1. 概要

画像とテキストから動画を生成する技術のことを、テキスト条件付き画像動画生成(TI2V:Text-conditioned Image-to-Video generation)と呼び、例えばドラムをたたく男性の画像に対して"ドラムをたたく人"というテキストを入力すると、ドラムをたたいている動画が生成される。従来手法は、動画とテキストのペアのデータセットを用いたコストのかかる学習や、テキストと画像の条件付けをするための専用のモデル設計が必要となっていた。
この研究では、事前学習済みのテキストと動画の拡散モデル(T2V Diffusion model)を利用し、ゼロショットかつチューニングフリーな手法としてTI2V-Zeroを提案している。最適化やファインチューニングや外部モジュールなどの導入が全く必要ない。提案手法では、"repeat-and-slide"戦略と呼ばれる手法を導入しており、事前学習済みの凍結した拡散モデルを用いてノイズから画像を生成する際に、最初の入力画像からフレーム単位で生成し合成していくことでシームレスな動画を作る。
2. 新規性
- ゼロショットでTI2Vを生成:
ファインチューニングやモデルの変更を必要とせず、テキストと画像から直接動画の生成が可能になった - "repeat-and-slide"戦略:
事前学習済みの拡散モデルを固定し、入力画像のコンテキストを考慮した動画生成を可能にした
3. 実現方法
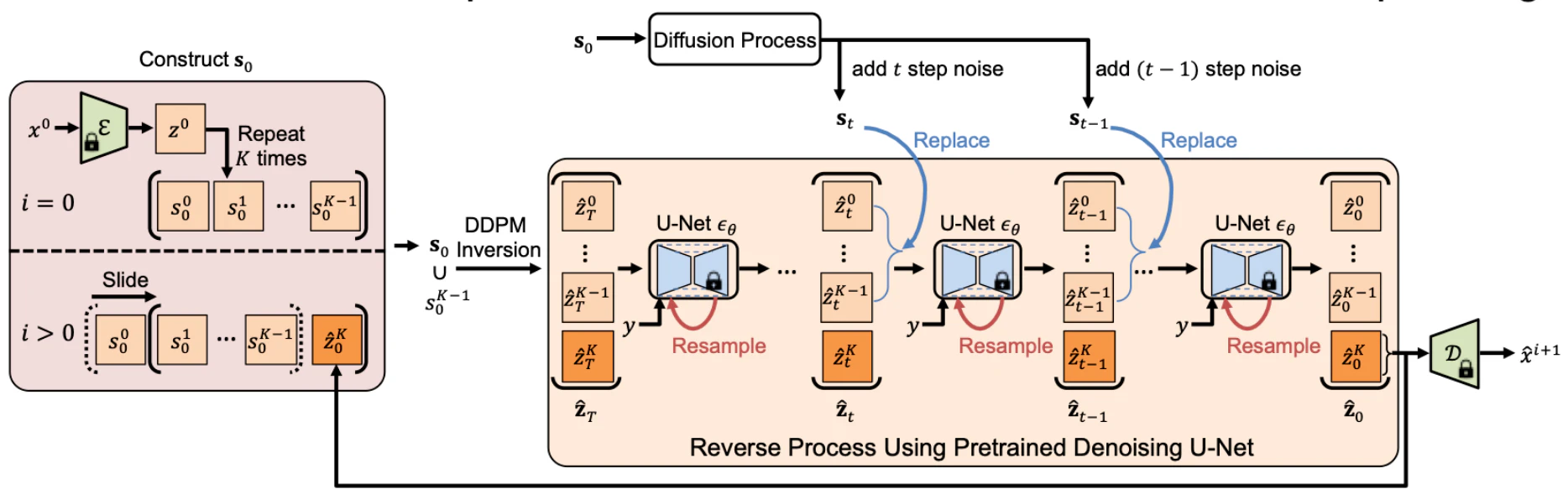
フレームエンコーダーE、フレームデコーダーD、ノイズ除去U-Net εθを含む、事前に学習され凍結された拡散モデルを使用する。動画生成時は以下のステップを実行する。
- 初期画像をエンコード:
まず、入力画像x0を潜在空間表現z0にエンコードする。 - キューの初期化:
z0をフレーム生成数分のk回繰り返して、フレームのキューs0 = [z0, z0, ..., z0] を初期化する。 - 初期ノイズの生成:
初期化したフレームs0に対して逆拡散過程(DDPM: Denoising Diffusion Probabilistic Model)を適用し、初期のガウシアンノイズzˆTを生成する。
逆拡散過程のノイズ除去ステップでは、U-Net εθを用いた逆ノイズ除去としてzˆt の最初の kフレームを、s0にノイズを徐々に加えた潜在コードstで置き換える。その後、各ステップ内でリサンプリングを行い、動きの滑らかさを向上させる。
画像生成の最終ステップ(t=0)では、z^0の最後のフレームをデコードし、新しいフレームx^i+1として出力する。生成した新しいフレームをキューに入れ、最初のフレームをデキューしてキューをスライドさせ、次のフレームを生成する。これを繰り返して動画にする。
*DDPMは拡散モデルと呼ばれる確率モデルの一種で、以下の2段階プロセスを通じて画像を生成する:
- 前身拡散過程(Forward Diffusion Process):元の画像に段階的にノイズを加えていき、最終的に純粋なノイズ画像に変換する
- 逆拡散過程(Reverse Diffusion Model):学習したノイズ除去モデルを用いて、ノイズ画像から段階的にノイズを除去し、元のデータ分布を復元することで新しい画像を生成する
4. 結果


従来のテキストと画像を入力とした動画生成手法(TI2V)と比較して、より高品質な動画を生成することができている。特に、ファインチューニングなしで様々なテキストと画像の組み合わせに対して高品質な動画を生成する汎用性を備えている。
動画の穴埋めや次のフレームの予測といった、他の動画生成タスクに対しても応用できることが分かった。
last updates: June. 18 2024