1. 概要

近年、ドローンやスマートフォンなど手軽なデバイスを用いて高画質なカメラで撮影された自然画像が、生物学の情報の宝庫となっておりその数も急速に増している。動植物の保全活動や解明のためにこうした高解像度画像を解析する技術が多数提案されているが、既存の手法は特定のタスクに特化したものが多く、新しいデータセットやタスクに対応するのが難しかった。そこでこの研究では、画像を入力すると学術分類が自動で行えるツールを開発し、生物画像に広く適用できる汎用的な画像認識モデルを提案している。
提案手法では、まず生物画像の大規模データセットである"TreeOfLife-10M"を構築し公開している。機械学習に適した形式でアノテーションされており、過去最大規模かつ最も多様な生物画像データセットとなっている。さらに、このデータセットと生物学的知識体系である"Tree-of-Life(生命の樹)"を組み合わせることで、生物画像のための基盤モデルである"BioCLIP"を提案している。TreeOfLife-10Mデータセットを用いて、植物・動物・菌類などの豊富で多彩な画像と、構造化された生物学的知識を組み合わせることで、従来手法を大幅に上回る認識性能を達成している。
*BEST STUDENT PAPER AWARD
2. 新規性
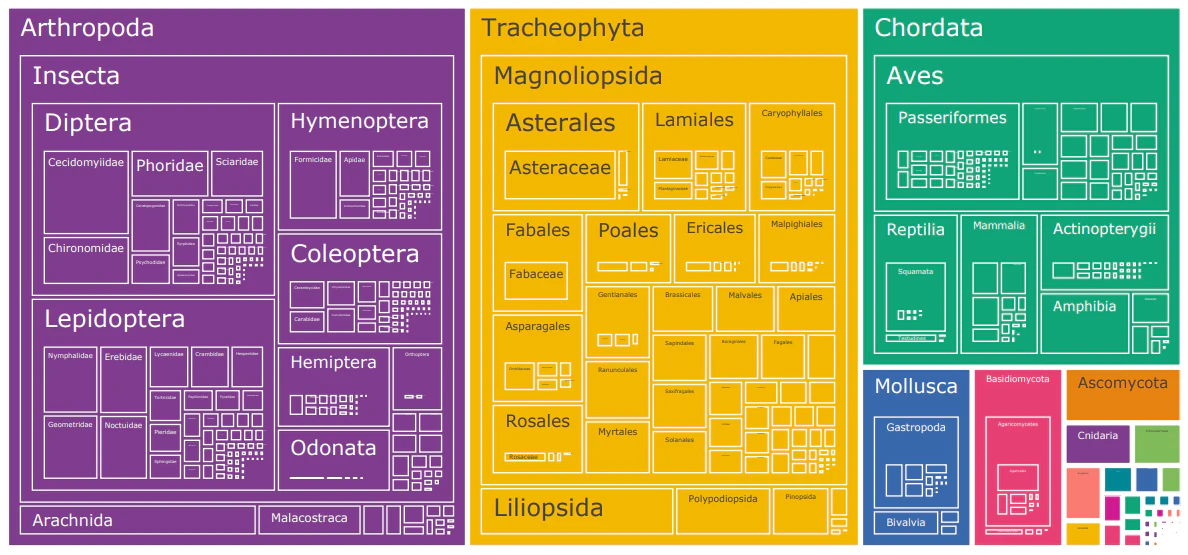
- 大規模データセット"TreeOfLife-10M"の公開
- Tree-of-Life(生命の樹)に基づいた大規模基盤モデル"BioCLIP"の開発
3. 実現方法
インターネット上の画像や既存のデータベースから、植物・動物・菌類などの画像を収集し、分類してラベル付けを行い、機械学習に適した形式に成形している。このデータセットを用いて、生命の樹の構造情報を組み合わせ、テキストと画像を組み合わせるマルチモーダル生成AI技術であるCLIP(Contrastive Languagte-Image Pretraining)アーキテクチャに基づいたBioCLIPモデルを学習させている。

例えば、よく似たシダ植物を入力とした場合、分類学上"種(Species)"レベルでのみ異なり、それ以外の分類レベルは同じである。自己回帰型のテキストエンコーダーは、分類学上の階層構造を符号化でき、例えば、"界(Kingdom)"・"門(Phylum)"・"綱(Class)"のトークン情報を自動で取り組むことができるが、"目(Order)"より下の階層の情報は取り込まない。これは、入力画像の視覚表現を同じ階層構造に整合するための制約になっている。
前段でテキスト情報として階層的に表現された生物分類ラベル情報は、CLIPの対照事前学習の目的関数に入力され、入力の画像表現(d)と(e)とマッチングに用いる。
*自己回帰型テキストエンコーダー:
前の単語から順番に処理していくことで、単語列をベクトル表現に変換するエンコーダー
*対照事前学習:
類似したデータペアを近くに、異なるデータペアを遠くに配置するように表現を学習する手法
4. 結果
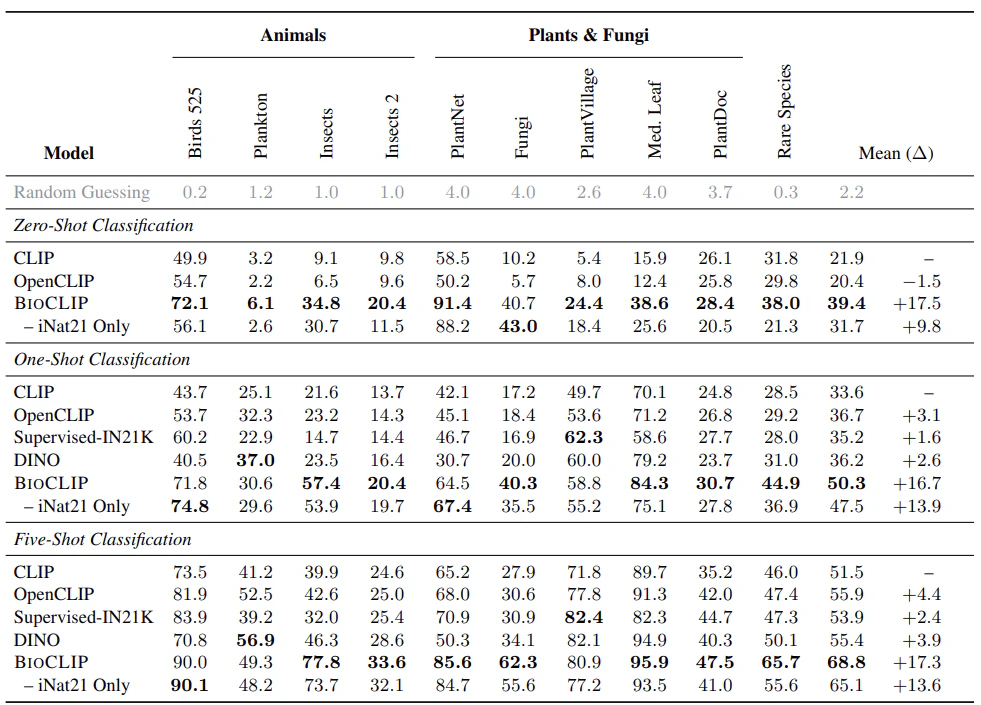
表は、異なるモデルにおけるZero-shot/Few-shot(1shot/5shot)の分類結果のTop-1正解率を示している。すべてのモデルで同じViT-B/16アーキテクチャを用いている。提案手法はCLIPと比べて17%以上正解率が向上している。
様々な生物種分類タスクにおいて、提案手法のBioCLIPは従来の画像認識モデルを大幅に上回る精度を達成した。また、BioCLIPでは生命の樹(Tree-of-Life)の構造を反映した階層的な表現を獲得しており、未知の生物種に対しても高い認識精度を達成した。
last updates: June. 17 2024