1. 概要
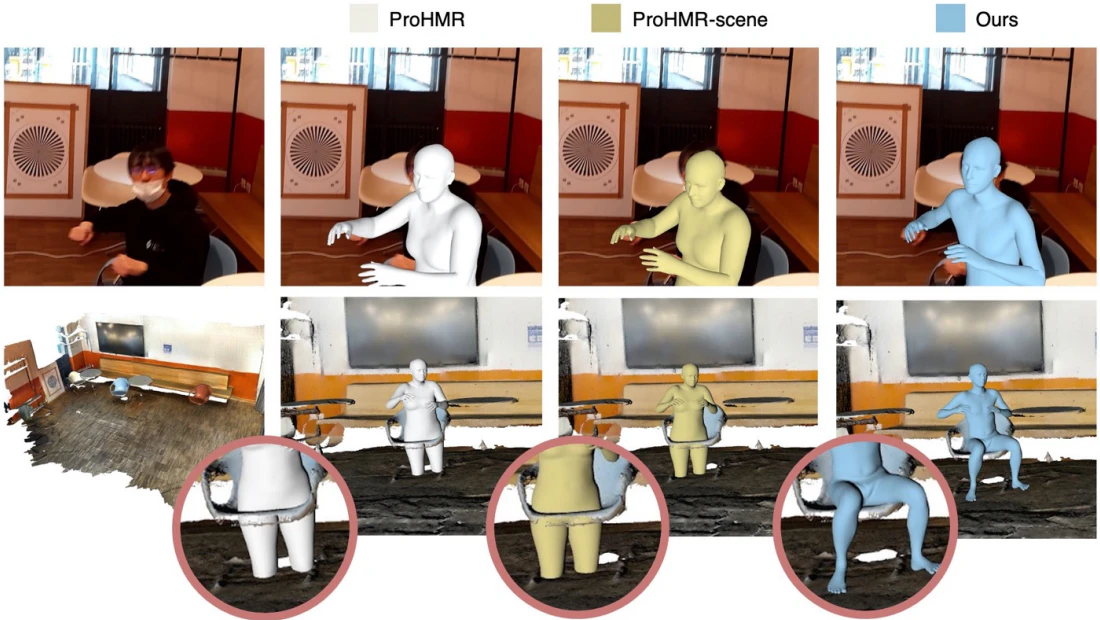
AR/VRのアプリケーションで、ユーザーの視点から見た映像について相手とのインタラクションをより没入感を持たせて表現するには、相手のユーザーの3Dポーズを現実世界の体のポーズと一致させることが必要だが、従来手法では演算量を削減するために見えている範囲でしか3Dモデルを構築しなかったりシーン全体との当たり判定を持たせていなかったため3Dモデルが埋没してしまったりしていた。この研究では拡散モデル(Diffusion Model)を使用して3D空間との当たり判定付きのヒューマンモデルを自動生成する技術を提案している。
2. 新規性
2Dの動画の各フレームについて、拡散モデルを用いて3Dのヒューマンモデルの自動生成を、構築するシーンとの当たり判定を考慮したフレームワークで提案している。
3. 実現方法
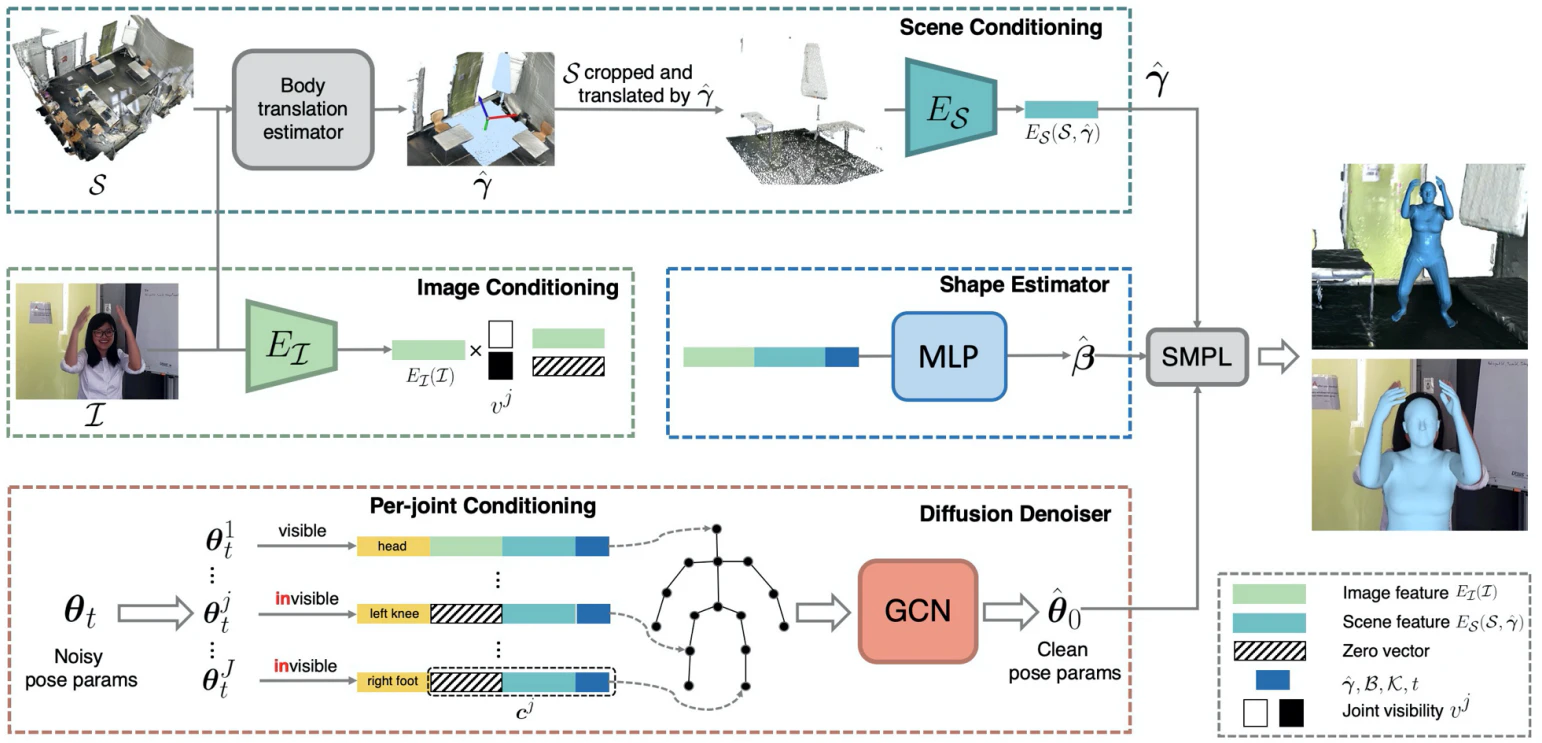
拡散モデルの制約条件として3Dシーンの幾何情報を含めることで、人体モデルとの当たり判定を自動で計算させる。分類器不使用型(classifier-free training )の拡散モデルの学習により、異なる条件で柔軟な人体パーツのサンプリングを可能としており、実世界の複雑なシーンにフィットした人体モデルの生成が行えるようにしている。シーンの制約を受けてサンプリングされた人体パーツは、GCN(Graph Convolution Network)によって関節毎に重みづけられて制約条件を反映されており、関節間の依存関係を考慮してボディパーツごとの生成を行うことでノイズ除去を行い、2D画像からでも正確に3Dモデルが生成できるようにしている。
4. 結果


一人称視点の画面からは見えていないオクルージョンのある部位についても、拡散モデルによって予測された人体パーツが生成されており、仮想世界との当たり判定を設けて生成することで自然な振る舞いを実現している。
last updates: Oct 10 2023