1. 概要

複数のカメラから3次元シーンを再構成するNeRF(Neural Radiance Fields)は画像だけでなく、動画へも拡張することができ、任意視点でレンダリングできるため自由度が非常に高い。しかし、従来手法は計算コストとシーンのセマンティック理解の両面で課題があった。
この研究では、高精度なセマンティックセグメンテーションモデルを利用して物体の領域情報を抽出し、複雑な動きのあるシーンでもレンダリングでき、かつ主体となる物体のトラッキングを3次元再構成した動画シーンから実現するGear-NeRFを提案している。
Gear-NeRFは、シーンの動きの大きさに基づいて動的領域を階層的にモデリングする"Gear"の概念を導入しており、各領域の動きに合わせて時空間サンプリングの解像度を調整することで、よりリアルな動画の3次元空間における任意視点のシーン再構成を実現している。さらに、従来のNeRFベースの手法では実現できなかった主体となる物体のトラッキングも可能になった。
*Highlight Poster
2. 新規性
- セグメンテーション情報に基づく時空間セマンティック情報の学習:
シーンの背景と動きのある前景とを効率的に把握できる - "Gear"の概念:
動きの大きさに応じた階層的モデリングにより計算リソースを効率的に利用 - 自由視点での物体追跡:
従来は困難だった任意視点での物体追跡を可能にした
3. 実現方法

動きのある領域を前処理で"Gear"として抽出しておき、各"Gear"に対して4次元(時空間)の特徴量ボリュームを構築して動きのある領域を時間方向に埋め込んだ表現にする。次に、META社の提案したSAM(Segment Anything Model:ICCV2023)を利用して領域分割を行い、動きの大きさに応じてシーンを複数の"Gear"に分割し、各ギアごとに最適な時空間解像度でNeRFを学習する。
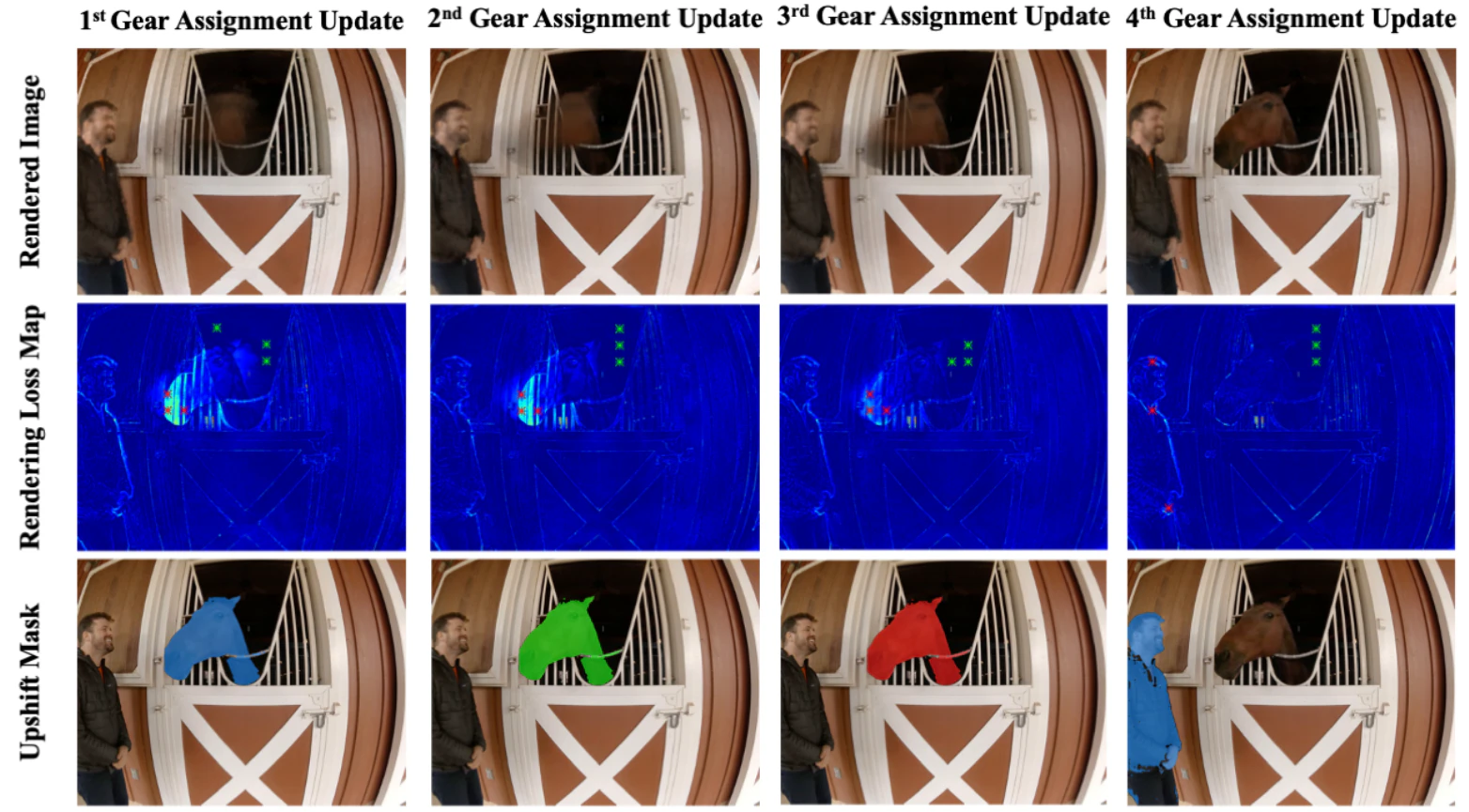
動きの大きな領域は再構成ロスを高く設定し、高解像度の時空間での生成結果を得る。物体追跡(tracking)については、クリック操作で追跡対象を選択しその物体領域だけをセマンティックセグメンテーションで領域分割し、時間方向に連続してレンダリングすることで動画にする。
4. 結果

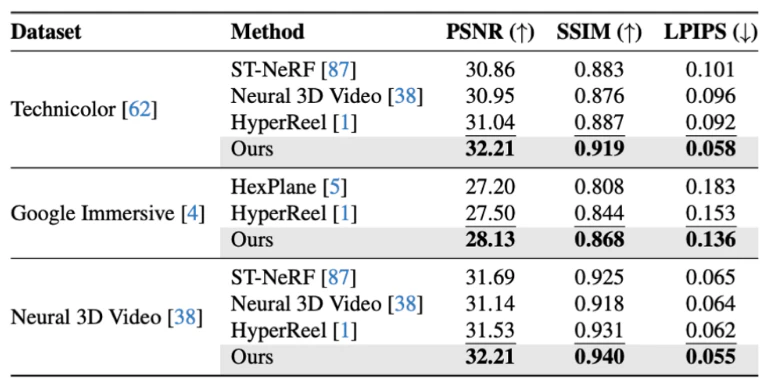
レンダリングに関する性能評価では、複数のベンチマークデータセットにおいて、従来手法と比較してより高品質な任意視点画像を生成できている。


トラッキングに関する性能評価では、セマンティックセグメンテーションを利用したことで動的シーンにおける物体追跡が可能となり、高い追跡制度を達成した。
last updates: June. 18 2024