はじめに
いやーついにRyzen発売しましたね。
みなさん並びましたか?僕は当然並びました。並ぶ気なかったけど。
さて、巷ではAMD復活の狼煙だとかIntelを超えたとか非常にパワーなワードが並ぶRyzenへの評価ですが、それはいかほど真実なのでしょうか?
コストパフォーマンスとかそういうのはどうでもいい、絶対性能としてどこまでまともになったのか、というのを評価してみたいと思います。
全体的にこれから追記するんで、そのつもりでごらんください。
この記事で使ったコードは
https://github.com/telmin/YAMADABenchmarkSuite
においてあるので、時間がある人は結果を送ってくれると喜びます。
評価環境
CPU : Ryzen 1800X
MEM : DDR4-2133 16GB(8GB * 2)
OS : CentOS7.3
これ以外はテキトーなSSDがついてるだけでGPUすらついてないそれでいいのかって環境です。
ヘッドレス運用じゃ!!
ベンチマークたち
CPUID
まずはお約束とも言えるCPUIDを見ます。
processor : 0
vendor_id : AuthenticAMD
cpu family : 23
model : 1
model name : AMD Ryzen 7 1800X Eight-Core Processor
stepping : 1
microcode : 0x800110e
cpu MHz : 2200.000
cache size : 512 KB
physical id : 0
siblings : 16
core id : 0
cpu cores : 8
apicid : 0
initial apicid : 0
fpu : yes
fpu_exception : yes
cpuid level : 13
wp : yes
flags : fpu vme de pse tsc msr pae mce cx8 apic sep mtrr pge mca cmov pat pse36 clflush mmx fxsr sse sse2 ht syscall nx mmxext fxsr_opt pdpe1gb rdtscp lm constant_tsc art rep_good nopl nonstop_tsc extd_apicid aperfmperf eagerfpu pni pclmulqdq monitor ssse3 fma cx16 sse4_1 sse4_2 movbe popcnt aes xsave avx f16c rdrand lahf_lm cmp_legacy svm extapic cr8_legacy abm sse4a misalignsse 3dnowprefetch osvw skinit wdt tce topoext perfctr_core perfctr_nb bpext perfctr_l2 arat hw_pstate npt lbrv svm_lock nrip_save tsc_scale vmcb_clean flushbyasid decodeassists pausefilter pfthreshold fsgsbase bmi1 avx2 smep bmi2 rdseed adx smap clflushopt sha_ni xsaveopt xsavec xgetbv1
bogomips : 7186.04
TLB size : 2560 4K pages
clflush size : 64
cache_alignment : 64
address sizes : 48 bits physical, 48 bits virtual
power management: ts ttp tm hwpstate eff_freq_ro [13] [14]
http://pc.watch.impress.co.jp/docs/column/kaigai/1047492.html
とか
http://pc.watch.impress.co.jp/docs/column/kaigai/1039027.html
を見るとわかる通り、AVX,SSEの演算器としては128bitのものを積んでいます。
なんで、AVXや2を使うと、128bit * 2として内部で展開されることになります。Intel比ではパフォーマンスが半分になっていることでしょう。
Stream
とりあえず鉄板でStreamを走らせます。
事前情報として、Ryzenはメモリモジュールに制限があることが知られています。
より引用すると
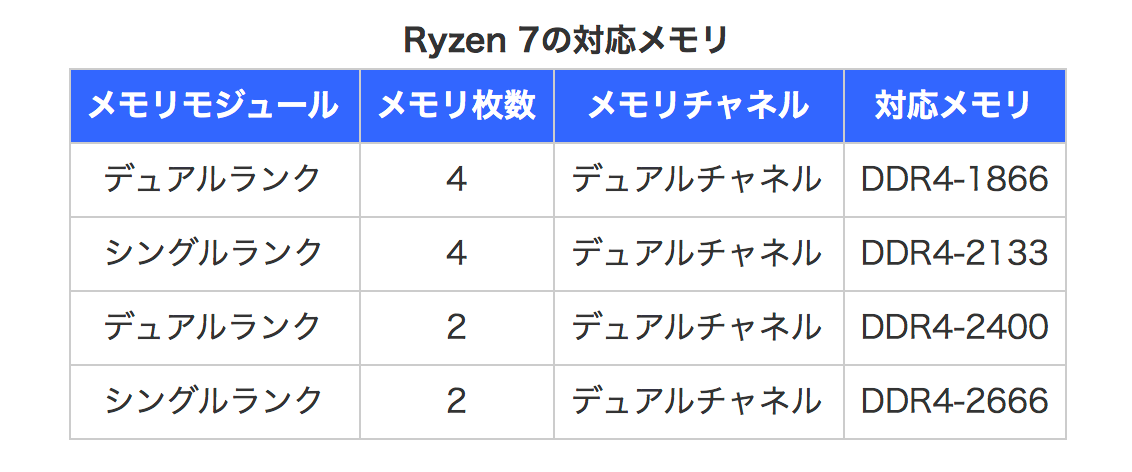
となっており、つまりはデュアルランクのメモリを4枚さすと1866まで落ちるはずだ、という話。
なんで、手元にデュアルランクのメモリ(ただし同一モジュールは2枚ずつ)という状況で試してみました。
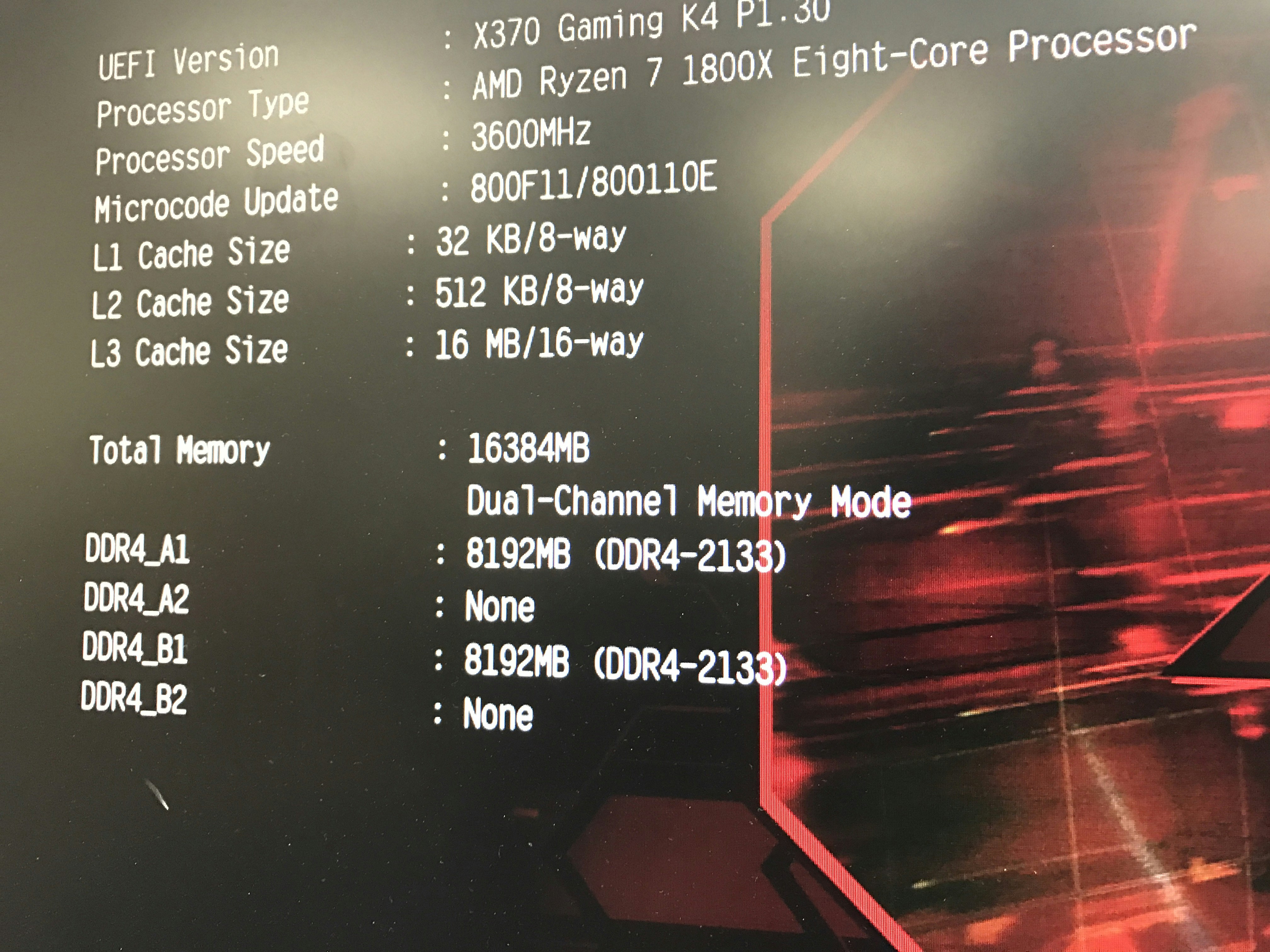
まず2枚さした状態。
BIOSは2133で認識してくれていることがわかります。
この状況でのStreamの結果は以下のとおり。
-------------------------------------------------------------
STREAM version $Revision : 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array Size = 409600000 (elements), Offset = 0 (elements)
Memory per array = 3125 MiB (= 3.05176 GiB).
Total Memory required = 9375 MiB (= 9.15527 GiB).
Each kernel will be executed 10 times.
Function Best Rate MB/s Avg time Min time Max time
Copy: 17772.5 0.368850 0.368749 0.368981
Scale: 17793.8 0.368364 0.368309 0.368429
Add: 19930.1 0.493343 0.493244 0.493421
Triad: 19977.0 0.492249 0.492087 0.492328
-------------------------------------------------------------
なんかピークと比べると若干遅くねという気持ちになるが、とりあえずこう言うことにしておこう。
それではデュアルランク * 2にした時の話。
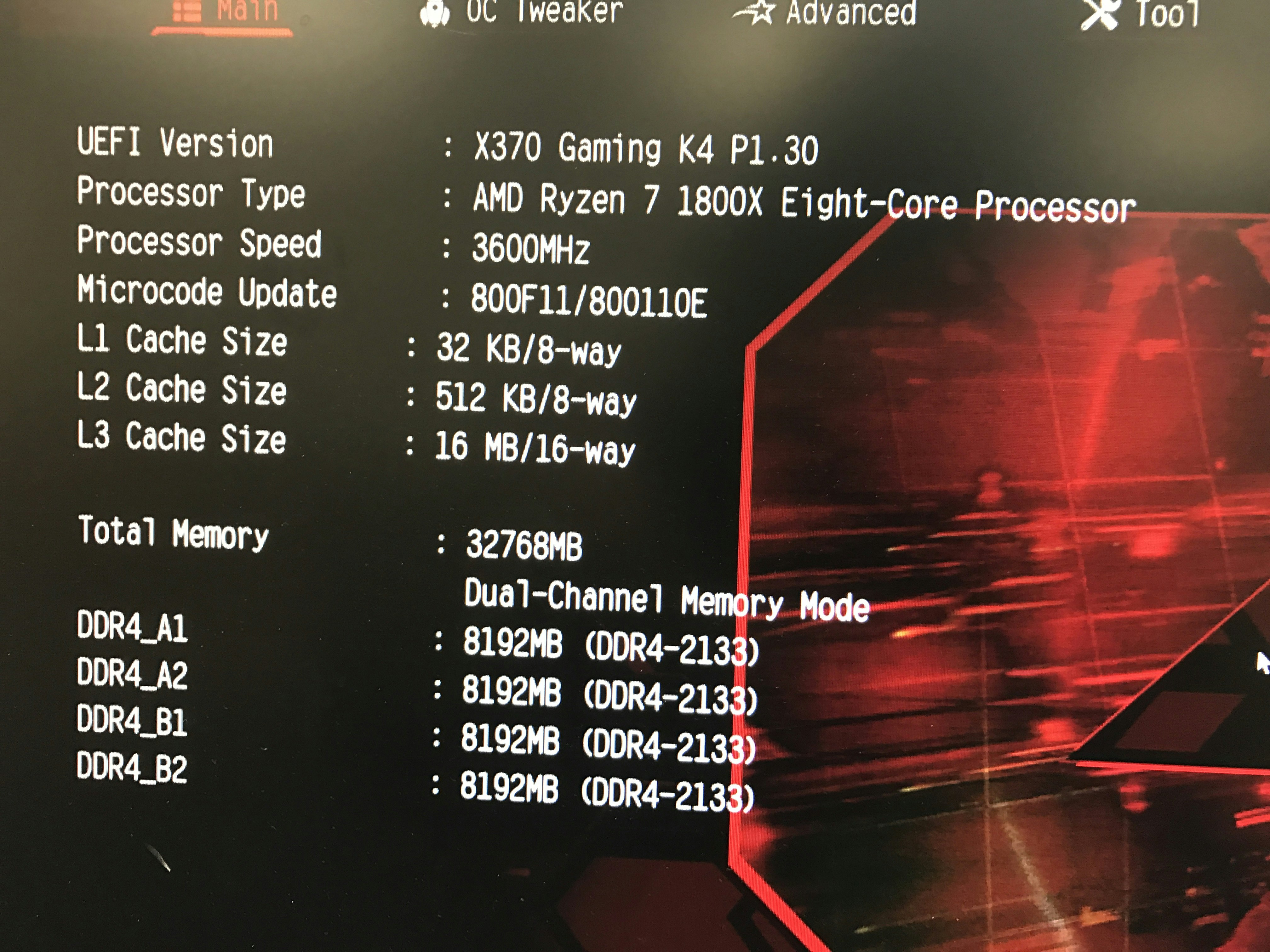
デュアルランク品のはずなんじゃが2133で認識されとるぞい…
ちょっとデュアルランク品の証拠を撮り忘れてたからまた今度撮っとく。
さて、この時の結果が以下のとおり。
-------------------------------------------------------------
STREAM version $Revision : 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array Size = 409600000 (elements), Offset = 0 (elements)
Memory per array = 3125 MiB (= 3.05176 GiB).
Total Memory required = 9375 MiB (= 9.15527 GiB).
Each kernel will be executed 10 times.
Function Best Rate MB/s Avg time Min time Max time
Copy: 16239.4 0.403903 0.403560 0.404358
Scale: 16264.0 0.403115 0.402951 0.403254
Add: 18211.9 0.539922 0.539780 0.540232
Triad: 18272.4 0.538162 0.537993 0.538302
-------------------------------------------------------------
なんでか知らないけど実測値が遅くなりました。さて何でだろう。
実は1866で動作してるのではとか思ったけど、考えてみるとそうとは言い切れないような気持ちになってきます。
2133と1866の比率を考えると、
1866 / 2133 = 0.8748
となり、約13%ぐらい落ちる計算になります。が、Copyに着目すると
16239 / 17772 = 0.9137
とのことから、約9%遅い。となると、これはクロックが落ちているというより別の要因で落ち込んでいるのではないかと考えます。
かといって調べる気は特にないわけですが😣
まぁメモリについては別の人が詳細に調べているのでそちらをご参照ください。
Twitterとかだと自作erが「AMDは足回りが弱い」とか「メモコンが死にかけ」とか何の根拠もなく言っていたりするのですが
彼らはこういうベンチマークの数字を一切上げてきませんね。何ででしょうね。ベンチマークを取るということすら知らないんでしょうか。
FFT
三次元FFTを走らせました。
ちなみにこれは完全にFFTWを使っています。また、走らせるコードは@drmaruyama 先生にご提供いただきました。ありがとう!
の結果では、FFTはIntelと比べて約54%だそうですが、果たしていかに。
…とはいえ、比較する結果がまだないので絶対性能しかでないです。ゴメンネ
$ OMP_NUM_THREADS=8 ./a.out
3-D FFT: 128 x 128 x 128
On-board: 0.071967 msec, 3.059753 GFLOPS.
On-board: 0.071289 msec, 3.088868 GFLOPS.
3-D FFT: 256 x 256 x 256
On-board: 1.535539 msec, 1.311113 GFLOPS.
On-board: 0.238128 msec, 8.454554 GFLOPS.
$ OMP_NUM_THREADS=16 ./a.out
3-D FFT: 128 x 128 x 128
On-board: 0.039964 msec, 5.509977 GFLOPS.
On-board: 0.034110 msec, 6.455667 GFLOPS.
3-D FFT: 256 x 256 x 256
On-board: 0.701101 msec, 2.871578 GFLOPS.
On-board: 0.212743 msec, 9.463365 GFLOPS.
DGEMM, SGEMM
ディーーーーープルァァーーーーーニングで非常に重要な、そして科学技術計算(とか書くと嘘つけコラって言われるんだけど) でも重要なGEMMです。
Ryzenに最適化されたBLASの実装はまだ存在しないため、Haswell向けにビルドされたOpenBLASを使用します。
この時の結果は以下のようになりました。
M 10240 N 10240 K 10240 al -1 b 1
Dgemm start
memory use 2.34375 GB
19:58:56 initialize done.
185.864 GFlops, 0.0759537
Sgemm start
19:59:32 initialize done.
384.731 GFlops, 0.139719
Ryzen 1800Xの倍精度ピーク性能を雑に計算すると、
3.6(クロック) * 8(コア) * 4(256bit / 64bit) * 2(FMA) = 230.4GFlops
となります。ほんとか?
実行効率を計算してみると
185.8 / 230.4 = 0.806
いやまてほんとか…? 80%とか出るのか…?うーん…
とりあえずそれぐらい出るみたいではあります。
HPL
さて、お待ちかねのHigh Performance Linpack!!
実装は、現神戸大学の牧野淳一郎先生が作られたlu2を使用します。BLASもOpenBLASを使用します。
pdate time= 3.97971e+11 ops/cycle= 58.7093
update matmul time= 3.89208e+11 ops/cycle= 27.083
update swap+bcast time= 8.68252e+09 ops/cycle= 0.0507454
total time= 7.61557e+11 ops/cycle= 30.8004
rfact time= 3.61511e+11 ops/cycle= 0.00156629
ldmul time= 4.55635e+10 ops/cycle= 45.2464
colum dec with trans time= 1.71583e+11 ops/cycle= 0.00312968
colum dec right time= 9.62098e+10 ops/cycle= 5.9299
colum dec left time= 4.01129e+08 ops/cycle= 0.0833231
rowtocol time= 2.02757e+10 ops/cycle= 0.026485
column dec in trans time= 1.34916e+11 ops/cycle= 0.0318421
coltorow time= 1.63865e+10 ops/cycle= 0.032771
dgemm8 time= 6.41391e+09 ops/cycle= 0.669633
dgemm16 time= 5.73131e+09 ops/cycle= 1.49877
dgemm32 time= 5.9025e+09 ops/cycle= 2.91061
dgemm64 time= 9.03447e+09 ops/cycle= 3.80318
dgemm128 time= 5.60377e+09 ops/cycle= 12.2631
main dgemm time= 4.30897e+11 ops/cycle= 49.5136
col trsm time= 1.03903e+10 ops/cycle= 4.77655
col update time= 8.5353e+10 ops/cycle= 0.536739
col r dgemm time= 5.93845e+10 ops/cycle= 18.4428
col right misc time= 2.5965e+10 ops/cycle= 0.0827067
backsub time= 1.19997e+09 ops/cycle= 0.894805
col dec total time= 2.68199e+11 ops/cycle= 0.00211123
DGEMM2k time= 4.74281e+11 ops/cycle= 49.3315
DGEMM1k time= 1.50035e+10 ops/cycle= 43.5121
DGEMM512 time= 9.44299e+09 ops/cycle= 32.7479
DGEMMrest time= 4.52212e+10 ops/cycle= 6.31397
TRSM U time= 6.64871e+09 ops/cycle= 24.1167
col r swap/scale time= 4.63074e+08 ops/cycle= 0.144354
rfact ex coldec time= 9.33058e+10 ops/cycle= 0
ld_phase1 time= 116892 ops/cycle= 574.11
rfact misc1 time= 6.26886e+09 ops/cycle= 0
rfact misc2 time= 4.29086e+10 ops/cycle= 0
rfact misc3 time= 3.52478e+09 ops/cycle= 0
rfact misc4 time= 4.06036e+10 ops/cycle= 0
copysubmats time= 1.66688e+10 ops/cycle= 0.138394
localhost.localdomain.2557hfi_wait_for_device: The /dev/hfi1_0 device failed to appear after 15.0 seconds: Connection timed out
N=32768 Seed=1 NB=2048
P=1 Q=1 Procs row major=0 usehuge=0
usetwocards=0 ncards=1 cardid=0 maxpt=0 vcommscheme=0 stress=0
Error = 5.878116e-08 1.724760e-09
============================================================================
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR01R2C32 32768 2048 1 1 212.27 1.105e+02
----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0318198 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0255773 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0044649 ...... PASSED
============================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
----------------------------------------------------------------------------
End of Tests.
============================================================================
cpusec = 2806.69 wsec=212.272 110.501 Gflops
HPLとしては110GFlopsとなりました。
メモリにはまだ余裕があるので大きくできそうではあります。今後の課題にしときます。
うーん、これだとピーク比で47%ぐらいしか出てないんで、もう少し速くならんかなという気持ち…
Xeon E5-1650 v3での結果
@k_oi さんにXeon E5-1650 v3での結果をご提供いただきました。ありがとうございます。
STREAM
$ ./stream_cxx.out --arraysize 409600000
-------------------------------------------------------------
STREAM version $Revision : 5.10 $
-------------------------------------------------------------
This system uses 8 bytes per array element.
-------------------------------------------------------------
Array Size = 409600000 (elements), Offset = 0 (elements)
Memory per array = 3125 MiB (= 3.05176 GiB).
Total Memory required = 9375 MiB (= 9.15527 GiB).
Each kernel will be executed 10 times.
Function Best Rate MB/s Avg time Min time Max time
Copy: 30946.3 0.214962 0.211773 0.228922
Scale: 31006.5 0.213416 0.211362 0.216842
Add: 33919.8 0.290569 0.289813 0.292838
Triad: 33978.6 0.291207 0.289311 0.295740
-------------------------------------------------------------
Solution Validates: avg error less than 1.000000e-13 on all three arrays
FFT
$ OMP_NUM_THREADS=6 ./fftw
3-D FFT: 128 x 128 x 128
On-board: 0.014684 msec, 14.995488 GFLOPS.
On-board: 0.009763 msec, 22.554633 GFLOPS.
3-D FFT: 256 x 256 x 256
On-board: 0.277897 msec, 7.244636 GFLOPS.
On-board: 0.268828 msec, 7.489059 GFLOPS.
$ OMP_NUM_THREADS=12 ./fftw
3-D FFT: 128 x 128 x 128
On-board: 0.010458 msec, 21.055685 GFLOPS.
On-board: 0.008329 msec, 26.439007 GFLOPS.
3-D FFT: 256 x 256 x 256
On-board: 0.279447 msec, 7.204465 GFLOPS.
On-board: 0.272284 msec, 7.393980 GFLOPS.
SGEMM, DGEMM
M 10240 N 10240 K 10240 al -1 b 1
Dgemm start
memory use 2.34375 GB
3:3:16 initialize done.
254.995 GFlops, 1.73491
Sgemm start
3:3:51 initialize done.
511.707 GFlops, 5.02656
HPL
$ mpirun -np 1 ./lu2_mpi -n 32768
(略)
Error = 5.930995e-08 1.890872e-09 [41/1489]
update time= 2.91993e+11 ops/cycle= 80.0177
update matmul time= 2.77436e+11 ops/cycle= 37.9941
update swap+bcast time= 1.27753e+10 ops/cycle= 0.0344883
total time= 6.09222e+11 ops/cycle= 38.5019
rfact time= 3.14754e+11 ops/cycle= 0.00179896
ldmul time= 3.53161e+10 ops/cycle= 58.3752
colum dec with trans time= 1.60102e+11 ops/cycle= 0.00335411
colum dec right time= 8.19711e+10 ops/cycle= 6.95994
colum dec left time= 3.63658e+08 ops/cycle= 0.0919088
rowtocol time= 2.27866e+10 ops/cycle= 0.0235665
column dec in trans time= 1.24084e+11 ops/cycle= 0.0346219
coltorow time= 1.32282e+10 ops/cycle= 0.0405952
dgemm8 time= 5.89311e+09 ops/cycle= 0.728812
dgemm16 time= 5.34285e+09 ops/cycle= 1.60774
dgemm32 time= 5.71966e+09 ops/cycle= 3.00365
dgemm64 time= 6.63841e+09 ops/cycle= 5.1759
dgemm128 time= 5.24282e+09 ops/cycle= 13.1074
main dgemm time= 3.07159e+11 ops/cycle= 69.4599
col trsm time= 8.79853e+09 ops/cycle= 5.64071
col update time= 7.27637e+10 ops/cycle= 0.629603
col r dgemm time= 5.02651e+10 ops/cycle= 21.7888
col right misc time= 2.24946e+10 ops/cycle= 0.0954667
backsub time= 8.72095e+08 ops/cycle= 1.23122
col dec total time= 2.42443e+11 ops/cycle= 0.00233553
DGEMM2k time= 3.39549e+11 ops/cycle= 68.906
DGEMM1k time= 1.12077e+10 ops/cycle= 58.2487
DGEMM512 time= 8.232e+09 ops/cycle= 37.5653
DGEMMrest time= 3.83344e+10 ops/cycle= 7.44828
TRSM U time= 5.40459e+09 ops/cycle= 29.6683
col r swap/scale time= 4.05956e+08 ops/cycle= 0.164665
rfact ex coldec time= 7.22276e+10 ops/cycle= 0
ld_phase1 time= 59263 ops/cycle= 1132.39
rfact misc1 time= 5.00091e+09 ops/cycle= 0
rfact misc2 time= 3.16592e+10 ops/cycle= 0
rfact misc3 time= 2.75225e+09 ops/cycle= 0
rfact misc4 time= 3.28153e+10 ops/cycle= 0
copysubmats time= 1.78958e+10 ops/cycle= 0.128906
============================================================================ [3/1489]
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR01R2C32 32768 2048 1 1 174.36 1.345e+02
----------------------------------------------------------------------------
============================================================================
T/V N NB P Q Time Gflops
----------------------------------------------------------------------------
WR01R2C32 32768 2048 1 1 174.36 1.345e+02
----------------------------------------------------------------------------
||Ax-b||_oo / ( eps * ||A||_1 * N ) = 0.0348843 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_1 * ||x||_1 ) = 0.0280407 ...... PASSED
||Ax-b||_oo / ( eps * ||A||_oo * ||x||_oo ) = 0.0048949 ...... PASSED
============================================================================
Finished 1 tests with the following results:
1 tests completed and passed residual checks,
0 tests completed and failed residual checks,
0 tests skipped because of illegal input values.
----------------------------------------------------------------------------
End of Tests.
============================================================================
cpusec = 1578.84 wsec=174.364 134.525 Gflops
Xeonだと全体的にメモリ帯域が高いことが確認できます。Ryzenの倍ぐらい出ているでしょうか。
一方で、HPLが意外と振るわない結果となっています。
DGEMMのピーク値は以下になると考えられます。
3.50(クロック) * 6(コア) * 4(256bit) * 2(FMA) * 2(dual) = 336GFlops
なので、DGEMMの実行効率としては約75%です。ややRyzenを下回る結果となりました。
この時、HPLの実行効率は39%と、Ryzenをさらに下回る結果になりました。うーん、何かが悪さをしているんでしょうか。
もっとも、OpenBLASを使っているので、やや性能が出にくいというのはあるのかもしれません。本当はMKL使うべきなのかもしれません。
ご協力のお願い
冒頭にも書きましたが、本記事で使ったコードは全て
https://github.com/telmin/YAMADABenchmarkSuite
においてあります。
Ryzenとの比較対象として、Core i7とかXeonとかでの結果をとってくださる方がいらっしゃいましたら、コメントかTwitterのほうでお声がけください。
よろしくお願いします。