1. 概要

連続したフレーム間で3次元空間内の物体や環境の動きを把握する技術のことを、Scene Flow Estimationという。具体的には、2つの時間的に連続したフレーム画像から、各画素における物体の3Dモーションや深度情報の推定に用いられ、この研究では単眼カメラを使った自己教師有り学習(Self-Supervised)を実現している。
2. 新規性
従来の自己教師有り学習によるScene Flow Estimationの精度を大きく上回っており、完全教師あり学習のパフォーマンスに肉薄している。
3. 実現方法

Ego-Motion Aggregation(EMA)モジュールが新たに提案されており、視点の変化(Ego-motion)の情報集約を行うことで3次元のモーション変化に対して正確な位置補正に寄与している。EMAはシーンの中で静止している物体領域を特定するRigidity Soft Maskとシーンの動きのある物体領域を特定するSE3 Motion Fieldとを組み合わせて構成されており、特に静止領域に対して視点の変化に頑健になっている。
また、モーションの一貫性を考慮したロス設計や正則化ロス、勾配分離手法やシーン再合成手法など効果的な学習プロセスが複数組み込まれている。
4. 結果
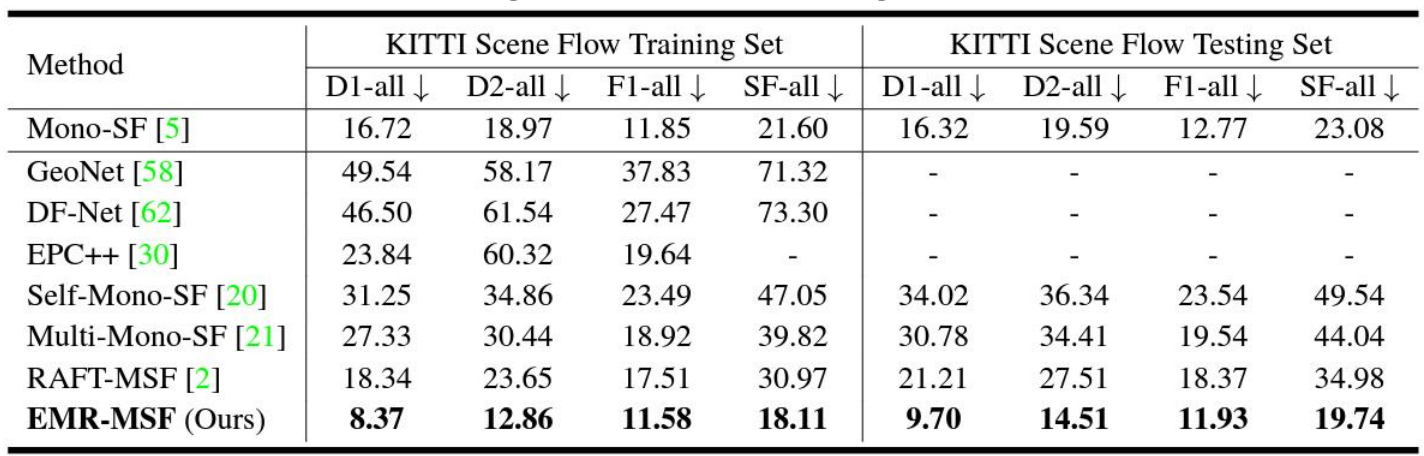


KITTI Scene Flowベンチマークでは、単眼カメラを用いた既存の自己教師有り手法と比べて、SF-allで性能が44%向上している。深度推定や自己位置推定などのサブタスク全体で優れたパフォーマンスを示している。
last updates: Oct 9 2023