1. 概要

この研究では大規模言語モデル(LLM)を用いて、訓練データを全く使用せず未知の環境でも音声情報と視覚情報に基づいて、目的地への経路を探索するゼロショットナビゲーションシステムを提案している。
従来の音声情報と視覚情報を利用したナビゲーションシステムは、強化学習に大量の訓練データが必要であったが成功率が低く、汎用性に欠けるという問題があった。特に、音声信号は断続的な情報となるため、目的地の特定など目標に関する情報を推測することが困難だった。
提案手法ではこれらの課題に対処するため、マルチモーダルモデルを用いて感性データを扱えるようにしており、LLMベースで最適なルート探索を自ら提案・評価・棄却させる。さらに、部屋のレイアウト情報をマッピングすることで、環境を理解してより正確にナビゲーションできる手法を提案している。提案手法は、対象となる部屋や環境に関する学習を必要とせず補足情報などの意味情報を加えることなく、ゼロショットで従来手法を上回る手法を達成している。また、LLMベースのアーキテクチャを採用しているため、自身の行動の理由を自然言語で説明させることができる。
2. 新規性
- ゼロショットで音声情報と視覚情報を理解する:
従来の強化学習ベースの手法と異なり大量の訓練データを必要とせずに、未知の環境に対しても高い汎用性を持つナビゲーションを実現した。 - 反復的に提案・評価・棄却をLLMに実施させる:
LLMをエージェントとして用いて、生成した提案文書の正確性を自ら評価し、不正確な場合はそれを棄却させることで、より正確な環境理解と行動の決定を行えるようにしている。 - マルチモーダル生成AIに環境を理解させる:
部屋のレイアウト情報と説明文書を入力として与えることで、ナビゲーション能力を向上させている。
3. 実現方法
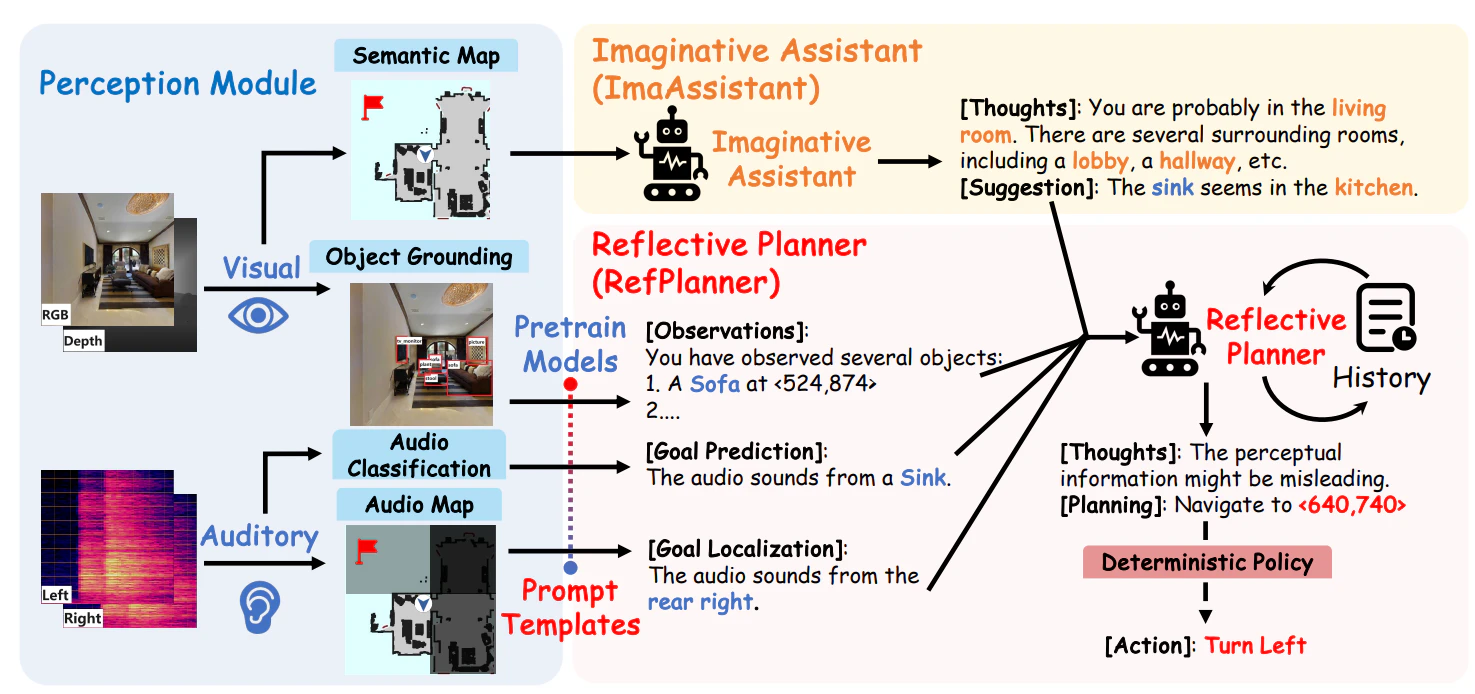
提案手法はカメラやマイクなどのセンサーから得られた視覚情報と音声情報をマルチモーダルモデルを用いて処理している。
生成AIをエージェントとして利用するにあたって、3つのコンポーネントを手案している。
- Perception Module:
センサー情報を入力をテキストベースの説明に変換 - Imaginative Assistant:
オフィス全体の視覚情報を分析し、全体的な視点から補助情報を言語情報に反映させる。 - Reflective Planner:
上記2つのコンポーネントを統合して、自分のルート提案を評価させ目標位置を決定し、ロボットへの行動を決定する。再評価を繰り返すことで、自身の提案の信頼性を自ら評価させ、より正確なルーティングを実現する。
4. 結果
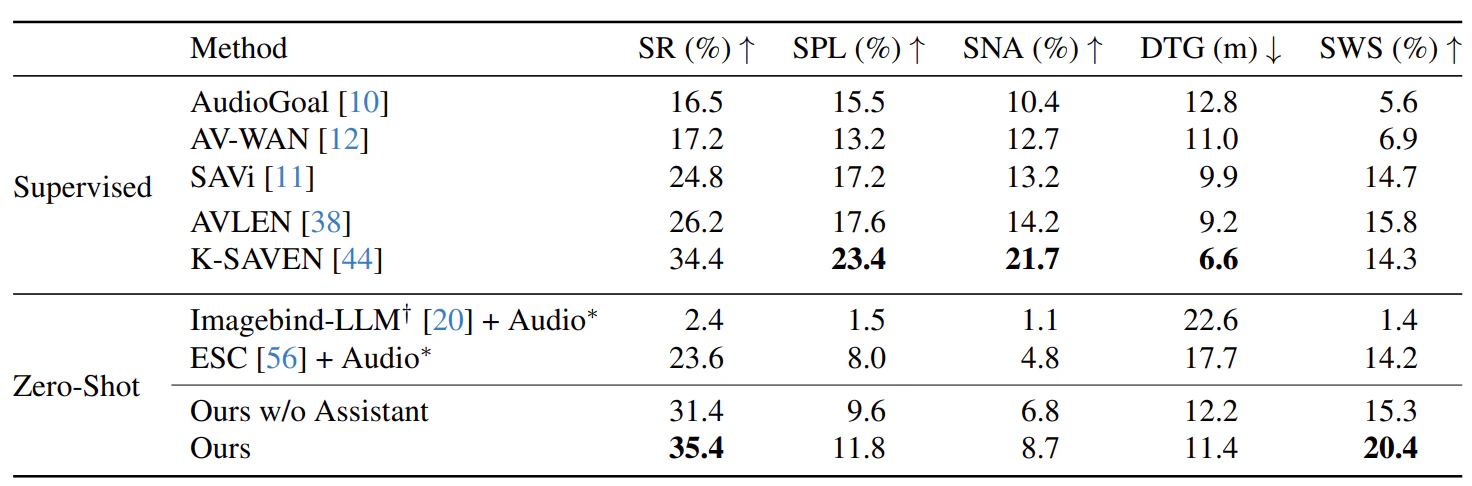
環境に関する事前知識や訓練データを必要とせず、ゼロショットでナビゲーションタスクを実行できている。
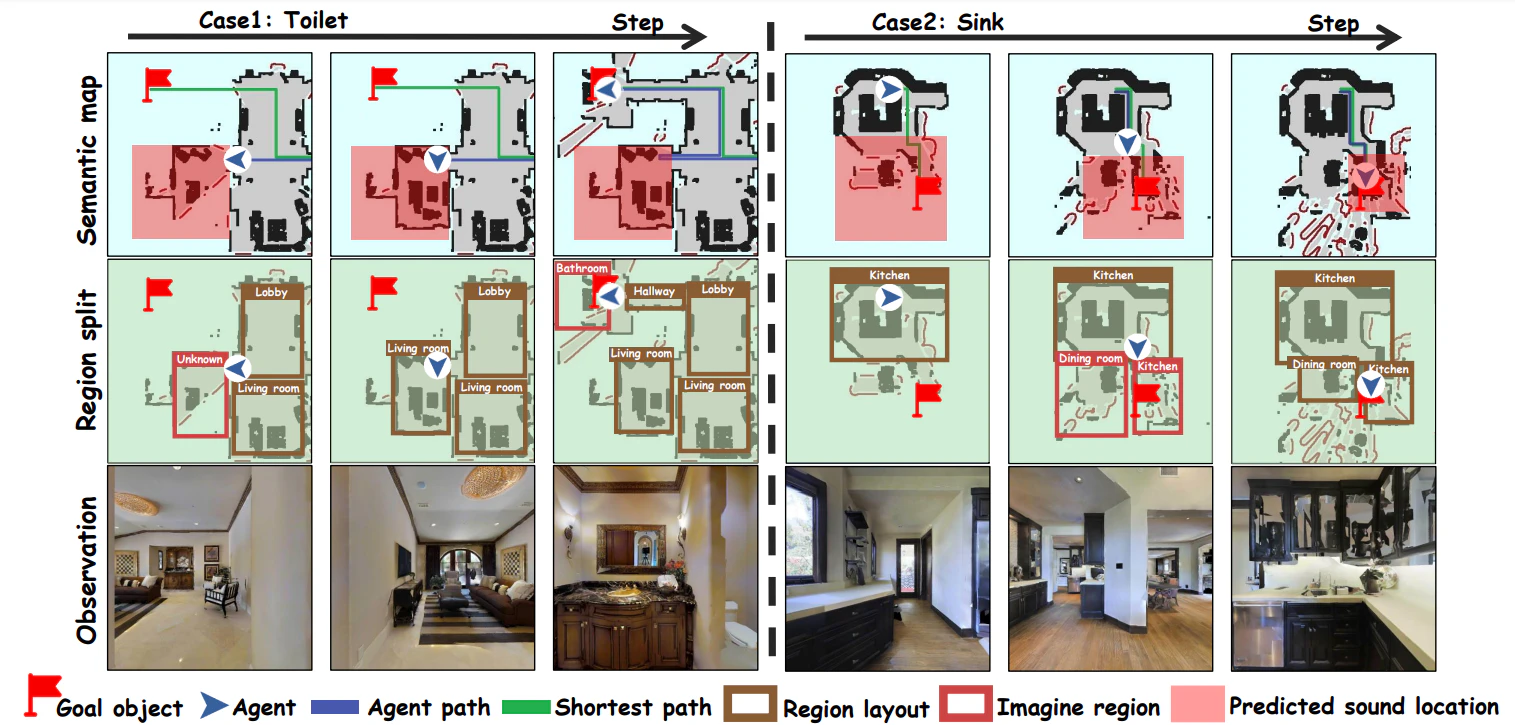
提案手法では、従来のの音声と視覚情報を用いた手法と比較して、未知の環境においても高い成功率と効率性で目標位置に到達できている。
また、LLMベースのアーキテクチャを採用しているため、提案手法では自身の行動の理由を自然言語で説明することができるようになった。
last updates: June. 18 2024