNLの評価
さて、アーキテクチャだけ見るとめっちゃ速そうに見えますが、ところがあんまり速くなくてつらみを強いられたのが現実でした。なんででしょうね…うーん…
実際問題、理論ピーク性能との比率を眺めてみると、Trinityの理論ピーク性能は41.4PFlopsなのに対して、実効性能は20.1PFlops、実行効率にして48.5%になっています。もちろん、これはすべてKNLによって引き起こされたものではありませんし、複合的な要因(ぶっちゃけどこがボトルネックになったかは公開情報からははっきり判定することができない) ので、一口に言えるものではありませんが、KNLがその要因の一つとなってしまったのは間違いないことでしょう。
現実に、KNLでDGEMM動かすと、全然速くないんですよねこれが…困ったことに…
KNL1つの理論ピーク性能は堂々の3.0TFlopsなのですが、どういうわけか全然出ません。今のところ観測したこのあるDGEMMの性能は1.5TFlopsぐらいです。HPLもそれに及ばないぐらい。もう少し出せるって方はぜひご連絡ください…出てるのを見てみたいので…
さて、なんでそもそもこんなDGEMMの性能出ないの?というと、いくつかの要因があるとは思いますが、一つは
http://nano.flop.jp/txt/instruction/index.html#sec4.6
で語られている問題が発生していると思われます。
- FPUを使うと熱のためクロックが落ちる
- VP0, VP1のうち、VP1が何サイクルかに一度停止している(5サイクルに1度?)
なんじゃそりゃって感じの挙動ですね。
個人的には、2-issueであることも影響があると思っていて、KNLのピーク性能ってVP0, VP1からFMAを発行しないと出ないんですよね…でもロード打ったら出ないんですよね…最内ループからロードを排除するっていうのは…いかなメモリオペランドとれるx86様であってもちょっと…
とはいえ。
AVX-512を使うことで、Xeonとのバイナリ互換性を維持しているため、Xeonで書いたコードがそのまま動くというのは非常に大きなメリットで、自明な超並列性を持つプログラムであれば、KNLに持ってくればそのまま高速になる、というのが実現できたかもしれないというのは非常に大きなビジョンでした。
また、MCDRAMのメモリ帯域も非常に魅力的で、メモリ帯域で律速するアプリケーションを持っていた人々にとっては、セルフブートして、なおかつバイナリ互換性も持っているというのは非常に魅力的に映ったと思います。なので、かえすもかえすも、FPUが全力で回ってくれなかったことだけが惜しまれる……
KNLはこの後、改良された第三世代であるKnightsHillにつながるはずだったのですが、残念ながらKnightsHillはキャンセルとなり、XeonPhiファミリーはKNLで終焉を迎えることになってしまいました。
いやほんとに残念……
(2020/12/03追記)
三男坊のKnightsMillのことすっかり忘れてました。しっかりArkにも記載あるのにね…(@xmmymmzmmさんありがとうございます)
https://ark.intel.com/content/www/jp/ja/ark/products/codename/57723/knights-mill.html
KnightsMillはKNLにディープラーニング用の命令セットを追加したもので、具体的に言えばAVX512_4FMAPSという命令群が追加されました。(あともう二つぐらい追加されてるけど、POPCNTとか)
これ結構すごい命令で
__m512 _mm512_4fmadd_ps (__m512 src, __m512 a0, __m512 a1, __m512 a2, __m512 a3, __m128 * b)
とかなってるんですが、srcに512bit * 4を要求する当たりかなり豪快だなって感じの命令です。
これの弊害か、何故か倍精度演算性能が低下していて、どうしちゃったの…という気持ちになります。
ただ、あまりにもひっそりローンチされたのと、実物が出回ってるのを全く見たことがないので、動かしたことは当然ありません…こいつの実機があるという方はぜひお声がけを…
まとめ
- Trinityについて述べました。
- 第二世代XeonPhiことKnightsLandingについて述べました。
- XeonPhiファミリーは非常に先進的だったのに終わってしまったのが残念だということが伝わればうれしいです
-
明日は山田の担当の予定で、何かこうかな…悩む…ロボ太先生が書いてくださることになりました!!たのしみ!!!!