1. 概要

あるシーンの画像に対して対象物体のモーションフィールドを予測することで、静止画をシームレスにループする動画に変換したり、ユーザーが画像内の物体をインタラクティブに動かしたりすることを可能にした研究。従来手法では、動画の生成は計算コストが高く時系列に滑らかに連続した動画を作ることが難しかった。提案手法では、木々・花・ろうそくの火・風に揺れる衣類など、自然界における振動を撮影した動画から動きのある箇所の軌跡のデータセットを用いて学習を行っている。画像空間におけるシーンモーションの事前分布をモデリングするために、動き情報をフーリエ領域におけるスペクトルボリュームとしてモデル化し、拡散モデル(Diffusion model)を用いて動画全体に渡るモーションテクスチャを予測する。
*BEST PAPER AWARD
2. 新規性



- 自然な振動運動に特化したモーションの事前分布予測
従来は物体やカメラの移動など一般的な動きを対象としていたが、提案手法では自然界に広くみられる振動運動に焦点を当てている。 - フーリエ領域におけるスペクトルボリューム
振動運動の周期性と空間的な相関を捉えるために、周波数空間で特徴量を表現するスペクトルボリュームを採用している。 - 拡散モデルによるモーション予測
スペクトルボリュームの予測に拡散モデルを用いており、複雑なモーションパターンを生成でき多様な動きの再現を実現している。
3. 実現方法
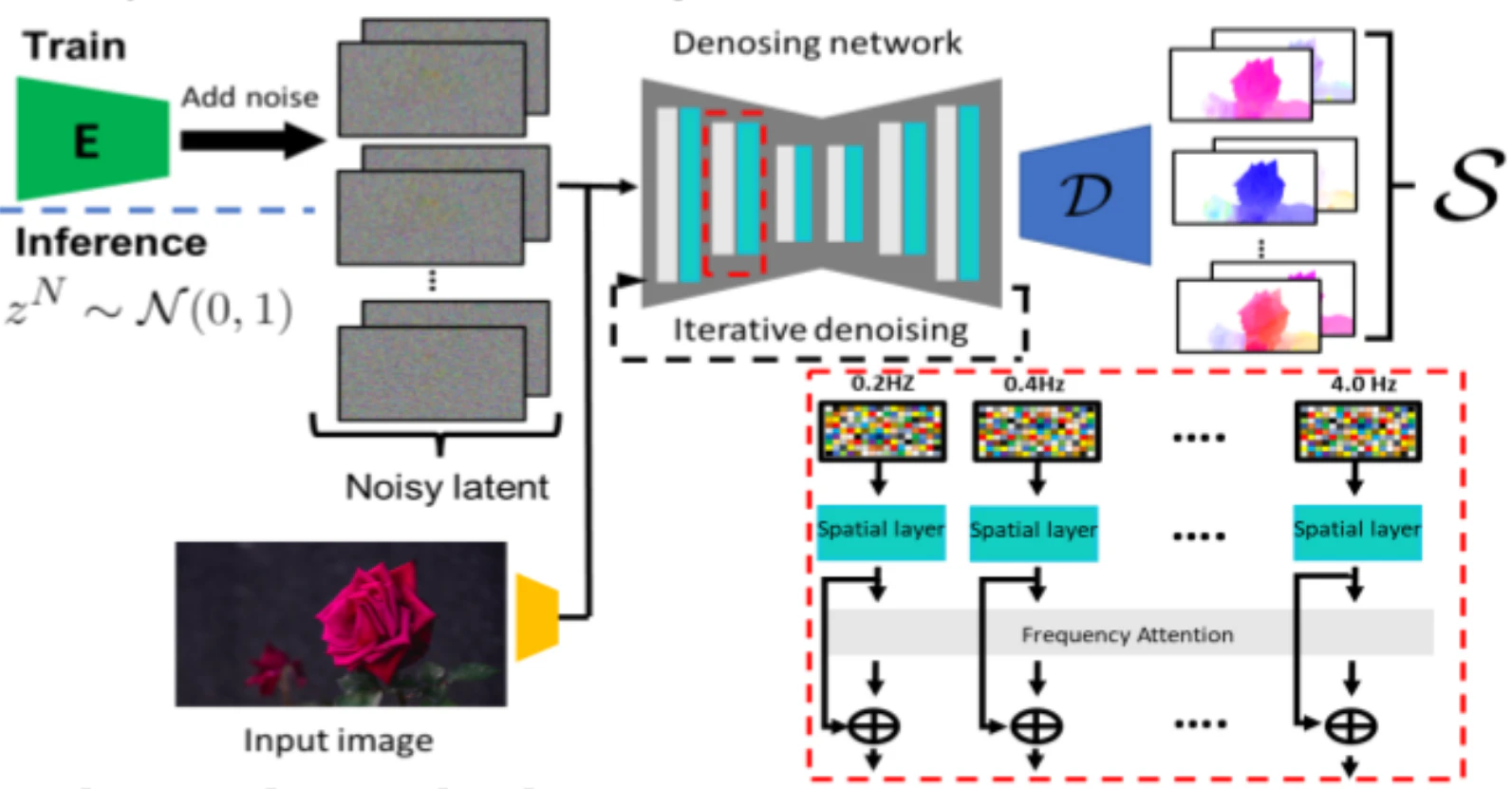
動き予測モジュールでは、周波数座標系におけるノイズ除去モデルを用いてスペクトルボリュームSを予測する。拡散ネットワークθの各ブロックでは、2次元空間層(Spatial layer)とアテンション層(Frequency Attention)を交互に配置しており、潜在特徴Zを段階的にノイズ除去していく。除去された特徴はデコーダDに入力され、スペクトルボリュームSが生成される。
学習時には、ダウンサンプリングされた入力画像Iと実際のモーションテクスチャからエンコーダEによって符号化されたノイズを含む潜在特徴を連結する。推論時には、ノイズを含んだ特徴の代わりにガウシアンノイズZを用いる。
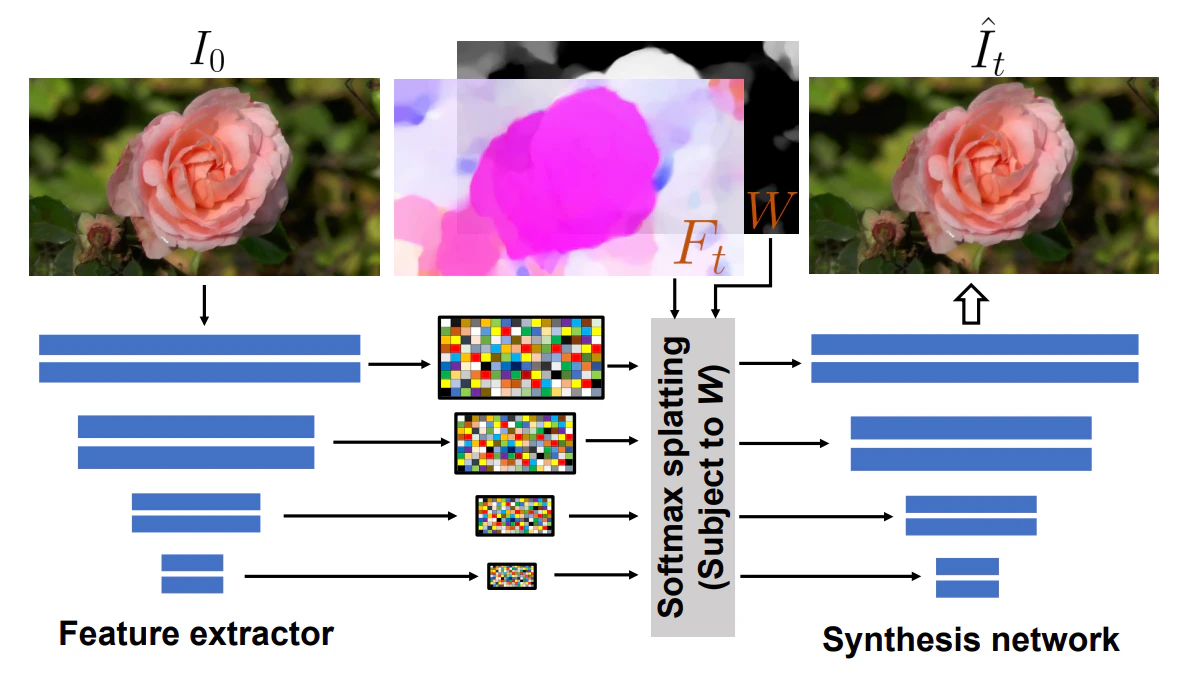
レンダリングモジュールでは、ディープラーニングを使ったレンダリングで欠損領域を補完し、画像を動かして引き伸ばされた領域の詳細を精緻化する。入力画像Ioからマルチスケールで特徴量が抽出され、次に予測した時間0からtまでのモーションフィールドFtを用いて、抽出された高次元特徴量に対してモーションブラーやオクルージョンによる欠損を考慮した画像合成手法であるソフトマックススプラッティングを適用する。対象を動かして引き伸ばされた領域の特徴量をソフトマックス関数を使うことで滑らかにすることができる。マルチスケールな特徴量を合成してレンダリング画像Itを生成する。
4. 結果

生成された動画は従来手法よりも時系列に沿って滑らかに連続しており、動きも自然界の周期性を学習しているため非常に自然に見える。

画像をある行のピクセル(青線)だけ抽出し時間方向に沿ってどのように動きが生成されたかを示した図。参照画像に対し、提案手法は動きのバリエーションが多く最も近しい結果になっているのが分かる。
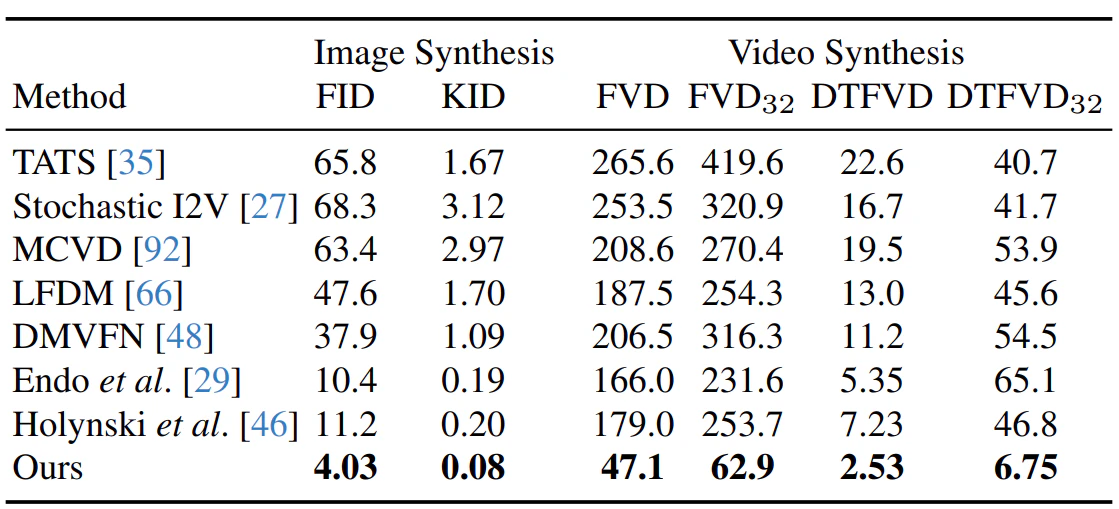
画像合成・動画合成の品質評価では、従来手法と比べて最もエラーが少ないことが分かる。
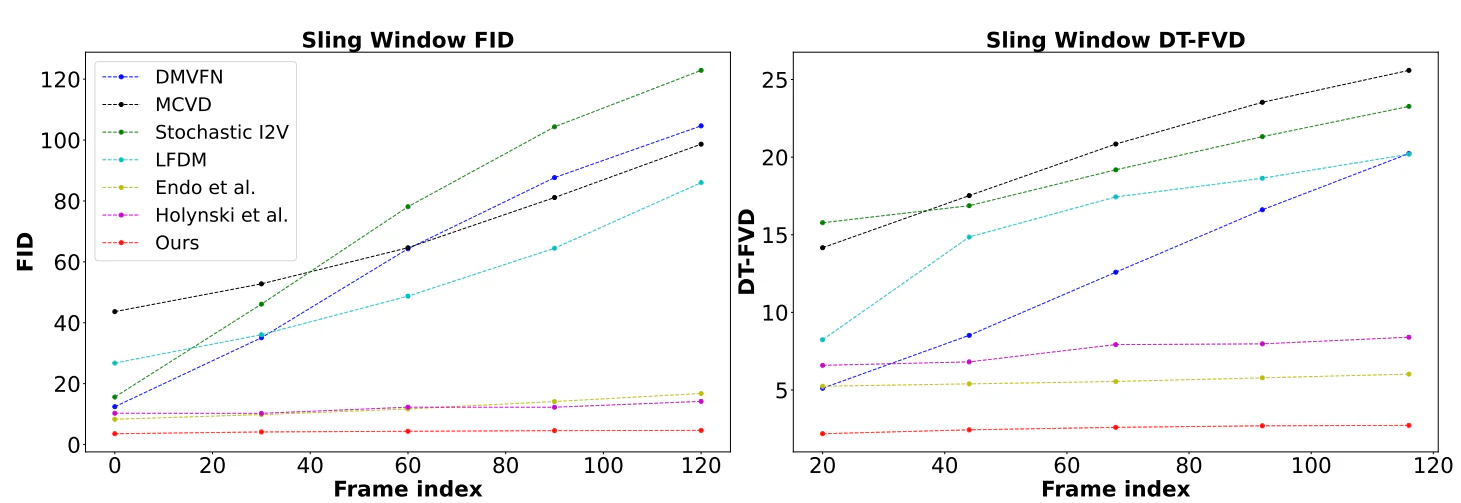
生成する動画のフレーム数を増やした場合でも、提案手法は既存手法と比べてエラーが少なく高品質な動画を生成できていることが分かる。
last updates: June. 17 2024