はじめに
先日までIT試験学習サイトping-tを利用してAWS認定試験の学習を行っておりました。
しかし、このping-tは分野別の得意不得意を確認する術はなかったような気がします。(たぶんないですよね?)
AWS認定試験のような総合的な知識を浅く問われる試験では、得意分野を伸ばすよりも不得意分野をどれだけ無くすかが重要だと思っています。
そこでスクレイピングにてping-tの模擬試験結果ページから試験結果の得意不得意の傾向を分析してみました。
本稿ではその過程を記事にしたいと思います。
スクレイピングとは
スクレイピングとは、WEBサイトの中を解析して自動で情報の収集や操作をする技術です。
ただしスクレイピングが禁止されているサービスもあるので利用規約を要チェックです。(ping-tは大丈夫なことを確認しました)
環境
- python
- selenmium
環境構築はこちらのサイトを参考にしてpython、seleniumライブラリ、WEBドライバを用意してください。
実装概要
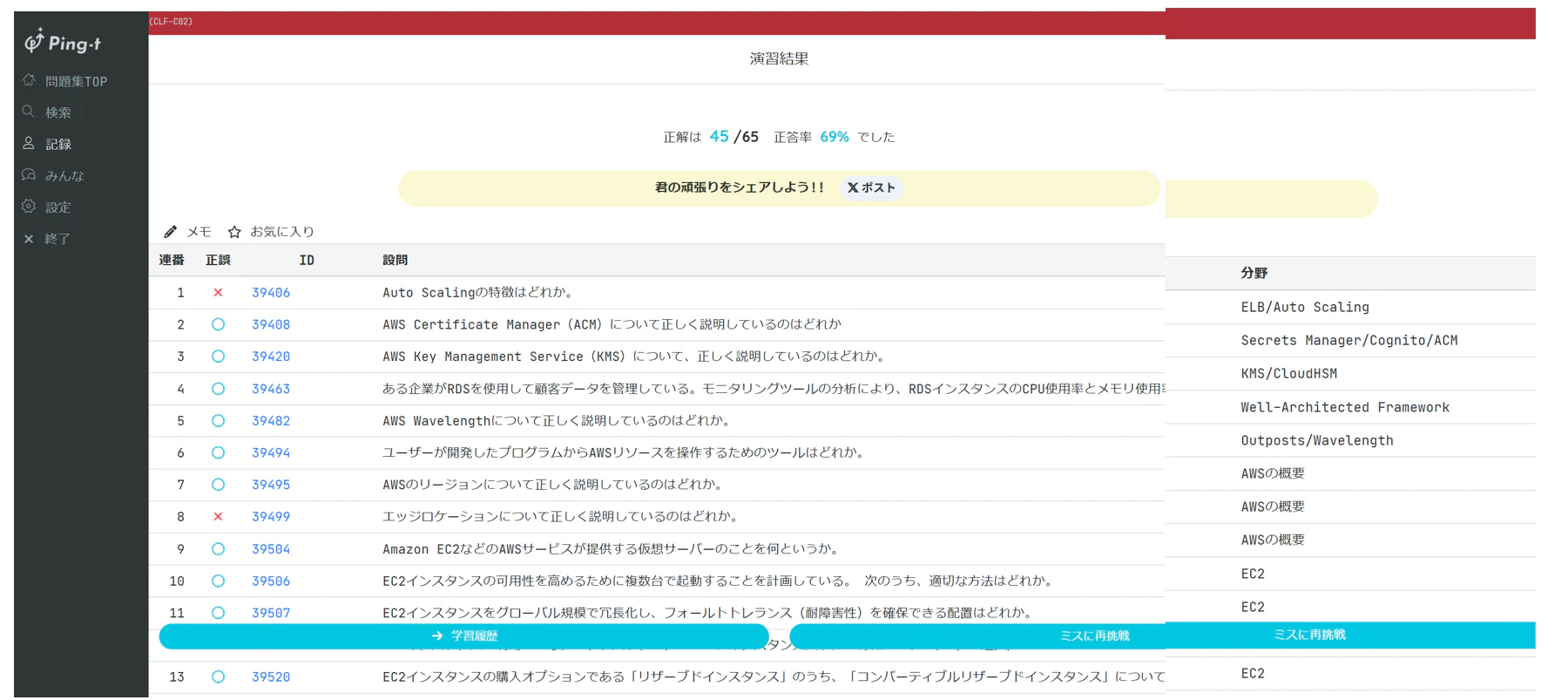
試験結果を分析したいページは以下のようなページになります。
しかしseleniumで直接試験結果ページを開くことはできず、ログイン画面に飛ばされてしまいます。
そのため少し面倒ですがログイン処理や各ボタンのぽちぽちから自動化していきます。
スクレイピングの実装
1. ブラウザを起動してping-tのログイン画面を表示
以下のコードでまずping-tのログイン画面を自動で開きます。(今回はchromeを使用します。
ping-tのリンク:https://mondai.ping-t.com/users/sign_in
driver = webdriver.Chrome() #WEBブラウザの起動
driver.get('https://mondai.ping-t.com/users/sign_in')
実行するとこのような画面が表示され、上部には「自動ソフトウェアによって制限されています」と表示されています。

2. ログイン
次からseleniumの本領発揮です。
ログインをするためにはユーザIDとパスワードを入力しなければいけませんね。
seleniumでユーザIDとパスワードのテキストボックスにアクセスするため、要素を確認します。
ブラウザで以下のような開発者ツールを開きます。(右クリックして検証ボタンまたはF12)

すると、ユーザIDを入力するテキストボックスはid="user_login_key"、
パスワードを入力するテキストボックスはid="user_user_password"、
またログインボタンはclass="btn btn btn-primary"
がそれぞれ指定されていることが分かります。
この情報をもとに以下のコードで自動ログインできます。
find_element()でidやclassを指定して要素を取得し、send_keys()でキーを送信することができます。
# ログイン用ユーザ名の入力
uid_element = driver.find_element(By.ID, "user_login_key")
uid_element.send_keys(USER_NAME)
# ログイン用パスワードの入力
upass_element = driver.find_element(By.ID, "user_password")
upass_element.send_keys(USER_PASS)
# ログインボタンのクリック
button_element = driver.find_element(By.CSS_SELECTOR, ".btn.btn-primary")
button_element.send_keys(Keys.ENTER)
3. 試験結果ぺージのスクレイピング
ログイン後以下のコードで試験結果ページに自動遷移します。
# 試験結果ページのurl
EXAM_RESULT_PAGE = "https://mondai.ping-t.com/question_subjects/76/question_sessions/34246186/result"
# 模擬演習結果ページに遷移
driver.get(EXAM_RESULT_PAGE)
以下は試験結果ページになります。
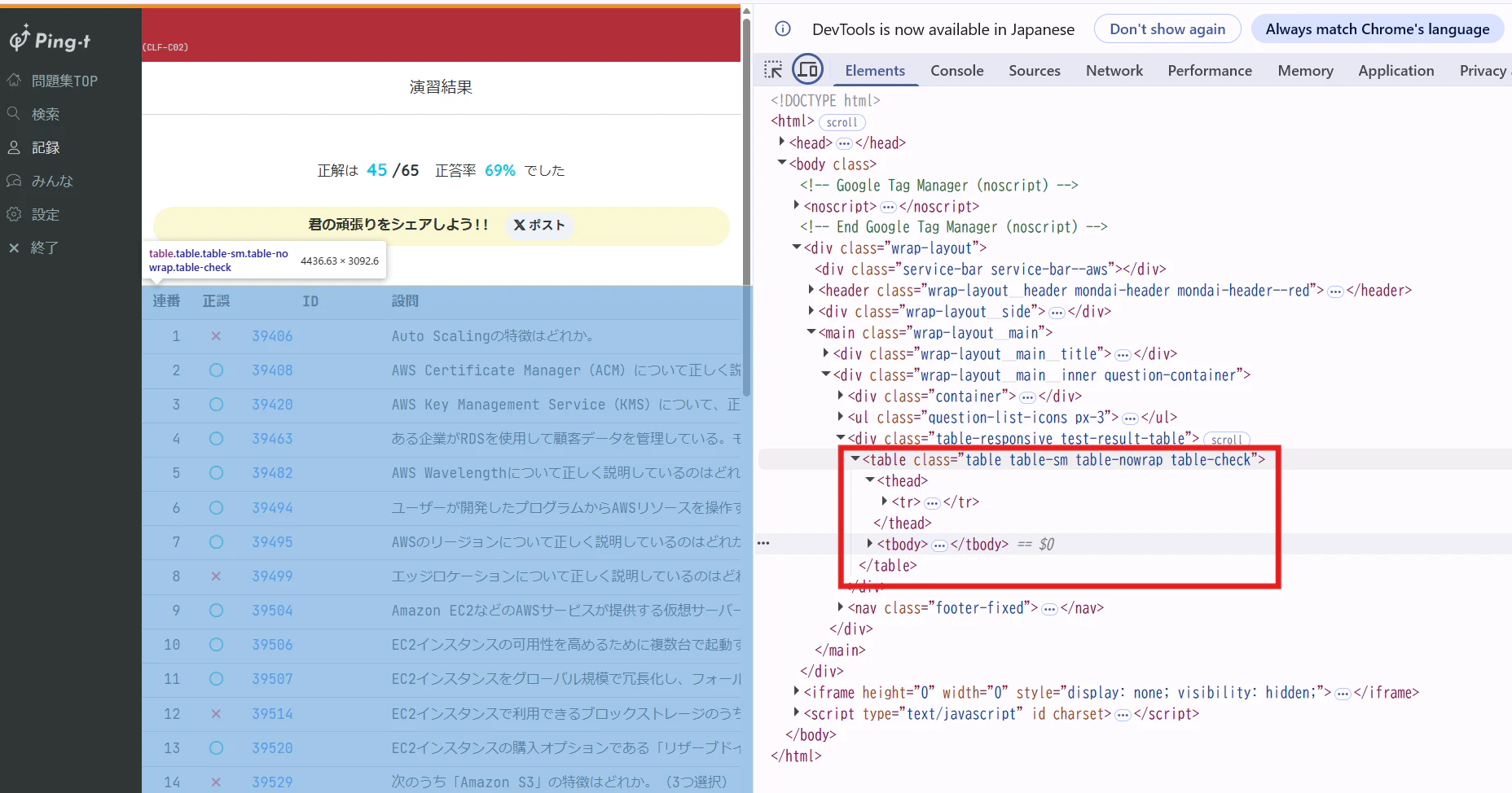
ここで再び開発者ツールを確認すると、試験結果は<table>タグで記述されていることが分かります。
そしてこの<table>タグはclass="table table-sm table-nowrap table-check"が指定されています。
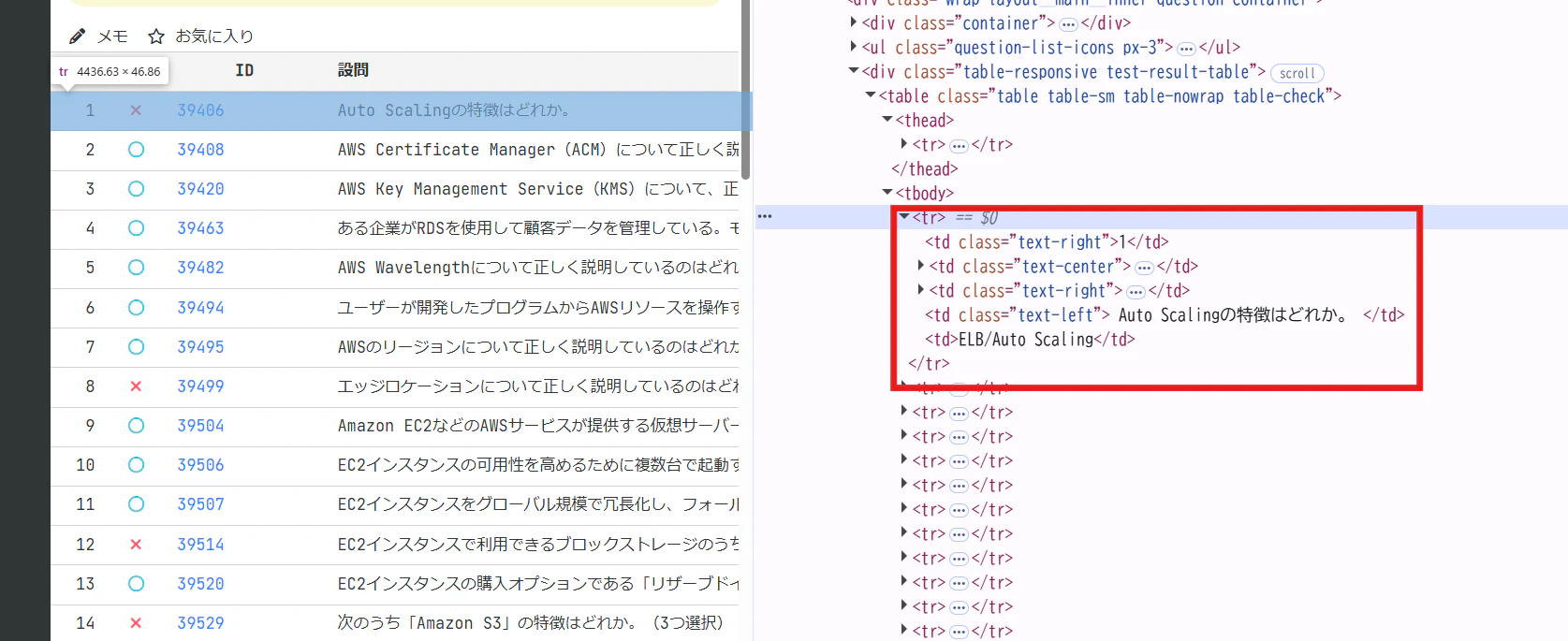
さらにもう少しよく見ると問題の一行は<tr>タグで記述されています。
これらの情報から以下のコードで問題の各行をリストとして取得することができます。
# tableから行をリストで取得
table = driver.find_element(By.CSS_SELECTOR, ".table.table-sm.table-nowrap.table-check")
rows = table.find_elements(By.TAG_NAME, "tr")
次にいよいよ得意不得意を分析するために、各行から正誤(○ or ×)と分野名を取得したいと思います。

○は<i>タグでclass="fas fa-times fa-fw"
×は<i>タグでclass="far fa-circle fa-fw"
そして分野名は<td>タグでclass指定なしとなっています。

この情報をもとに、以下のコードで分野ごとに正解数と不正解数をカウントします。
- レコードのリストからレコードを1つずつ取得(レコード=問題を指す)
- 問題の分野名を取得
- 正誤判定をする
・正解なら正解ステータスを+1
・不正解なら不正解ステータスを+1
# tableから1レコードずつ走査
for row in rows:
# 分野名を取得
field_name = ""
field_cells = row.find_elements(By.TAG_NAME, "td")
for td in field_cells:
# class属性が空の<td>から分野名を取得(分野にはclassが指定されていない)
if td.get_attribute("class") == "":
field_name = td.text.strip()
break
# 分野名が取得できた場合のみ処理
if field_name:
# 分野別の統計を初期化
if field_name not in field_stats:
field_stats[field_name] = {"correct": 0, "incorrect": 0, "total": 0}
# 正誤チェック
text_center_cells = row.find_elements(By.CSS_SELECTOR, "td.text-center")
for judge_cell in text_center_cells:
# 正解のアイコンを探す
try:
true_icon = judge_cell.find_element(By.CSS_SELECTOR, ".far.fa-circle.fa-fw")
field_stats[field_name]["correct"] += 1
field_stats[field_name]["total"] += 1
except NoSuchElementException:
pass
# 不正解のアイコンを探す
try:
false_icon = judge_cell.find_element(By.CSS_SELECTOR, ".fas.fa-times.fa-fw")
field_stats[field_name]["incorrect"] += 1
field_stats[field_name]["total"] += 1
except NoSuchElementException:
pass
4. 結果の表示
以下のコードで分野別の正解・不正解を表示します。
# 結果を表示
print("=== 分野別正解率・不正解率 ===")
for field_name, stats in field_stats.items():
if stats["total"] > 0:
correct_rate = (stats["correct"] / stats["total"]) * 100
incorrect_rate = (stats["incorrect"] / stats["total"]) * 100
print(f"分野: {field_name}")
print(f" 正解数: {stats['correct']}, 不正解数: {stats['incorrect']}, 総問題数: {stats['total']}")
print(f" 正解率: {correct_rate:.1f}%, 不正解率: {incorrect_rate:.1f}%")
print()
5. 出力結果
以下のように分野の正答情報を出力することができました。
例えばVPCの問題は6問出題されて5問正解、1問不正解であることが分かります。
出力結果の詳細を表示
=== 分野別正解率・不正解率 ===
分野: VPC
正解数: 5, 不正解数: 1, 総問題数: 6
正解率: 83.3%, 不正解率: 16.7%
※長いので続きはトグルを開いてください
分野: VPC
正解数: 5, 不正解数: 1, 総問題数: 6
正解率: 83.3%, 不正解率: 16.7%
分野: Trusted Advisor/Compute Optimizer
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: Systems Manager/Managed Service/Health Dashboard
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: SNS/SQS
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: Cloud9/CodeCommit/CodeBuild/CodeDeploy/CodePipeline
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: オンプレミスとクラウド
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: AWSの概要
正解数: 3, 不正解数: 0, 総問題数: 3
正解率: 100.0%, 不正解率: 0.0%
分野: EC2
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: S3
正解数: 3, 不正解数: 0, 総問題数: 3
正解率: 100.0%, 不正解率: 0.0%
分野: IAM
正解数: 4, 不正解数: 1, 総問題数: 5
正解率: 80.0%, 不正解率: 20.0%
分野: ELB/Auto Scaling
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: Macie/GuardDuty/Inspector/Security Hub
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: ECS/Fargate
正解数: 0, 不正解数: 1, 総問題数: 1
正解率: 0.0%, 不正解率: 100.0%
分野: EFS
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: FSx
正解数: 0, 不正解数: 1, 総問題数: 1
正解率: 0.0%, 不正解率: 100.0%
分野: Storage Gateway
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: 複合問題
正解数: 8, 不正解数: 2, 総問題数: 10
正解率: 80.0%, 不正解率: 20.0%
分野: Polly/Rekognition/Lex/Kendra/Textract/Comprehend
正解数: 2, 不正解数: 0, 総問題数: 2
正解率: 100.0%, 不正解率: 0.0%
分野: Config/Control Tower
正解数: 0, 不正解数: 2, 総問題数: 2
正解率: 0.0%, 不正解率: 100.0%
分野: Direct Connect/VPN
正解数: 0, 不正解数: 1, 総問題数: 1
正解率: 0.0%, 不正解率: 100.0%
分野: WorkSpaces/AppStream
正解数: 0, 不正解数: 1, 総問題数: 1
正解率: 0.0%, 不正解率: 100.0%
分野: RDS/Aurora
正解数: 1, 不正解数: 2, 総問題数: 3
正解率: 33.3%, 不正解率: 66.7%
分野: AWSの利点
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: Well-Architected Framework
正解数: 3, 不正解数: 0, 総問題数: 3
正解率: 100.0%, 不正解率: 0.0%
分野: 責任共有モデル
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: クラウド導入フレームワーク
正解数: 1, 不正解数: 1, 総問題数: 2
正解率: 50.0%, 不正解率: 50.0%
分野: Migration Hub/ADS/MGN/DMS
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: Secrets Manager/Cognito/ACM
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
分野: サポートプラン
正解数: 0, 不正解数: 2, 総問題数: 2
正解率: 0.0%, 不正解率: 100.0%
分野: CloudFormation
正解数: 1, 不正解数: 0, 総問題数: 1
正解率: 100.0%, 不正解率: 0.0%
6. 問題点
分野名が細かく分類されているため、1問しか出題されない分野も少なくなく、正解・不正解にかかわらず傾向をつかむのが難しいです。
そのため、この分類をもう少し粗く中分類的に統計をとるのが良いかなと思いました。
(例えばVPC、Route53、DirectConnectなどはまとめてネットワークという分類にするなど
(今回はここまでにします
全体コード
+αとして、統計結果をCSVファイルに出力もしています。
import time
import csv
from datetime import datetime
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.common.exceptions import NoSuchElementException
EXAM_RESULT_PAGE = "https://mondai.ping-t.com/question_subjects/76/question_sessions/34246186/result"
USER_NAME = "ユーザ名"
USER_PASS = "パスワード"
driver = webdriver.Chrome() #WEBブラウザの起動
driver.get('https://mondai.ping-t.com/users/sign_in')
# ログイン用ユーザ名の入力
uid_element = driver.find_element(By.ID, "user_login_key")
uid_element.send_keys(USER_NAME)
# ログイン用パスワードの入力
upass_element = driver.find_element(By.ID, "user_password")
upass_element.send_keys(USER_PASS)
# ログインボタンのクリック
button_element = driver.find_element(By.CSS_SELECTOR, ".btn.btn-primary")
button_element.send_keys(Keys.ENTER)
time.sleep(2)
# https://mondai.ping-t.com/session_gateへ遷移,「このまま続ける」をクリック
button_element = driver.find_element(By.CSS_SELECTOR, ".btn.btn-primary")
button_element.send_keys(Keys.ENTER)
time.sleep(2)
# 模擬演習結果ページに遷移
driver.get(EXAM_RESULT_PAGE)
time.sleep(3)
# tableから一行ずつ取得
table = driver.find_element(By.CSS_SELECTOR, ".table.table-sm.table-nowrap.table-check")
rows = table.find_elements(By.TAG_NAME, "tr")
# 分野ごとの統計を格納する辞書
field_stats = {}
# tableから1レコードずつ走査
for row in rows:
# 分野名を取得
field_name = ""
field_cells = row.find_elements(By.TAG_NAME, "td")
for td in field_cells:
# class属性が空の<td>から分野名を取得(分野にはclassが指定されていない)
if td.get_attribute("class") == "":
field_name = td.text.strip()
break
# 分野名が取得できた場合のみ処理
if field_name:
# 分野別の統計を初期化
if field_name not in field_stats:
field_stats[field_name] = {"correct": 0, "incorrect": 0, "total": 0}
# 正誤チェック
text_center_cells = row.find_elements(By.CSS_SELECTOR, "td.text-center")
for judge_cell in text_center_cells:
# 正解のアイコンを探す
try:
true_icon = judge_cell.find_element(By.CSS_SELECTOR, ".far.fa-circle.fa-fw")
field_stats[field_name]["correct"] += 1
field_stats[field_name]["total"] += 1
except NoSuchElementException:
pass
# 不正解のアイコンを探す
try:
false_icon = judge_cell.find_element(By.CSS_SELECTOR, ".fas.fa-times.fa-fw")
field_stats[field_name]["incorrect"] += 1
field_stats[field_name]["total"] += 1
except NoSuchElementException:
pass
# 結果を表示
print("=== 分野別正解率・不正解率 ===")
for field_name, stats in field_stats.items():
if stats["total"] > 0:
correct_rate = (stats["correct"] / stats["total"]) * 100
incorrect_rate = (stats["incorrect"] / stats["total"]) * 100
print(f"分野: {field_name}")
print(f" 正解数: {stats['correct']}, 不正解数: {stats['incorrect']}, 総問題数: {stats['total']}")
print(f" 正解率: {correct_rate:.1f}%, 不正解率: {incorrect_rate:.1f}%")
print()
# 全体の統計
total_correct = sum(stats["correct"] for stats in field_stats.values())
total_incorrect = sum(stats["incorrect"] for stats in field_stats.values())
total_problems = total_correct + total_incorrect
if total_problems > 0:
overall_correct_rate = (total_correct / total_problems) * 100
overall_incorrect_rate = (total_incorrect / total_problems) * 100
print("=== 全体統計 ===")
print(f"総正解数: {total_correct}, 総不正解数: {total_incorrect}, 総問題数: {total_problems}")
print(f"全体正解率: {overall_correct_rate:.1f}%, 全体不正解率: {overall_incorrect_rate:.1f}%")
# CSVファイルに出力
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
csv_filename = f"./scraping_pingt/pingt_results_{timestamp}.csv"
with open(csv_filename, 'w', newline='', encoding='shift-jis') as csvfile:
writer = csv.writer(csvfile)
# ヘッダー行
writer.writerow(['分野', '正解数', '不正解数', '総問題数', '正解率(%)', '不正解率(%)'])
# 分野別データ
for field_name, stats in field_stats.items():
if stats["total"] > 0:
correct_rate = (stats["correct"] / stats["total"]) * 100
incorrect_rate = (stats["incorrect"] / stats["total"]) * 100
writer.writerow([
field_name,
stats['correct'],
stats['incorrect'],
stats['total'],
f"{correct_rate:.1f}",
f"{incorrect_rate:.1f}"
])
# 空行
writer.writerow([])
# 全体統計
if total_problems > 0:
writer.writerow(['全体', total_correct, total_incorrect, total_problems, f"{overall_correct_rate:.1f}", f"{overall_incorrect_rate:.1f}"])
print(f"\nCSVファイルに保存しました: {csv_filename}")
# ブラウザを閉じる
driver.quit()
おわりに
今回はseleniumで簡易的にAWS認定試験の得意不得意の分析をやってみました。