1. 概要
画像と指示のテキストを入力すると、所望の解析結果だけでなくどのようにしてそのような結果になったのかというコードも生成され、ユーザーにとっての解釈性を担保しつつ画像解析や編集ができるようにした研究。
*Award Candidate: BEST PAPER AWARD
2. 新規性
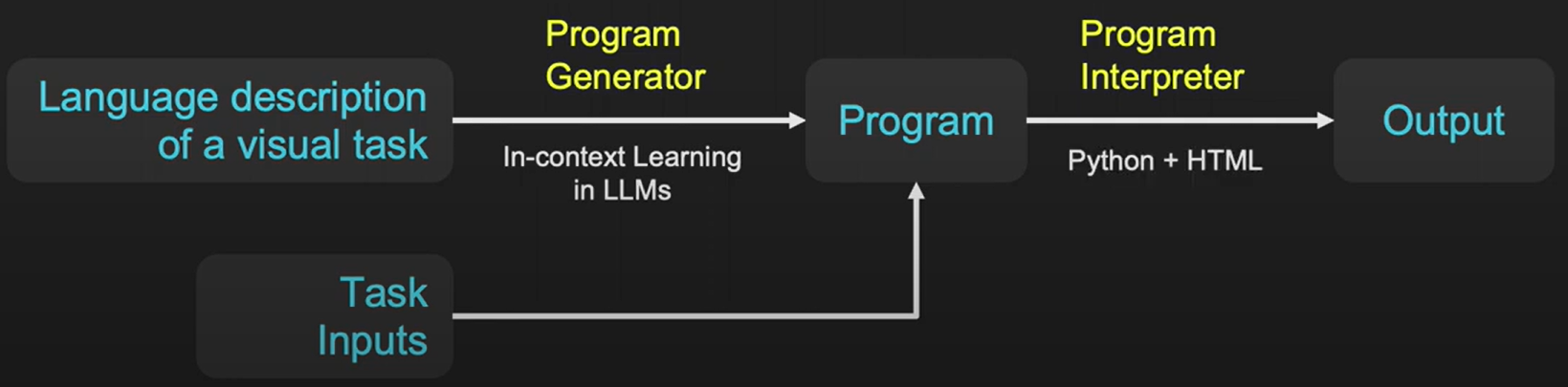
自然言語と画像を入力として直接画像生成・編集をする研究は多く研究されているが、この研究ではまず疑似プログラムをLLMを使って自動生成する。生成されたプログラムは、その命令を解くためのプログラム(python)をコールし逐次的に結果が返される。中間推論をプログラムとして生成する点が、AI推論の解釈性を高める効果がある。
3. 実現方法

テキストによる指示入力とそのコードをペアでいくつか入力し(Few-shot Examples)、実際に指示したい内容をテキストで実行するとそれを実現するためのコードが生成される。ここで、GPT-3を使って指示内容のテキストからコードを生成するが、一切ファインチューニングは必要としない。HuggingFace/Pytorch/Tensorflowなどのニューラルネットワークのモデルがコールされるので高度なコンピュータビジョンタスクも解ける。また、PIL/OpenCVなどのライブラリもコール対象で画像処理も同様に解くことができる。
4. 結果




自然言語による画像編集や画像から論理的な推理をするタスク、写真内に写る物体の自動タグ付け、画像情報に対する質疑応答などの処理が実現できる。
last updates: June 30 2023