1. 概要
テキストから画像を生成するタスク(text-to-image)はここ最近で劇的に成功例が増えているが、画像を生成するモデルのアーキテクチャの進化によるところが大きい。以前は、敵対的ネットワーク(Generative Adversarial Networks:GANs)がデファクトとなっていたが、昨今は拡散モデル(diffusion model)と自己回帰モデル(autoregressive)を用いたDALL・E2などの大規模画像生成モデルが主流になっている。
この研究では、敵対的ネットワーク(GANs)がこうした大規模ネットワークに比べてパラメータが少ないことが原因で精度に差が出ているのではないかと考え、10億(1B)のパラメータを持つGigaGANを提案している。
2. 新規性
GANsのパラメータは高々200M程度に留まりスケーラビリティがないことが問題であったため、以下のような工夫を加えて学習可能なパラメータを圧倒的に増やすことに成功した。
- L2 self/cross-attention(著者はこの項が一番重要だと述べている)
- Adaptive kernel selection
- Multi-scaling training
- Matching-aware Loss
- Clip contrastive Loss(著者によれば次に重要な項は対照学習のロスとのこと)
- Vision-aided adversarial Loss
3. 実現方法
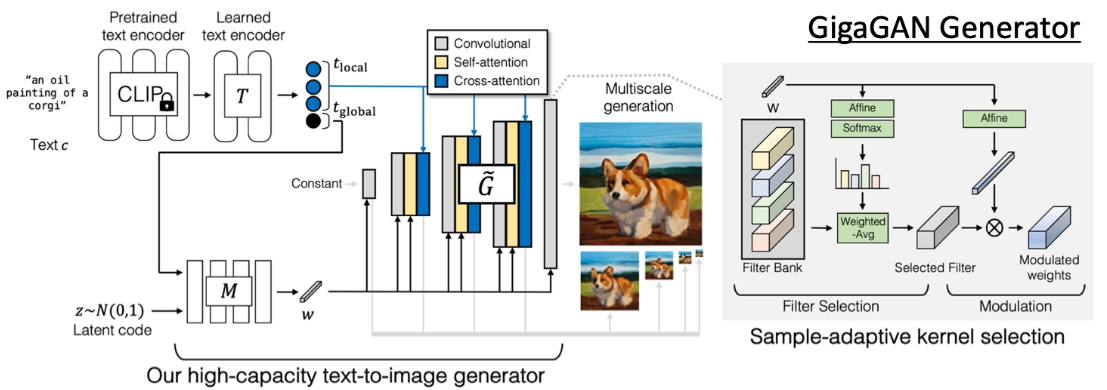
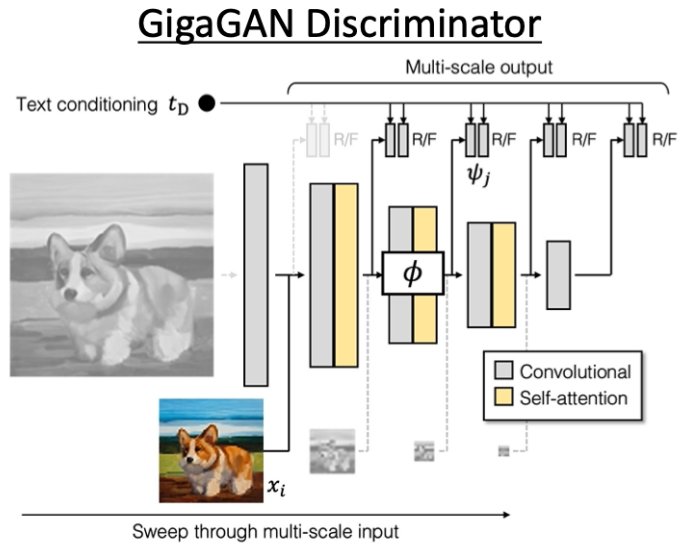
Generatorのアーキテクチャは荒い画像の多重ピラミッド(8x8-64x64)から学習して徐々に高解像度化していくcoarse-to-fineの戦略を取っており、事前学習にCLIPを採用することでテキストから画像が生成できるように調整を加えている。Discriminatorの学習時にも多重解像度で学習が進む。興味深いことに、一度低解像度で学習しておいたGeneratorのネットワークの入力に512x512の画像を入れるとマルチスケールで2Kの解像度の画像が高解像度で出力される。つまり、高解像度化において追加学習は含まれていない。
4. 結果
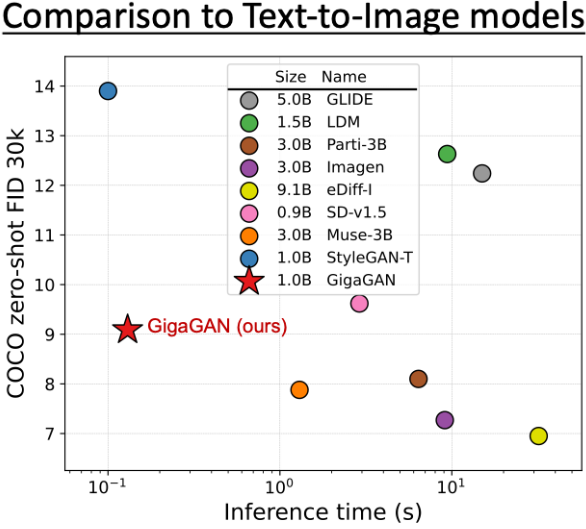
LAIONデータセット(20億枚:2B)の大規模ネットワークを使ってGANsの学習を実施したが、1エポック学習するのに2-3週間かかったため学習を打ち切り生成結果を見てみたところ、クオリティが非常に高く著者も驚きの結果となった。


last updates: June 21 2023