1. 概要
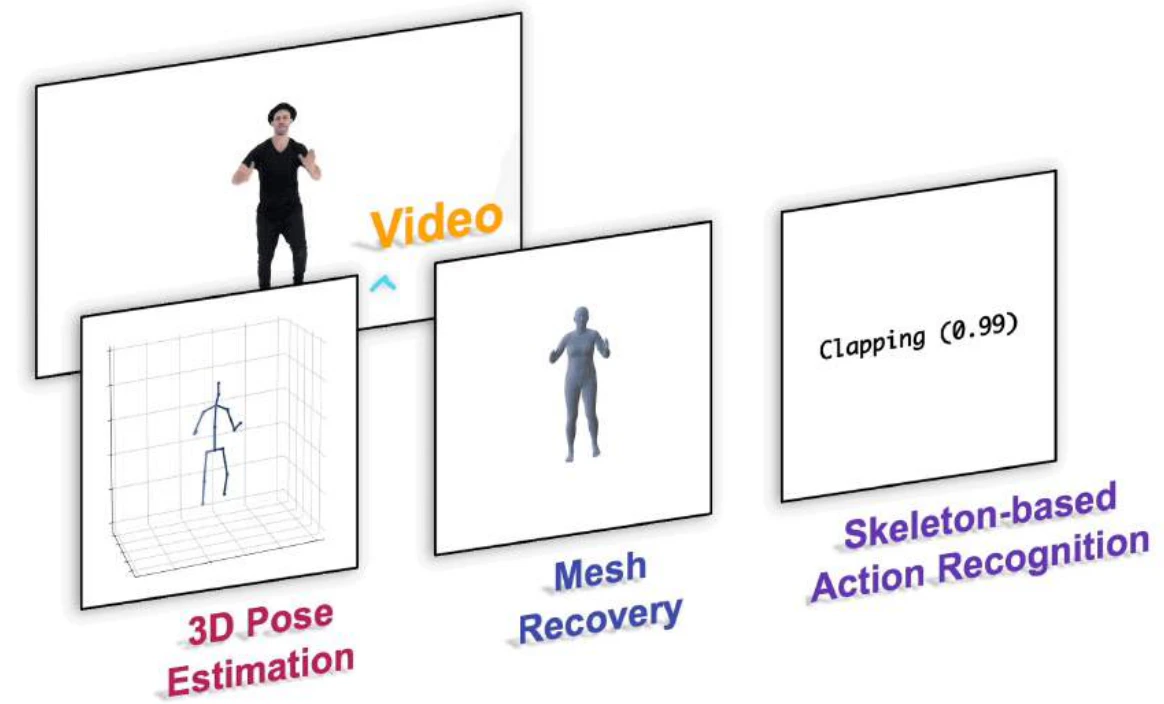
動画から3Dポーズ推定をしたり3Dメッシュ再構成をしたり、または行動認識を行ったりするモデルは多数提案されているが、従来はそれぞれ独立したタスクに対してモデルを作らなければならなかった。この研究では、一つのモデルで複数のタスクが解ける統一モデルを提案している。評価実験では、統一モデルで複数のタスクに対し従来の専用モデルよりも高精度なSOTAとなるスコアを達成している。
2. 新規性
タスクに依存したモデルではなく、複数タスクを一つのモデルで解きかつ従来の専用モデルよりも精度が高い点が新規性となっている。
3. 実現方法

事前学習として動画から2Dの人体のスケルトンを予測できるようにして置き、Motion Encorderでノイズを含む2Dのスケルトンから3Dの動作を復元できるように学習を行う。ここで獲得された動き情報の表現では、人間の動きに関する幾何学的・運動学的・物理学的な知識が暗黙的に学習され、これを複数のサブタスクに転移させることで、一つのモデルで複数のタスクを解くことに成功している。
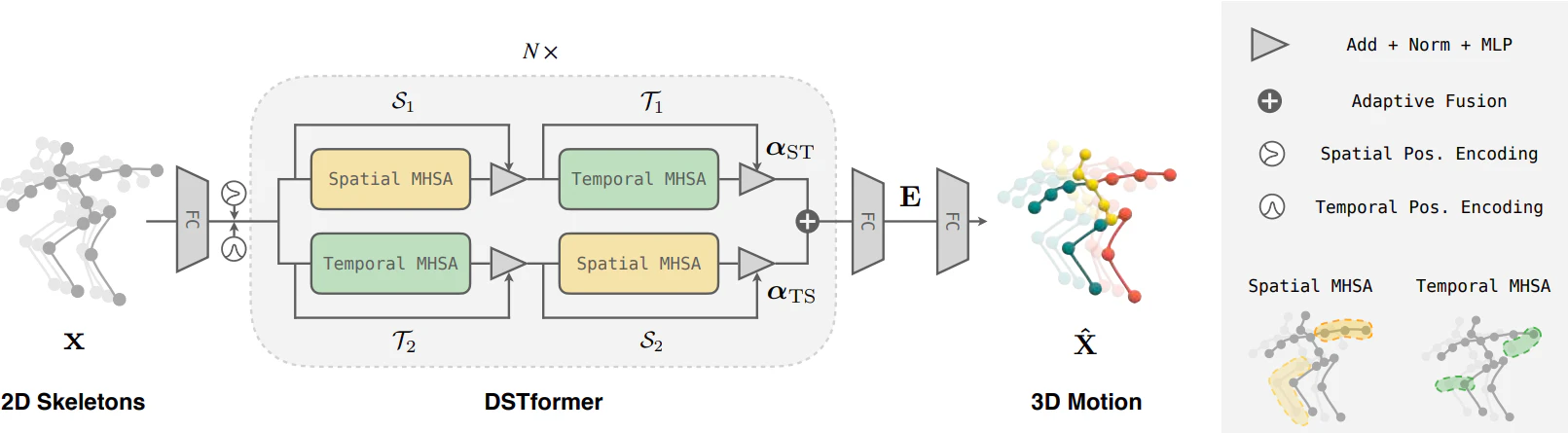
Motion EncorderはDual-stream Spatio-temporal Transformer(DSTformer)から構成されており、空間的に相関のある部位と時間的に相関のある部位を捉えることができ、骨格の関節間の時空間的な動作特徴を包括的にまた適応的にトラッキングすることができるようになっている。
4. 結果
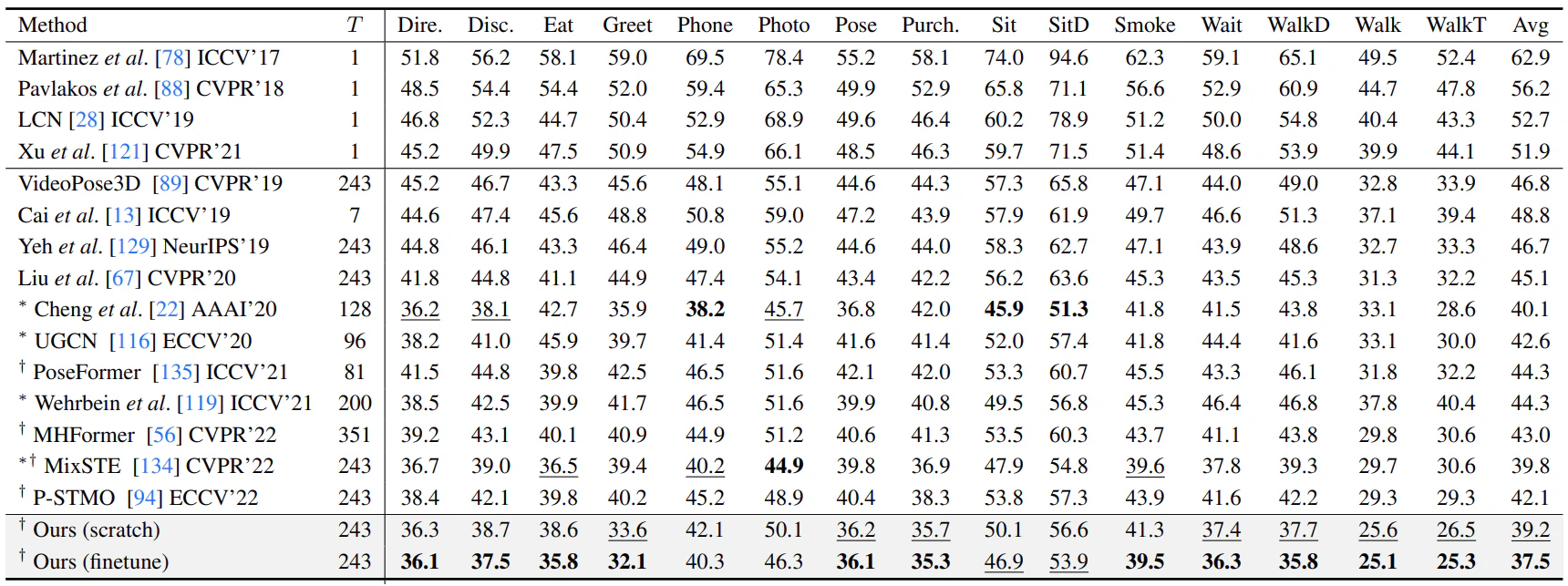
Human3.6Mデータセットで評価実験を行っており、従来手法を超える高精度な3Dポーズ予測を実現した。

スケルトンを入力とした行動認識や3Dメッシュの再構成の精度についても、従来手法を上回る精度を達成している。
last updates: Nov 24 2023