1. 概要
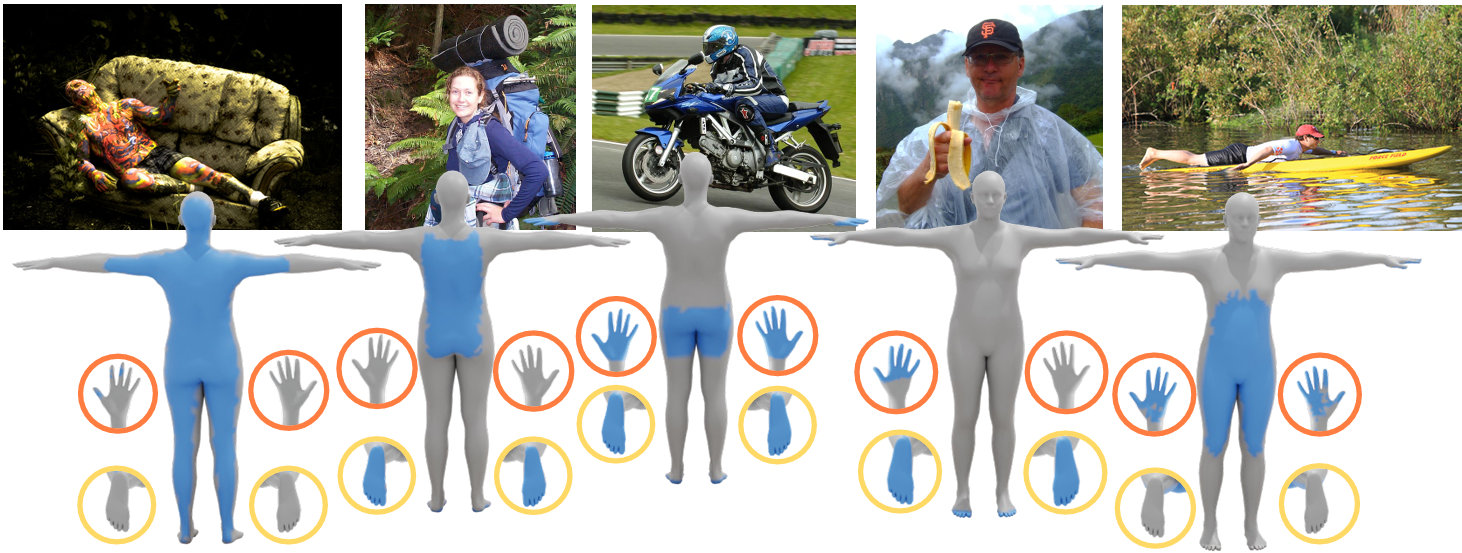
2Dの画像から3Dのヒューマンモデルを作成し、かつどの部位が他の物体と接触しているかを推定する技術を提案している。デジタルツインなどの実用化には、人体モデルが他の物体とどのようなインタラクションを取っているかを自動推定できることが重要となる。従来方法では、荒い3Dモデルしか対応できない、2D空間のみで最適化させている、人体モデルの関節ではなく表面のみ考慮している、汎用性が乏しく現実世界の様々なシーンに適用できない、などの制約があった。
2. 新規性
任意の現実世界の2D画像に対して、3Dの人体モデルを生成し、かつ接触している物体との領域を正確に推定している。
3. 実現方法
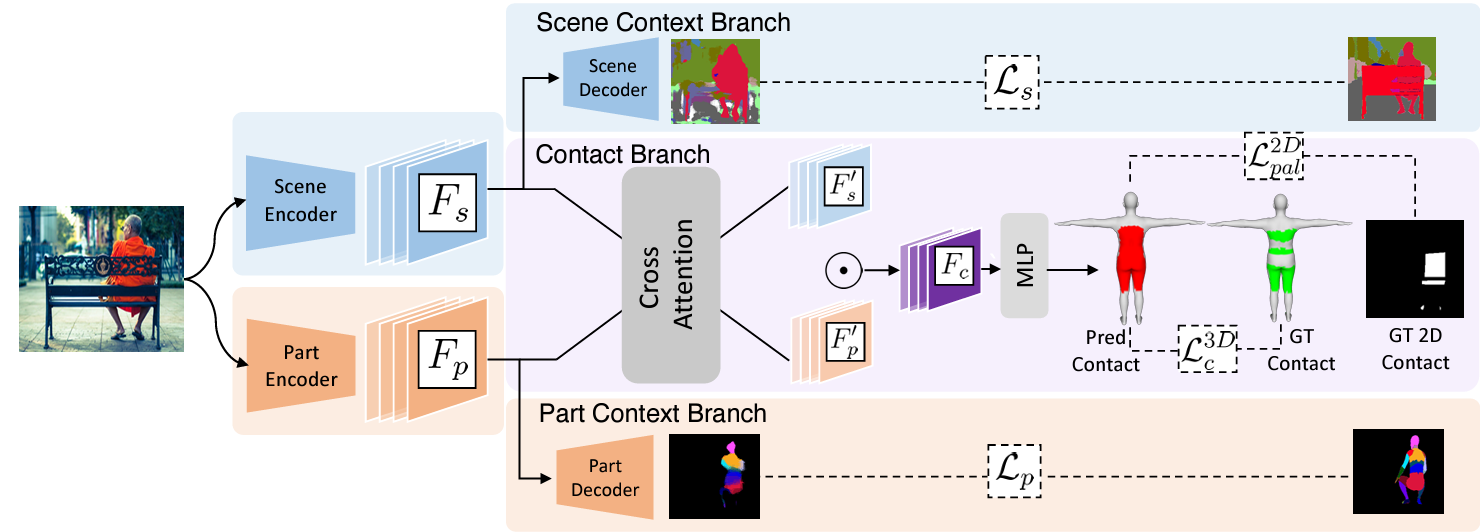
入力画像に対して、シーン特徴を抽出するエンコーダーとボディパーツ特徴を抽出するエンコーダーから異なる特徴を得る。シーンコンテキストを予測するブランチではセグメンテーションを行い、各物体を正確に切り分けて予測する。ボディパーツのコンテキストを予測するブランチでは人体モデルの各部位をセグメンテーションする。人体の部位と物体との接触部分を予測するブランチでは、各物体と人体の各パーツがどこで接触しているかをクロスアテンションを用いて重みづけしてガイドを与えている。接触部位は正解値との予測が最小になるようにLossを設けるだけでなく、2D画像のセグメンテーション結果ともLossを設けることで、未知の2D画像の入力に対して3Dモデルの体表面でどこが接触しているか正確に求められるようにしている。
4. 結果
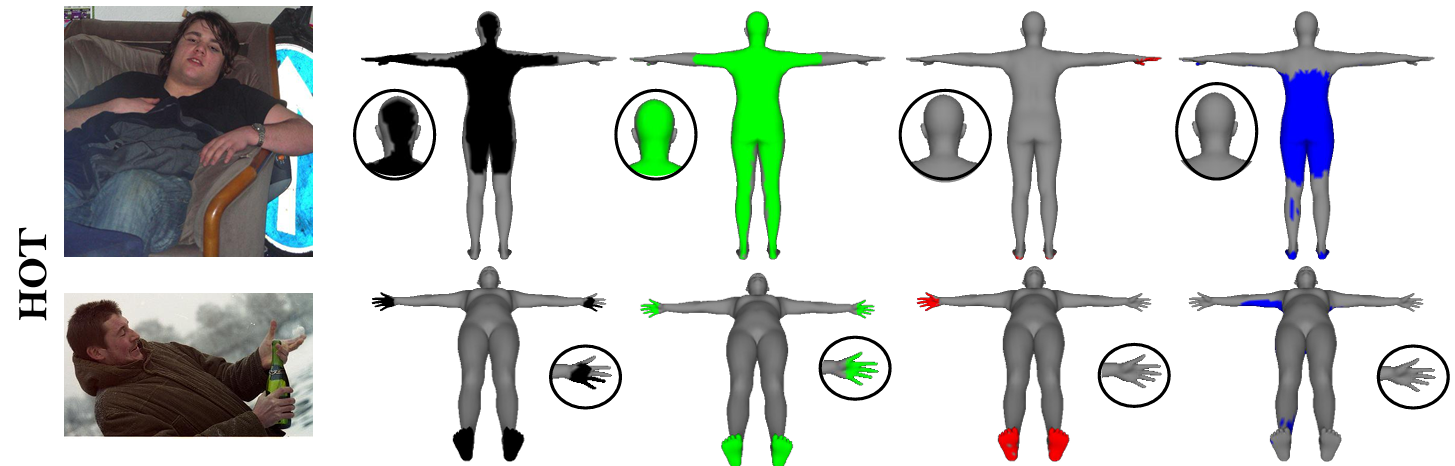
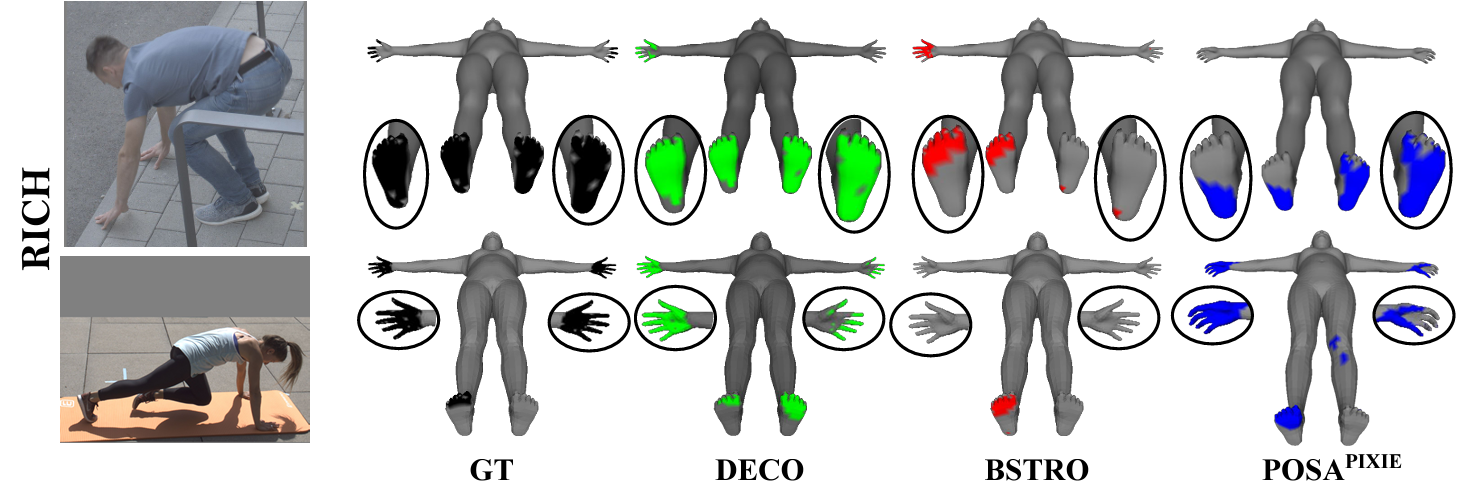
提案手法"DECO"は従来手法と比べて高精度に周囲の物体との接触部分を予測できていることが分かる。

RICH/DAMON/BEHAVEといった各種データセットに対しても、既存手法と比べて大幅な精度向上を達成している(SOTA達成)。
last updates: Oct 10 2023