1. 概要

画像内の異なる物体や領域を識別し、それぞれに対応するピクセルを分割するタスクのことをセグメンテーションという。提案手法では、プロンプト可能なセグメンテーション手法を提案しており、例えばテキスト・マーカー(点)・矩形・手書き教師(物体の一部を塗ってAIに教える)などの複数のユーザー入力が可能となっている。
*BEST PAPER HONORABLE MENTION
2. 新規性
- プロンプト可能なモデル:画像認識の分野で初めて複数のプロンプト可能なモデル(promptable model)を提案している。全く未知の画像分布を持つデータに対して、ゼロショットで対応するためにユーザーが複数の教師を与えることで正確に推論できるように設計されている。
- 大規模データセット:これまでのデータセットと比べて圧倒的に大規模なセグメンテーションデータセットを公開している。データセットには10億枚の画像があり、そのうち1100万枚には精緻なマスクアノテーションをつけている。なお、公開データセットはプライバシーやライセンスに考慮してデータ収集されている。
- ゼロショット推論性能:事前のトレーニングデータが無い場合でも推論できるように、10億枚もの画像で汎化性を持ってネットワークがトレーニングされており、従来の完全教師有りのモデルと同等性能を達成している。新しいタスクに対しても事前学習が不要でゼロショット推論できる汎化性がある。
3. 実現方法
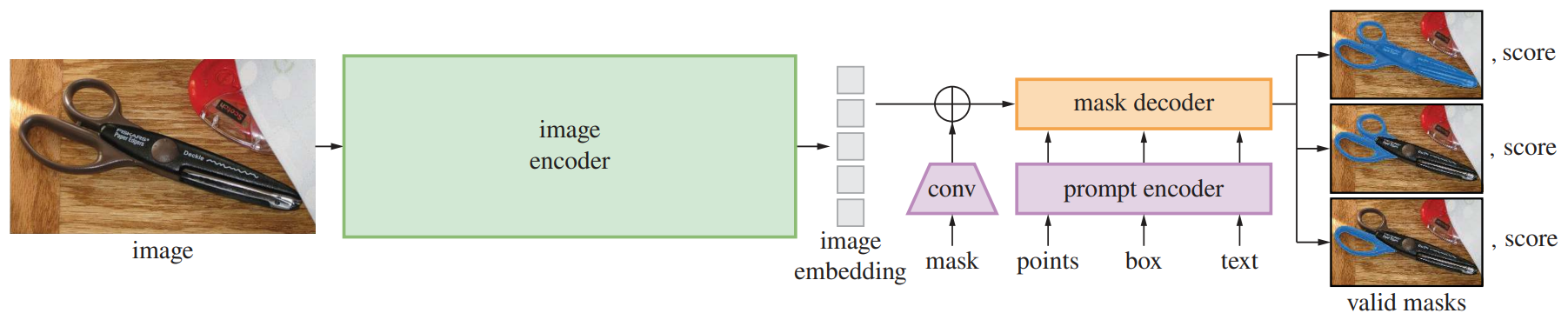
モデルは、プロンプトと画像を入力としてマスク結果を出力する。ユーザーからのプロンプト教師を受けてリアルタイムに推論できるようマスクエンコーダーが軽量化されている。Mask/Points/Box/Textなどの異なるプロンプト情報をトランスフォーマーを使ってエンコーディングしており、入力の画像特徴とともに同じ特徴空間で扱うことでマルチモーダルな操作を可能にしている。
4. 結果

例えば、1点のマーカーを教師としたときにSegmenta Anything Model(SAM)がどの領域を一つの物体と捉えるか実験してみると、3つの異なるレベルの領域を提示しており、ユーザーが所望するセグメンテーション結果を階層別に選択できるようになっている。

テキスト入力による領域推定も可能で、詳細を指示することで複雑なパーツの部位も精緻にセグメンテーションすることが可能。

データセット作成はSAMを使って自動化されており、等間隔にマーカーを置いて自動でセグメンテーションさせた結果を更に教師の学習データに含めるという、自動アノテーションループを実現することで、アノテーションコストを限りなく少なくすることに成功している。

データセット内のアノテーションのクオリティは非常に高く、このモデルの汎用性の高さを伺い知ることができる。

従来手法との複数データセット間の比較結果からも、提案手法の汎用性の高さが示されている。
Paper URL: https://openaccess.thecvf.com/content/ICCV2023/html/Kirillov_Segment_Anything_ICCV_2023_paper.html
last updates: Oct 8 2023