Wikipediaの記事データは、自分でクロールせずとも、ダンプデータが用意されているため、それをダウンロードすることで取得することができます。(むしろクロールはしちゃダメ)
とりあえず全記事の最新の本文データはenwiki-20180701-pages-articles-multistream.xml.bz2(2018年7月1日英語版の場合)というようなファイルに格納されているので、そこから取得できるのですが、このうち、特定のカテゴリ以下の記事のみをすべて取得したいといった場合は、少し工夫が必要です。
この記事では、Web上で公開されている便利なAPI等は使用せずに、ダンプデータのダウンロード以外をローカルで完結させる方法で記します。また、特定のプログラミング言語での実装は記さず、方針のみを記します。
必要なファイル
下記のファイル名は、2018年7月1日英語版でのファイル名ですので、適宜読み替えてください。
- 記事の本文データ(
enwiki-20180701-pages-articles-multistream.xml.bz2) - 記事の所属カテゴリSQLデータ(
enwiki-20180701-categorylinks.sql.gz) - 記事のインデックスSQLデータ(
enwiki-20180701-page.sql.gz)
2のデータベースを使うことで、ある記事がどのカテゴリに属するのかを調べることができるのですが、ある子カテゴリがどの親カテゴリに属するかを調べることもできますので、これを利用します。
1の本文データは、予め、WikiExtractor等できれいにしておきます。
MySQL環境を用意してSQLデータをインポート
予め、MySQLの環境を用意しておき、「enwiki」といったような名前のデータベースを1つ作っておきます。(MySQL環境の構築方法はこの記事では扱いません。)
その後、上述ファイルの2と3をインポートします。下記は、bash上のコマンドでインポートする例です。
mysql -u ユーザ名 -p パスワード enwiki < enwiki-20180701-categorylinks.sql.gz
mysql -u ユーザ名 -p パスワード enwiki < enwiki-20180701-page.sql.gz
適当なクライアントソフトでデータベースの中身を見ると、テーブルが2つインポートされていますね。

方針
下記のステップで、特定のカテゴリ以下の記事のみをすべて取得していきます。
- 特定のカテゴリ以下のサブカテゴリをすべて取得
- 記事を1つずつ走査して、1.で取得したカテゴリに属するかどうか判別
1.特定のカテゴリ以下のサブカテゴリをすべて取得
SELECT cl_to AS parent, page_title AS child
FROM page JOIN categorylinks ON categorylinks.cl_from=page.page_id
WHERE categorylinks.cl_type = "subcat" AND categorylinks.cl_to = "親カテゴリ名";
例えば、英語版Wikipediaにおいて、親カテゴリ名を「Science_and_technology」と指定した場合、以下のような結果が返されます。
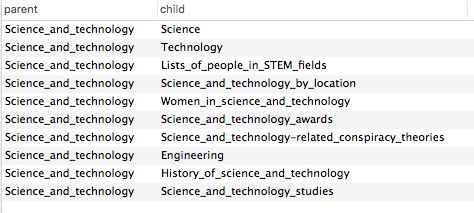
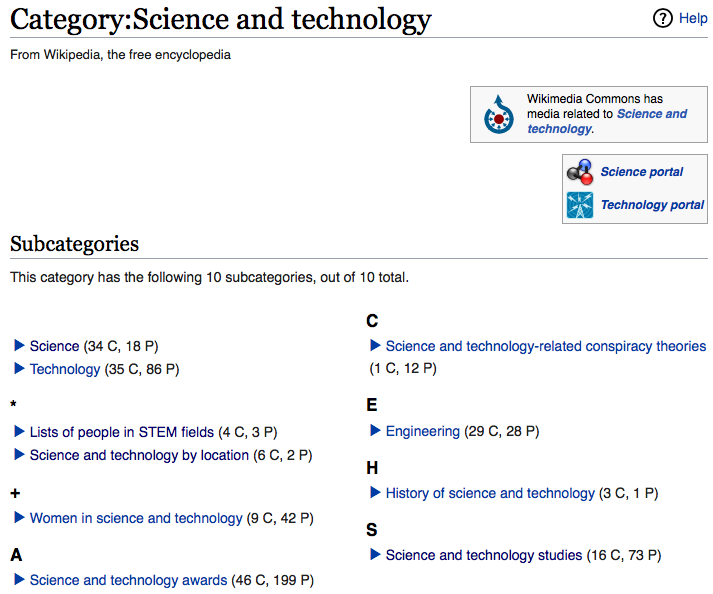
実際に、Wikipediaのページと比較しても、一致していることが分かります。
上記のSQL文を再帰的に発行し、得られたchildをセット(集合)等に格納することで、ある親カテゴリに属する子カテゴリをすべて取得することができます。
ただし、注意したいのは、Wikipediaのカテゴリはツリー構造になっておらず、有向非巡回グラフになっている点です。例えば、
Xという記事はカテゴリAに属し、カテゴリAはカテゴリBに属し、カテゴリBはカテゴリCに属し、カテゴリCはカテゴリAに属している
という場合もありえます。
よって、単純に再帰的に発行してしまうと無限ループとなってしまいます。一度取得したカテゴリがもう一度出てきた場合は、それ以下を探索しないようにしましょう。
また、カテゴリ名の中の空白はアンダーバー(_)になっています。
2. 記事を1つずつ走査
上述の「必要なファイル」で述べた1.の本文データは、中身はXMLになっており、記事ごとにID属性がふられています。当該記事が、どのカテゴリに含まれるかは、下記のSQL文を発行することで分かります。
SELECT cl_to AS category FROM categorylinks WHERE cl_from = "記事ID"
例えば、英語版Wikipediaにおいて、記事IDが691182である記事がどのカテゴリに属するかを調べた場合、以下のような結果が返されます。
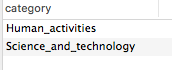
これらのカテゴリが、上記の節で得たカテゴリセット(集合)に含まれていれば、当該記事は、当初指定したカテゴリ以下の記事として属すると言えます。