1. 概要

テキストによる画像生成や編集では、制約を与える条件付きモデルがよく用いられる(Conditional Generative Models)。一方、高品質な生成結果を得ようとすると大規模なアノテーション付きのデータセットが必要となってしまう。そこで、この研究では追加の学習を一切必要としないゼロショットの条件付き画像生成モデルを提案している。一般的によく使う画像生成モデルに組み込むことができ、特定のタスクに特化した学習を一切必要としないため、アーキテクチャに対する依存性が無く使い勝手がよい。
2. 新規性
特定のタスクに特化した学習を必要としないSteered Diffusionを提案している。
3. 実現方法
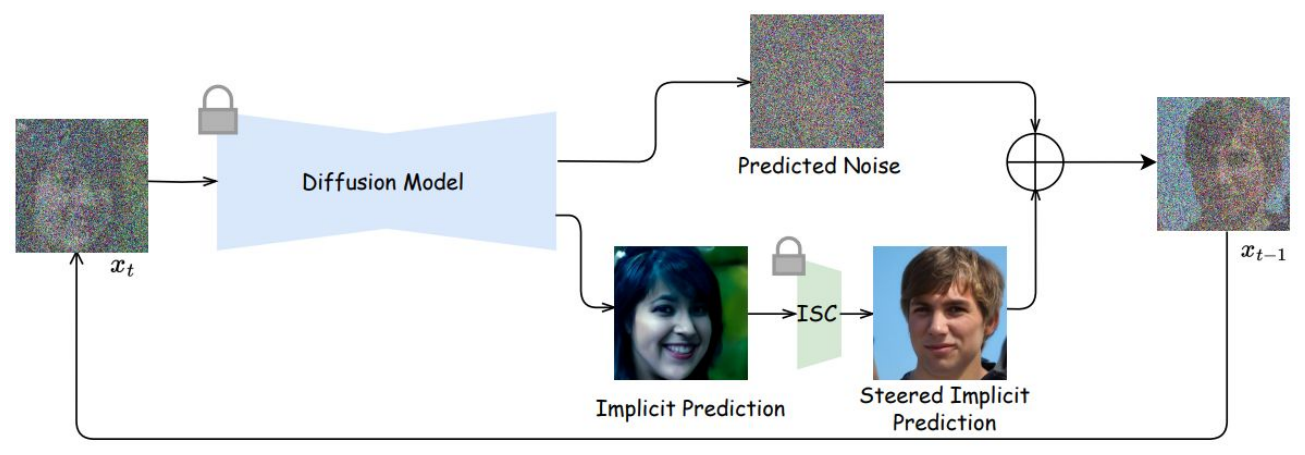
Diffusion ModelをFreezingした状態で特徴量抽出器のように用いる。各サンプリングステップtでは、学習データを用いた明示的なモデリングではなく、暗黙的な特徴を学習できるようにしている(Implicit Learning)。これにより、ノイズの少ない画像のおおよその推定結果(Implicit Prediction)を予測できるようにしている。さらに、その結果を提案手法であるImplicit Steering Control(ISC)アルゴリズムを用いて制約条件を付与していく。
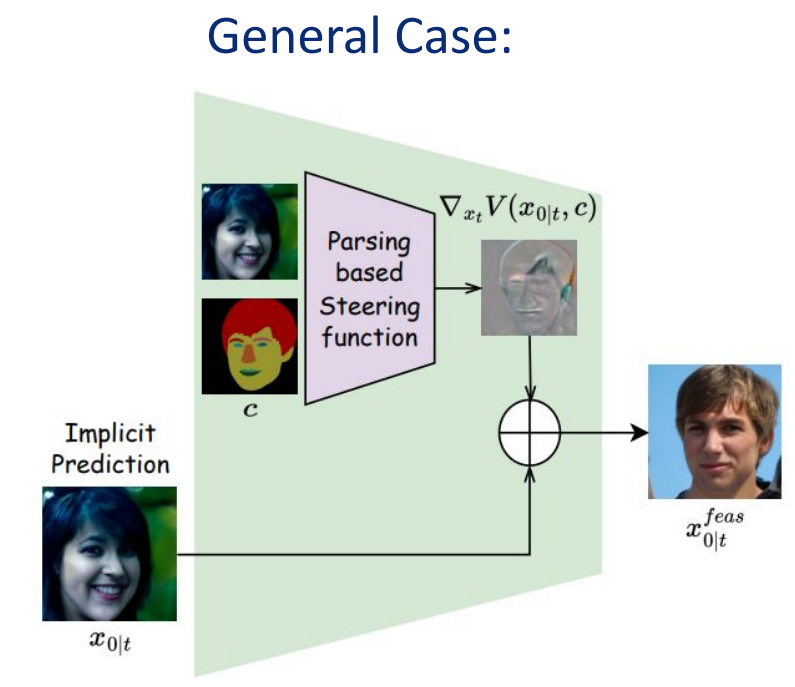
制約条件を与えると、出力結果の画像空間から条件下の空間へ逆マッピングが必要となる。提案手法ではノイズの少ないImplicit Predictionの予測結果を用いて事前学習済みの凍結したネットワークを用いて条件下の画像空間へ逆マッピングを行う。
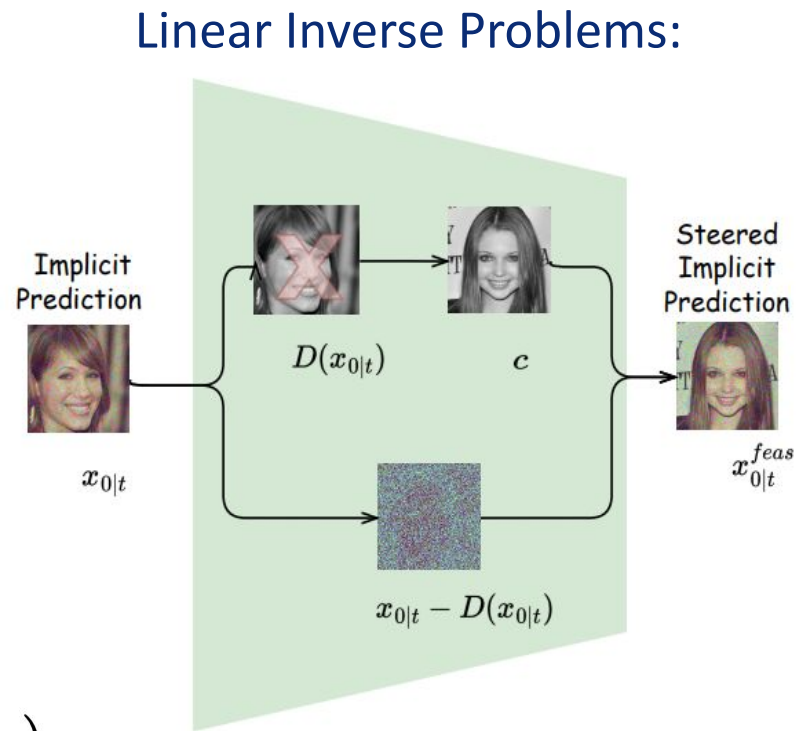
インペインティングや超解像の場合、線形逆問題(Linear Inverse Problems)を用いて、既知の線形劣化関数D(x)を用いて画像を劣化させ、その部分を条件cで置き換えてサンプリングプロセスを進める。
制約条件を考慮したノイズの少ない画像(Steered Implicit Prediction)は、次のステップのサンプリングに使用されより高品質な画像にアップデートされていく。
4. 結果


超解像(Super-Reslution)やセグメンテーション画像を実写に復元するSemantic Generation、欠損した画像を補完するImage Painting、テキストによる画像編集など、様々なタスクを追加学習なしで高品質に実現できている。
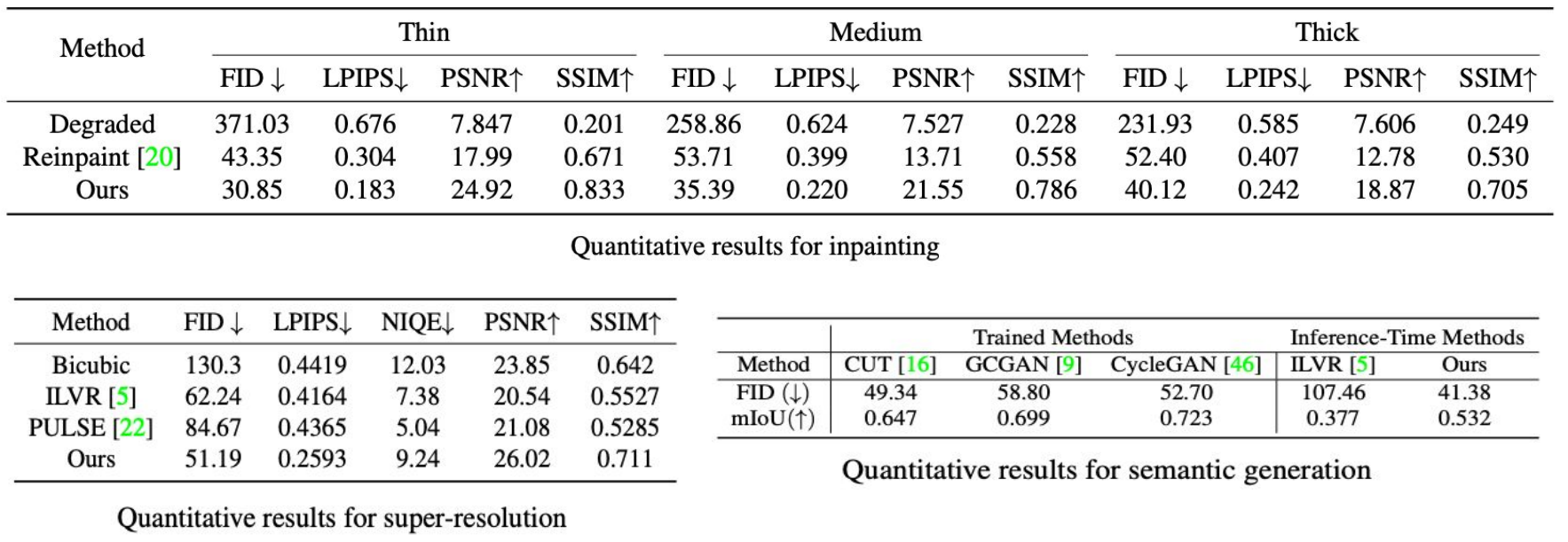
定量評価の結果も、提案手法は従来手法と比べて高品質な画像編集ができていることが分かる。
last updates: Nov 24 2023