山田です。
スパコンポエムAdC2020、十日目となりました。
今日は昨日 に引き続き、Summitの話をします。
Summit

(引用元: https://www.ornl.gov/news/ornl-launches-summit-supercomputer)
かっこいいスパコンにはかっこいいロゴがつきものです。
さて、今日はSummitの最強の片方、NVIDIA V100の話と、Summitのやばい構造について話しましょう!!
NVIDIA V100
NVIDIA P100の後継であり、Voltaアーキテクチャを採用した、2020年、A100にその座を譲るまで名実ともに最強のGPUでした。スパコンに一番採用されたGPUまである。とりあえずWhitepaper 貼っときますね。
V100は地味にラインナップが充実していて、V100 HBM2 16GBモデル、V100 HBM2 32GBモデル、この二つがそれぞれSXM2とPCIeにささるモデル、さらにPCIe専用でありながらほかの誰よりも強力なV100S!メモリ帯域も上限突破して900GB/sから1.134TB/sに!!
表にするとこんな感じ
| Spec | V100(SXM2) | V100(PCIe) | V100S(PCIe) |
|---|---|---|---|
| fp64 | 7.8TFlops | 7 TFlops | 8.2 TFlops |
| fp32 | 15.7TFlops | 14 TFlops | 16.4 TFlops |
| fp16 | 125TFlops | 112 TFlops | 130 TFlops |
| HBM2 | 16 or 32 GB | 16 or 32 GB | 32 GB |
| bandwidth | 900 GB/s | 900 GB/s | 1134GB/s |
| Dev I/F | NVLink2.0 or PCIe x16 | PCIe x16 | PCIe x16 |
| Power Consumption | 300W | 250W | 250W |
V100S、いくら投入された時期が2019年とかだからって、消費電力下がってるのに性能一割上がってたり帯域2割弱あがってたり、強力すぎませんかね……
さて、Voltaアーキテクチャですが、もうなんか語る気も失せるぐらいクソ強いですよね。こいつと戦わなきゃいけない人たちの気持ちを考えてほしい(お気持ち警察)
Pascalアーキテクチャからの変更点は以下のような感じ。
- SM構造の改善
- TensorCoreの実装
- スケジューラの倍化
- Warp内スレッドごとプログラムカウンタの独立化
- NVLink 2.0
まぁPascalアーキテクチャから順当進化して、その当時のプロセス限界まで盛ったのがVoltaアーキテクチャなので、KeplerアーキテクチャからPascalアーキテクチャのような大幅なジャンプアップはしていません。(MaxwellアーキテクチャからPascalアーキテクチャへもそんなに大きく飛んでなくない?という気はしないでもない)
SM構造の改善
毎回恒例~~SMの中身見るコーナーーー
まずはPascalアーキテクチャのSMから。

(引用元: GP100 Whitepaper)
続いてVoltaアーキテクチャのSM。
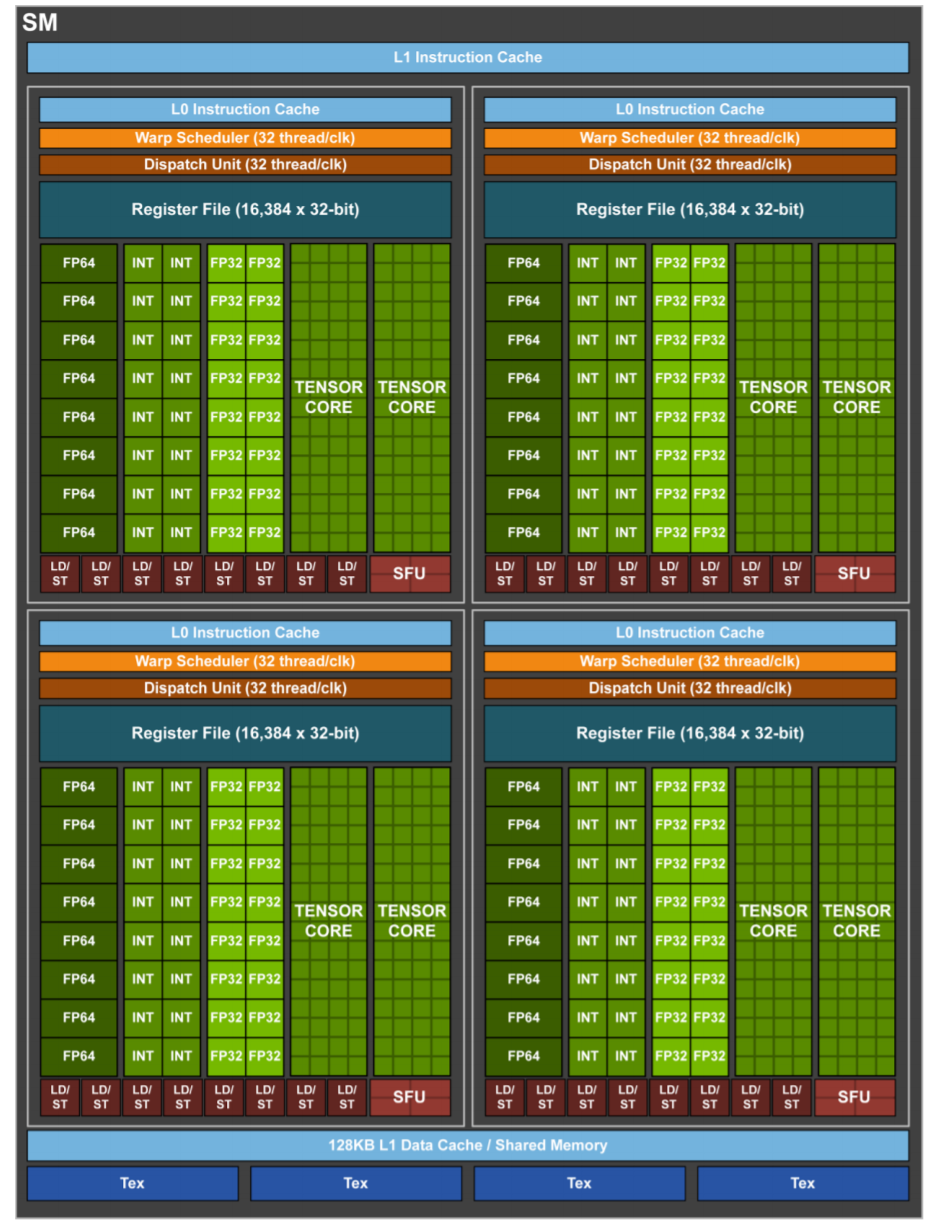
(引用元: V100 Whitepaper)
まず大きく目を引くのが、半分ぐらいを占めるTensorCoreの存在でしょう。
TensorCoreの実装
世はまさに大ディープラーニング時代!!!!!
というわけで、NVIDIAさんはここ五、六年ぐらいディープラーニングでウハウハwwwだったしているわけなんですけれども、はい、ディープラーニングってやつでなんとかして!を地で行っているわけですね。まぁそうなると、従来のPascalアーキテクチャまでのCUDA Coreの構造というのは必ずしも効率的というわけではありません。というか、やることが決まっている(SGEMMかHGEMMだしなぁ) ので、命令発行ユニットもスケジューラもいらないわけですよ。
というわけで、そういうハードウェアを実装しました。なんか一周した感じがありますね(?
Pascalアーキテクチャでやった場合とTensorCoreでやった場合のイメージ図では
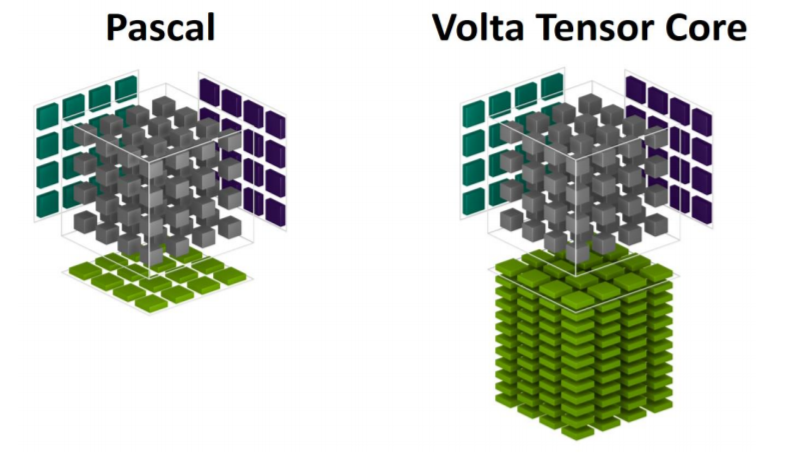
となるそうですが、これだけで何が伝わるっていうんだw
TensorCoreでは4x4のGEMMが撃てるというのが正しい言い方であり、P100比で12倍高速になっているそうです。
この時期というのは、GoogleのTPUをはじめとしてディープラーニング用のプロセッサがタケノコのようにポコポコ出てきたタイミングで、圧倒的パワーでそこに突っ込んだNVIDIAの判断は間違ってはいなかったのではないかと思いますね。
ちなみに、TensorCoreを実際に使ってみたという話は、Fixstarsさんのブログ に詳しいのでぜひご一読を。
スケジューラの倍化
Pascalアーキテクチャのころは、2つのスケジューラと4つのディスパッチャで64 CUDA Coreをハンドリングしていたわけですが、このスケジューラを倍にして、4つのスケジューラと4つのディスパッチャで64 CUDA Coreをハンドリングするようになりました。これがどううれしいかというと、成瀬さんの説明に詳しいのであんまりここで解説するのもなんなので、こちらを読んでください。
端的に言うと、この形になったおかげで、このサブSM的なヤツに命令が毎サイクル投入されるようになったので、fp32とInt命令が毎サイクル投入可能になりました。なので、V100ではアドレス計算とかもモリモリできます。これは割とうれしい。
プログラムカウンタの独立化
命令発行の単位が1Warp = 32スレッドであることはいろんなところで書かれているので今更ですが、NVIDIAのGPUにとってつらいのは分岐です。特にこのWarpの中で、各スレッドで処理が違うもの。こうなると、Warp-divergenceという性能が1/nになる現象が発生します‘。
しかもこのWarp-divergenceという現象のせいで、ほかのスレッドとの同期をとるような命令をDivergence中に発行すると、プログラムが止まります。ifの中でsyncthreads打つな高校というやつです。syncthreadsとはすなわち、すべてのスレッドがそこで同期することを求めているので、これをやるとえらいことが発生します。具体的には世界がヤバい最悪GPUが止まります。
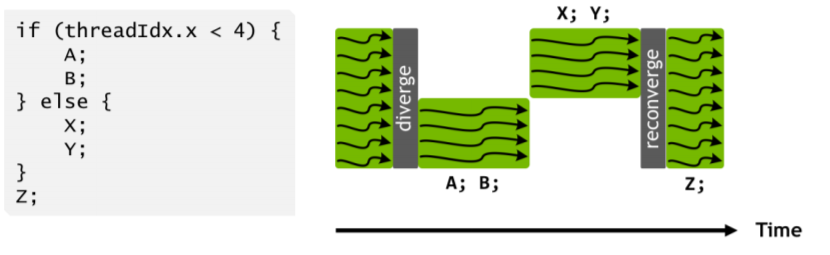
Pascalアーキテクチャまでだと、このようにDivergenceが発生すると、片方のパスのすべての実行が終わるまでもう片方のパスにはいかないという挙動をしていました。それはそうで、プログラムカウンタが一個しかないので、自分がどこにいるか、どこまで実行したかというのは記憶しておくことができないからですね。
一方、これがVoltaアーキテクチャになると、
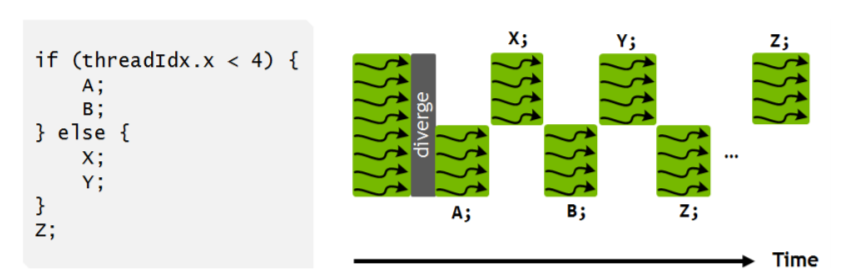
自分がどこにいるかがわかるので、Divergence中の実行命令列をインタリーブとかもできるようになったりするわけです。
ただ、独立したプログラムカウンタがあるとはいえ命令発行が独立して行えるようになっているわけではないので、Warp-divergenceがなくなるわけではありません。
あと、これでDivergenceしたあとは、またWarp全員がちゃんと同期を取ってあげる必要があるため、ちゃんとそれ専用の命令を発行してあげる必要があります。
あとL1が速くなってShared Memoryと再統合されたりしました(雑
NVLink 2.0
NVLinkがさらに速くなったんですよ!!!
Pascalアーキテクチャで採用されていたNVLinkは1.0で、160GB/sまでの接続でした。
これがですね、300GB/sにまで拡張されました。約2倍!
これだけの広帯域でデバイス間の接続がされているというのも非常に良いのですが、この真骨頂はこの帯域でホストと接続されたときですね。
そう、つまり、POWER9との組み合わせ……!!!
Summitの構成
というわけで、話がSummitに戻ってきました。
Summitは昨日の記事にも書いた通り、POWER9 * 2 に、V100 * 6という構成です。
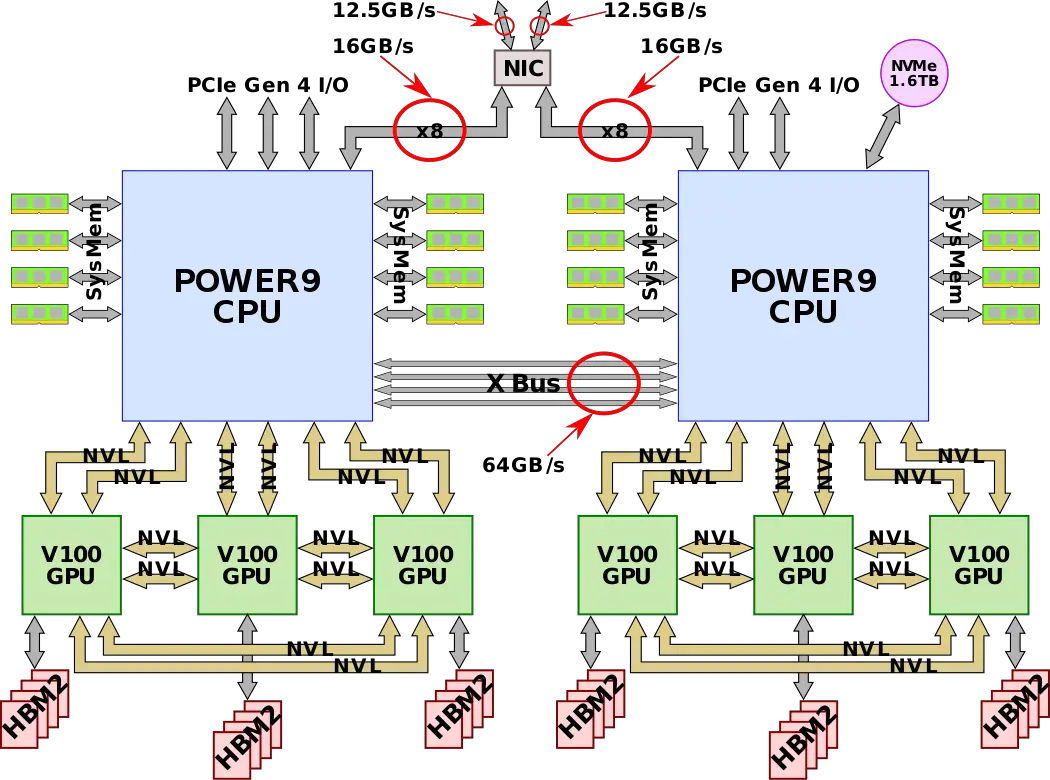
(引用元: https://en.wikichip.org/wiki/supercomputers/summit)
1つのPOWER9にはV100が3つ接続されているわけですが、ホスト-デバイス間の接続速度はというと、NVLink 2.0を用いることで、100GB/sの超広帯域を実現しました!!
実際この100GB/sっていう数字は割とすごくて、POWER9のメモリ帯域が8chで170.7GB/sであることを考えると、DDR4の4ch分ぐらいは軽くあるんですよね。バス帯域もここまで来たか…
V100の唯一の弱点というのが、演算速度に対してメモリ容量が少ない、というものです。7.8TFlopsで16GBのDGEMMとか打つと、一瞬で吹き飛ぶんですよね…HPLの話をするのなら、このDGEMMの時間というのは非常に重要で、DGEMMの時間と次の消去に必要なパネルの転送が追い付くかどうか、というのが実効効率に影響してきます。
この写真はSC18のGreen500 BoFで公開されたもので、私も実際に聴いていたのですが(この写真を撮ったのはえらい人。ありがとうございます)

Nの値から使用メモリを逆算すると、到底V100の16GBに乗りきるような数字ではないんですよね。
(この式は忘れたからここでは書かないですぅ。そのうちどこかで書くかもしれません)
なので、このことから、SummitはPOWER9の主記憶容量もフルに使いきって、DGEMMをしながらその裏でNVLinkの広帯域を使って行列を入れ替えつつHPLを実行していると考えられるわけです。いやー、ORNLとNVIDIAの底力って感じですね。あと、これを実現できるホスト-デバイス間の広帯域接続は本当に素晴らしいと思います。
そんなSummitの理論ピーク性能は200.7PFlops,HPLの実効性能は140.6PFlops。実効効率は74%と、アクセラレータを使ったシステムとしては高い水準にあります。
もちろん、SummitはHPLにとどまらず、HPCG, HPL-AIでも高い成績を収めており、また、かのゴードンベル賞にも輝いています。NVIDIAが満を持して投入した最強のGPU, V100と、極限までリッチな半導体であるところのPOWERとがアーキテクチャレベルで密接に結びつき非常に強力な構成となったSummitは、名実ともに最高のスパコンの一つといえるのではないでしょうか。
後編のまとめ
- NVIDIA V100について述べました。
- POWER9 + NVIDIA V100の組み合わせの強力さを述べました。
- 明日は山田の担当で…いよいよ何やろうかな…
おまけ

Summitを順当に拡張していって1ExaFlopsを達成するには、概算で70MWぐらいあれば行けそう、という話。
これぐらいだと、誰か70MWぐらいの受電設備を作りそうだなと思ったり思わなかったりするのであった。富岳が40MWであるからして。ちょっと頑張ればいけちゃいそうだよね。