1. 概要
画像中にあるすべての物体を個別に編集するためのツールを提案している。物体を一つずつ検出して領域する技術をセマンティックセグメンテーションといい、この研究では物体をセグメンテーションマップを使ってユーザーが自由に切り貼りしたり移動させたり柔軟に編集することを可能にしている。
2. 新規性
既存研究では、物体と背景とを同一のニューラルネットワークを使って分離していたため、編集後の画像の背景が歪んでいたり前景の物体のテクスチャの一貫性がなくなったりしていた。この研究は前景の物体と背景とで専用のサブネットワークを構築することで、複数物体が集まっているシーンや一貫した背景を持つシーンの生成に成功している。
3. 実現方法
-
背景の生成モデル
既知の背景領域から生成対象の領域に特徴をマッピングすることで、空や木々などの背景を個別に分離してそれぞれの領域を予測する。
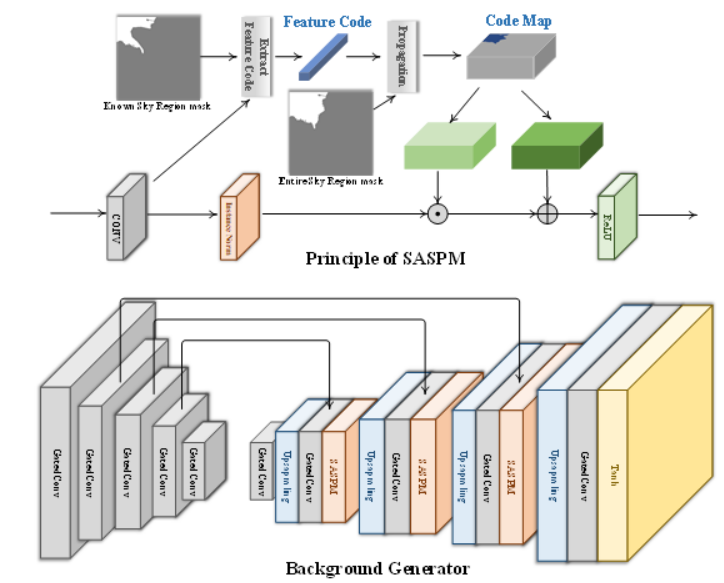
-
前景物体の生成モデル
対象物体を画面から消すインペインティング編集と、物体を増やすジェネレーション編集の用途に分けてネットワークを構築している。各物体は個別にクロッピングされ、部分的にオクルージョンなどで欠けている物体はインペインティング用のネットワークを用いて物体領域を予測し、全部見えている場合はスタイルに頑健な物体生成用のネットワークを用いて物体を生成する。
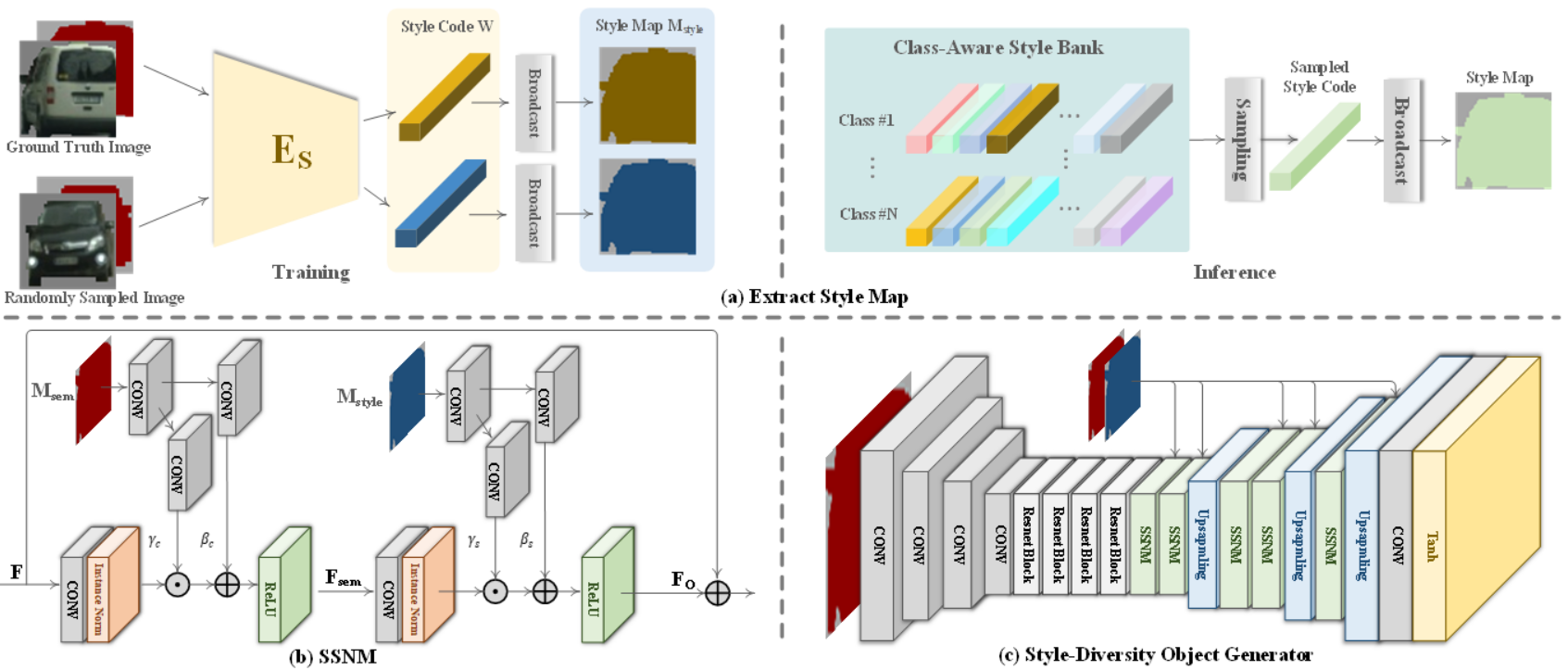
-
前景物体と背景の合成モデル
個別に生成した物体を元の位置に埋め込み、周辺領域や背景とシームレスに合成することで合成後の画像のクオリティを向上させる。
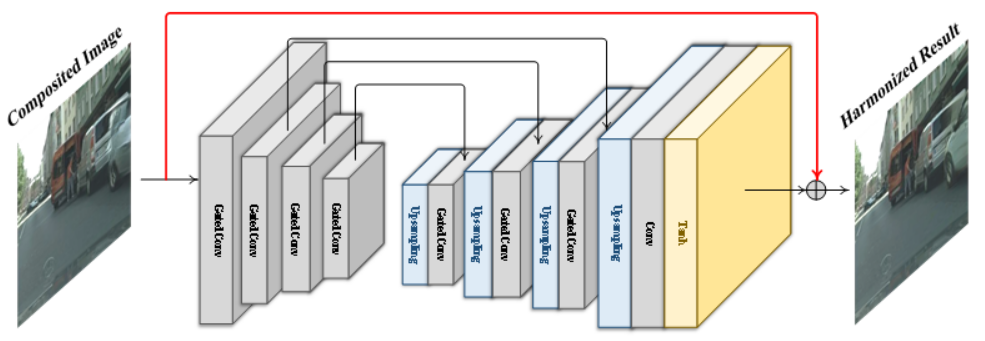
4. 結果
CityscapesとADE20K-Roomのデータセットで既存手法と比較実験を行っており、提案手法ではより多様な物体が編集可能になり、より背景のテクスチャに一貫性を持たせることができるようになっている。

last updates: June 18 2023