1. 概要
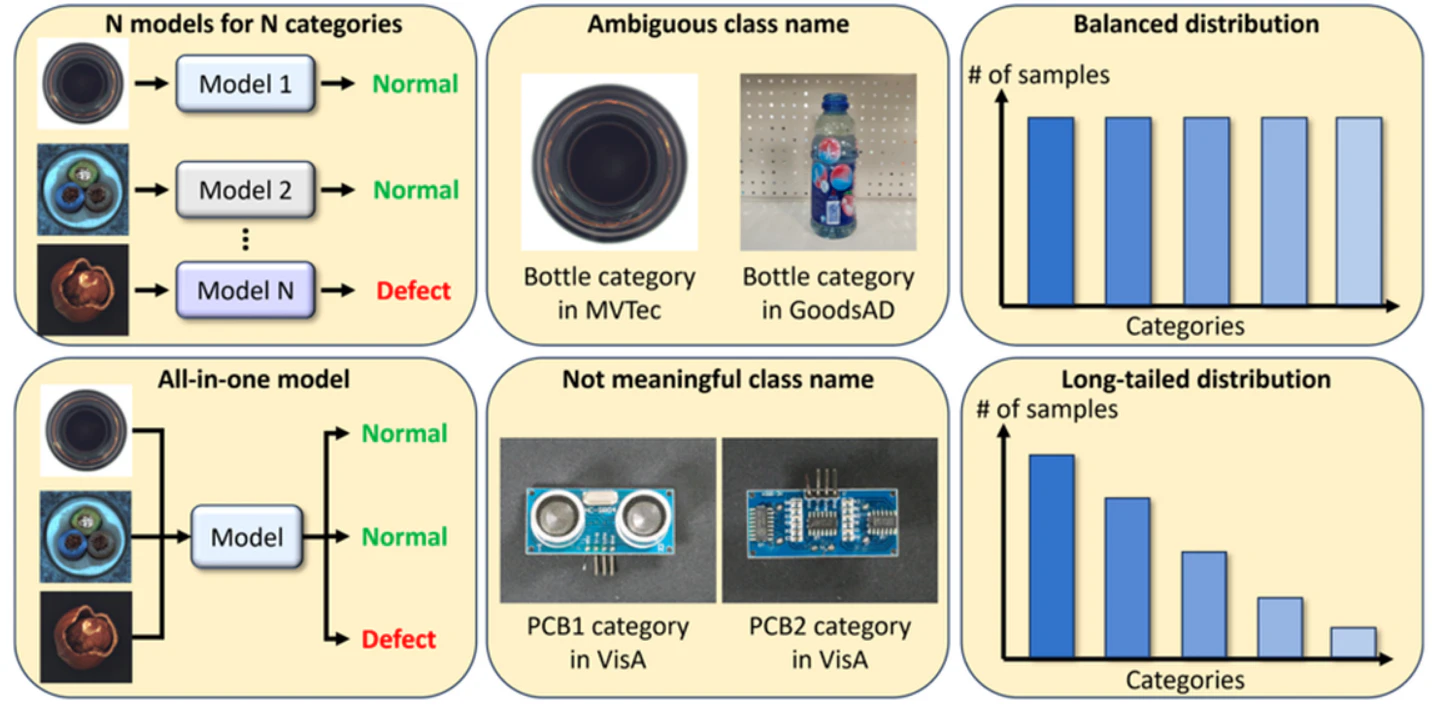
画像内から異常個所を検知する技術は"Anomaly Detection"と呼ばれ、不良品の画像を識別しその不良個所を特定するアプリケーションでよく用いられる。理想的には、異常検知モデルは以下のような能力を持っていることが望ましい。1) 多数の分類クラスに対して汎用的な欠陥検出能力、2) データセット間で一貫性の無いクラス名への対応、3) 異常データを用いない教師なし学習、4) 実世界のアプリケーションで精度を上げる際にありがちなカテゴリーごとの分布が全く違うデータ(Long-tailed Data)への対応。
この研究では、こうした異常検知の実際のアプリケーションを作成する際の課題(1)-(4)に対処するため、不良品画像のクラスの偏りが異なる複数のデータセットを公開し、性能評価の指標を新たに提案している。
2. 新規性
- カテゴリーごとに偏りが全く異なるデータ(Long-tailed Data)の異常検知の定義:
クラス分布の偏りが異なる複数のデータセットと、性能評価のための指標を導入することで、実世界のデータに即した異常検知問題を再定義している。 - 教師なし学習とセマンティック解析の融合:
従来の画像再構築ベースの異常検知手法に加えて、疑似クラス名と基盤モデルを用いたセマンティックな手法を提案しており、より高精度な異常検知を実現した。 - データ拡張による偏りの異なるデータ問題への対応:
VAEを用いた特徴量合成により、学習データをaugmentationで増やし、データの偏りによる影響を軽減している。
*Vision Autoencorder(VAE):
表現学習と生成学習の両方の性質を併せ持つ深層学習モデル。潜在空間を扱うことで、データの背後にある構造を理解し、新しいデータを生成することが可能となる。
3. 実現方法
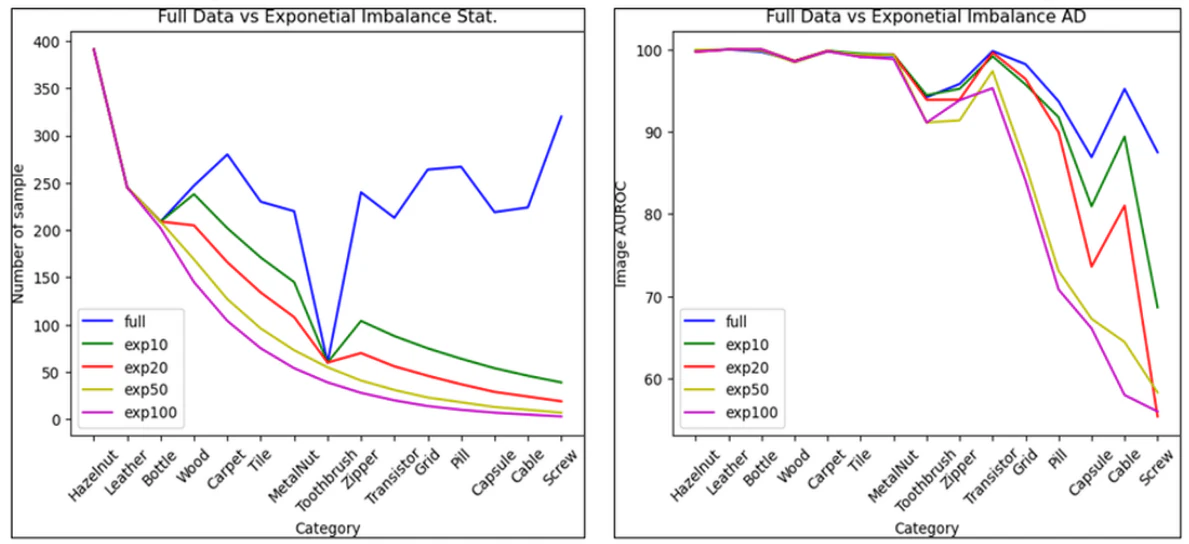
予備実験として、MVTecデータセットを全て用いたもの(青線)と徐々に各カテゴリーのデータを減らしたものの数値分布を右側に示しており、偏りを作ったデータに対する認識精度の違いを左図に示している。学習データが少ないほど認識精度も悪化する傾向にある。
学習は以下の2つのフェーズで実施している。

フェーズ1:
- クラス名は未知のため、データから疑似クラス名Scを学習する
- VAEを用いて学習データをAugmentationして増やすための特徴量合成モデルを学習する
- エンコーダー/デコーダー特徴量の再構成誤差を最小化するためにMSEロスを使用
- 潜在空間の分布を一様にするためにKLDを採用

フェーズ2:
- フェーズ1で得られた疑似クラス名と特徴量合成モデルを用いて、再構成モジュールと分類モジュールを学習する
- 正常画像の特徴マップPnにノイズを加えてPaとして、セマンティック異常検知手法(SAD)と、再構成モジュールに入力する
- 再構成モジュールでは、正常画像の特徴量マップとノイズを除去した特徴量マップのL2ノルムの差が最小になるようにMSEロスを使用
- セマンティック異常検知モジュールでは、特徴量マップをパッチに分割し、画像特徴からテキスト特徴へ変換する(P^)。フェーズ1で学習した正常画像の擬似クラス名を含む正常プロンプトVnと異常プロンプトVaをテキスト空間へ変換し、テキスト空間上で画像パッチベースの特徴(P^)と比較して異常度を算出する。ロスはBCE(Binary Cross Entropy)を各パッチに対して適用。
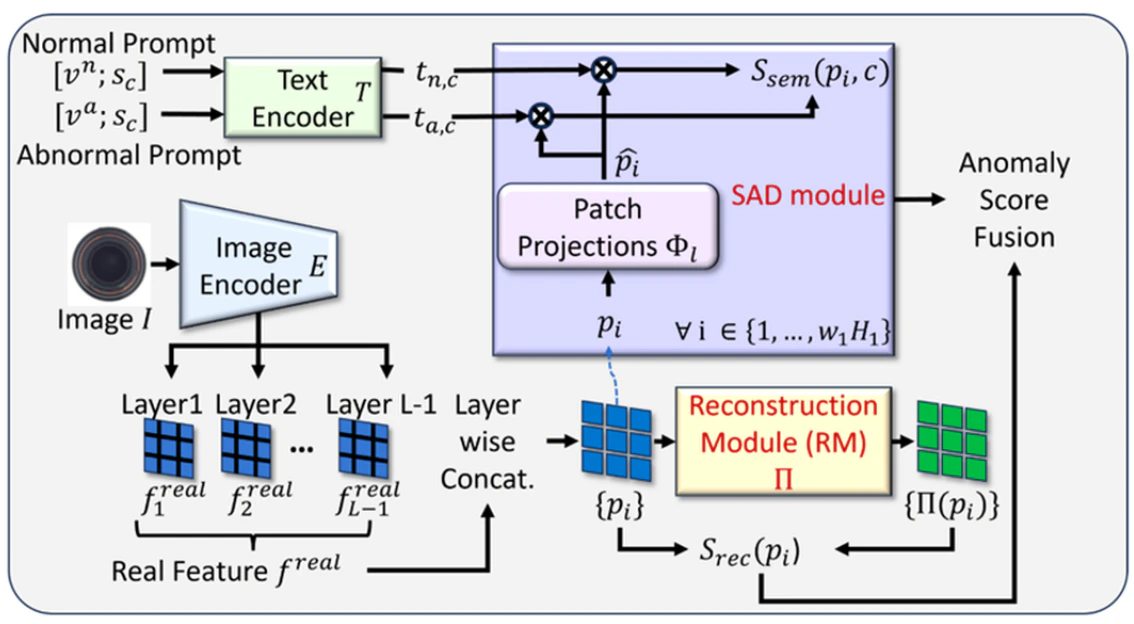
- 推論時は、再構成モジュール(Reconstruction Module)を用いて、入力画像をパッチ分解しパッチ単位で異常度を算出する
- 差分が大きければ異常度が高くなるように出力される
4. 結果

様々な工業製品の異常個所に対して従来手法よりも正確に異常個所を推定できている。
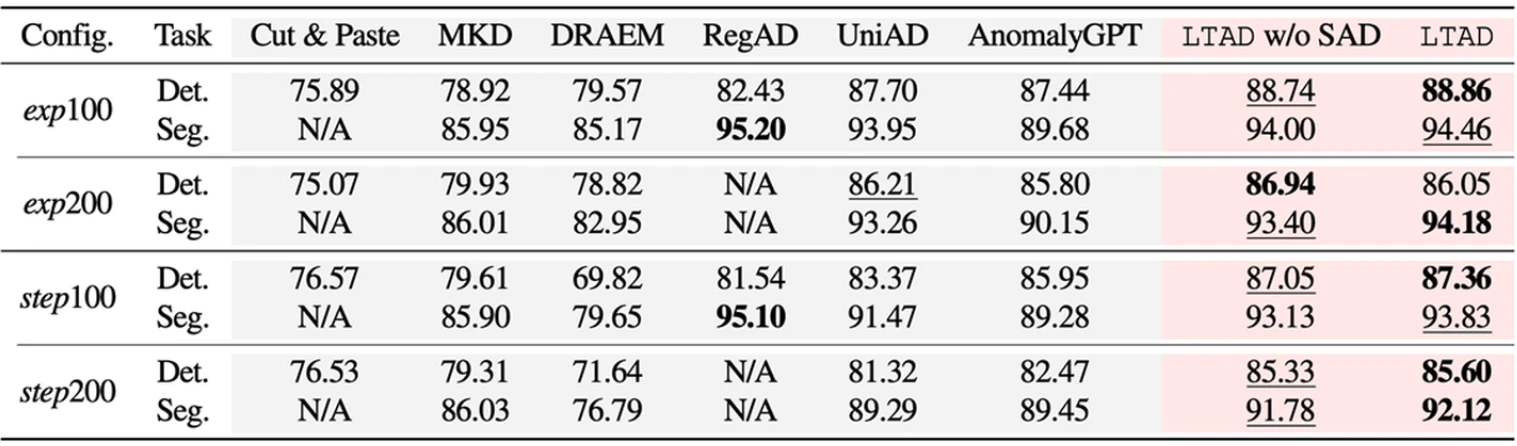

MVTec/VisA/DAGMデータセットでの比較結果では、既存の異常検知手法と比較してより高い精度で異常を検出することに成功している。データセットの偏りに頑健という特色がある。
last updates: June. 18 2024