1. 概要

この論文では、拡散モデル(diffusion models)を応用して与えられたテキスト情報に合わせて画像を生成する、「コンテキスト学習」を実現する新しいフレームワークとしてプロンプト拡散手法(Prompt Diffusion)を提案している。コンテキスト学習(in-context learning)とは、与えられた情報(コンテキスト)を基に、モデルが新しいタスクを学習・実行できるようにすることを指す。
プロンプト拡散手法では、未知の画像変換タスクに対しても画像の事例とテキストによる指示で高品質な画像を生成することができる。特に、学習済みのタスクに対して高品質な画像生成を行うだけでなく、新しいタスクに対しても対応するプロンプトを与えることで適応することができるよう拡張されている。
*Spotlight Poster
2. 新規性
従来の拡散モデル(diffusion models)では、例えば、ボケた画像から鮮明な画像を復元するなど、特定のタスクに対してのみ学習されていた。提案手法である「プロンプト拡散手法」では、テキストによるガイダンスを用いて、モデルが新しいタスクを理解して実行できるようにしている。
3. 実現方法
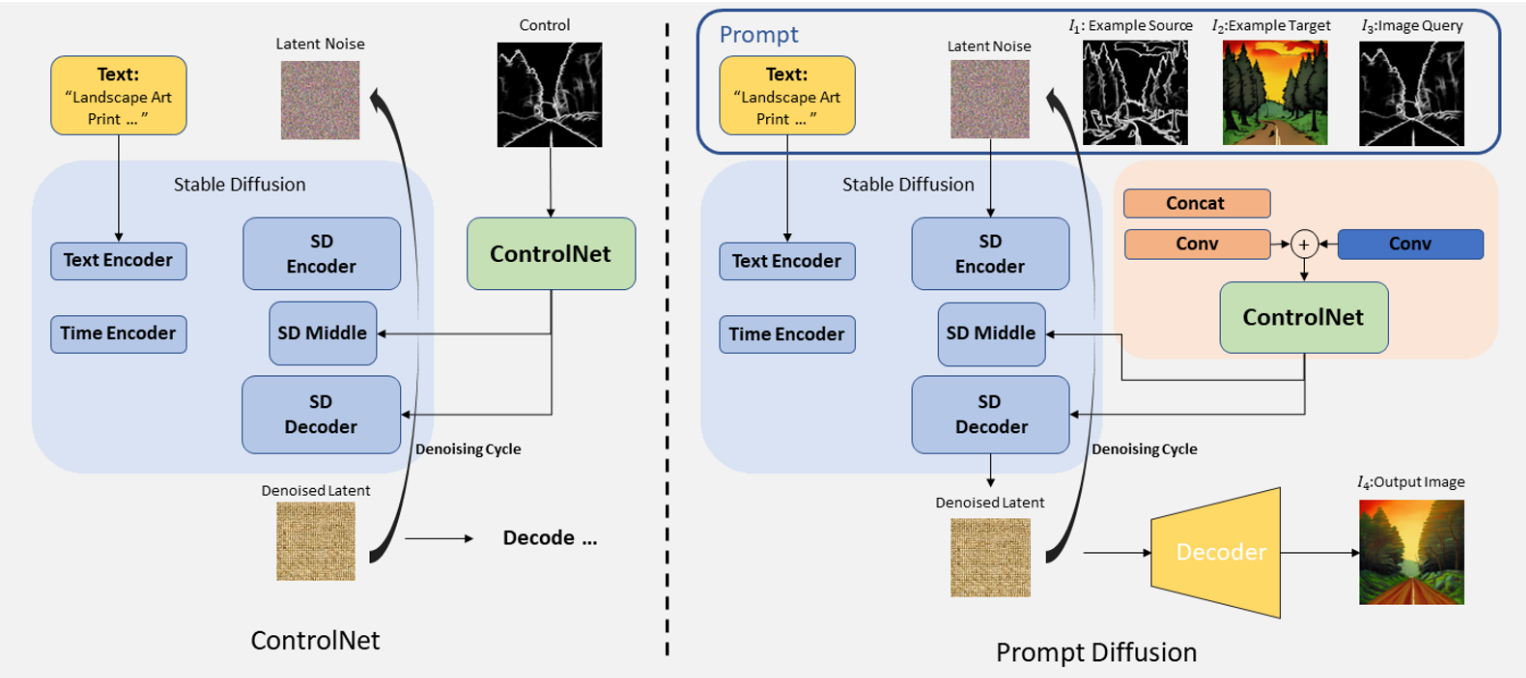
- Visual-Launguage Prompt: テキスト形式でタスクの内容を表現する。例えば、「深度画像(depth map)から通常の画像に変換する」や「落書き画像(scribble)から詳細な画像に変換」といったタスクを入力することで、プロンプト拡散手法では変換手法のタスクを理解することができる。
- Diffusion Models: 複数のタスクに対して、それぞれに対応するVisual-Language Promptを用いて学習されている。プロンプトは、拡散モデルの生成結果を望ましい画像に誘導するようガイダンスとして機能する。
4. 結果

深度画像(depth map)や画像のエッジマップ(edge map)や分割マップ(segmentation map)を入力にして、未知の深度画像やエッジマップや分割マップから画像のスタイルを事例のように反映して編集し画像を自動生成することができている。事例となるペアを入力するため、ドメイン内タスク(In-Domain Tasks)と呼ばれる。

テキスト内に変換の指示を記載する場合、事前に学習されたドメインと異なる表現であっても、入力の事例を基に生成することができる。これを学習外のドメインタスク(Out-of-Domain Tasks)と呼んでいる。
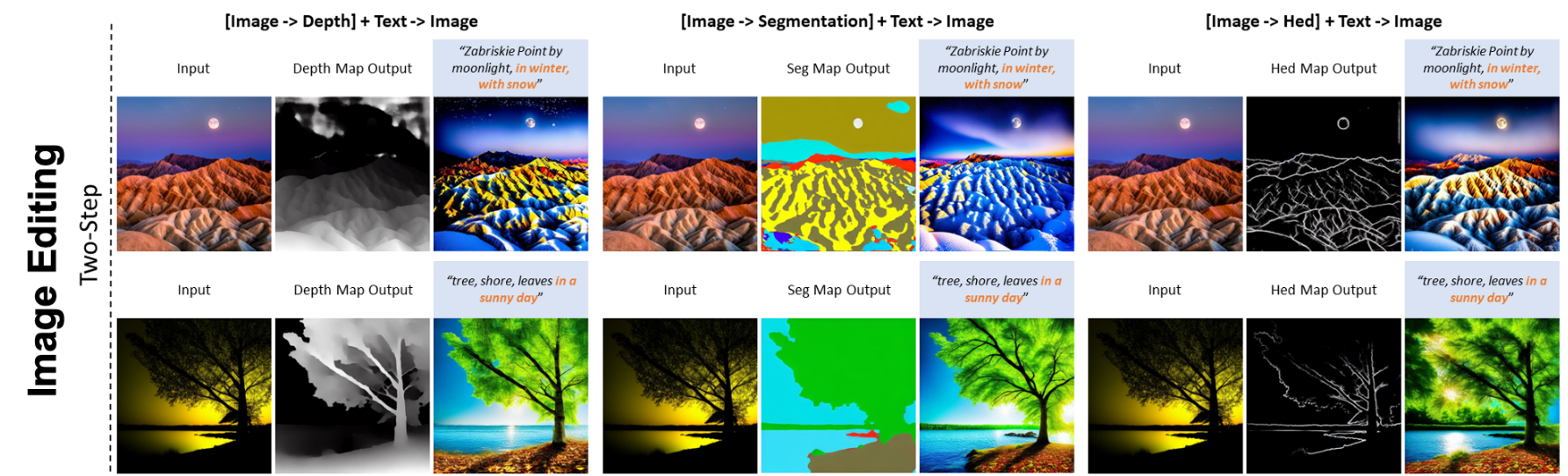
同じ画像の異なるコンテキスト情報を入力として、画像編集をすることができる。
Paper URL: https://openreview.net/forum?id=6BZS2EAkns
last updates: Apr. 18 2024