要約
- 目的:異なる時系列データの類似度を測る
- キーワード:動的時間伸縮法 / Dynamic Time Warping (以下、DTW),Derivative Dynamic Time Warping (以下、DDTW)
- 参照1.:Derivative DTW ~時系列パターンの類似度計算の手法~ by Tech Blog
- 参照2.:DTW(Dynamic Time Warping)動的時間伸縮法 by S-Analysis
- 参照3.:DTW (動的時間伸縮法)の実装 by ksknw
- 参照4.:fastdtwの使い方
DTW
DTWの求め方
-
2つの時系列の各点の距離(データの次元にもよるが、今回は絶対値)を計算した(コスト)行列を作成
\begin{align} time\ series\ T&:t_0,t_1,...,t_N,\\ time\ series\ S&:s_0,s_1,...,s_M,\\ \boldsymbol{W}&:=(\delta(i,j)) ,\\ where\ \delta(t_i,s_j)&:=|t_i-s_j|,i \in \{0,1,...,N\},j\in\{0,1,...,M\} \end{align} -
この行列上を(0,0)から(N,M)を通るパスで単調性増加性を満たすものを考える。
\begin{align} path\ \tau :\tau(0)=(0,0),\tau(1),...,\tau(p)=(p_i,p_j),...,\tau(K),\\ where\ p_i \in \{0,1,...,N\},p_j\in\{0,1,...,M\}. \end{align}特に、この$path\ \tau$で単調性増加性を満たすようなものを考える。
\tau(p) \leq \tau(q) \Longleftrightarrow^{def} p_i\leq q_i\ or\ p_j\leq q_j.\\ if\ p\leq q,then\ \tau(p) \leq \tau(q). -
この$path$が通る行列$\boldsymbol{W}$の要素の和で最少となる値をDTWのコストとする。
\begin{align} cost(\tau)&:=\sum_{p}\delta(p_i,p_j)\\ Dist(T,S)&:=min_{\tau}cost(\tau) \end{align}
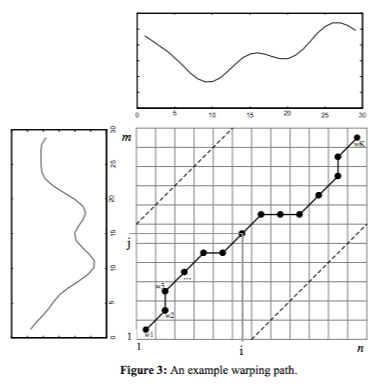
公式の式とは違うが、こんな感じでしょう。
テストコード:参照3
# 準備
pip install fastdtw # <= pipは実際こいつだけでよい
pip install numpy
pip install scipy
## code##
import numpy as np
from scipy.spatial.distance import euclidean
from fastdtw import fastdtw
A = np.sin(np.array(range(T)) / 10)
B = np.sin((np.array(range(T)) / 10 + t * np.pi))
C = np.zeros((T))
distance, path = fastdtw(A, B, dist=euclidean)
print(distance)
plt.plot(A)
plt.plot(B)
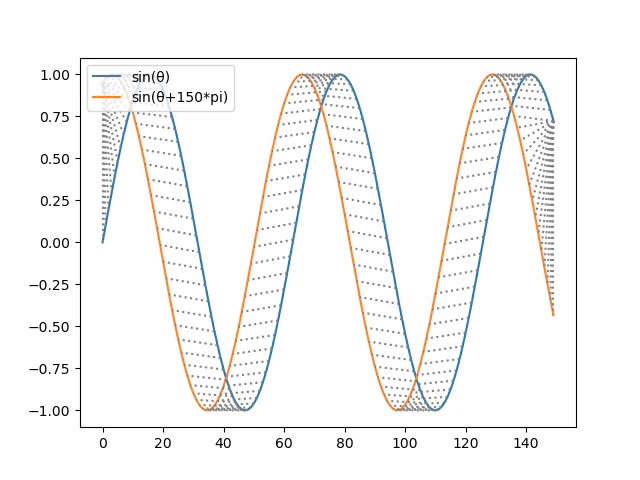
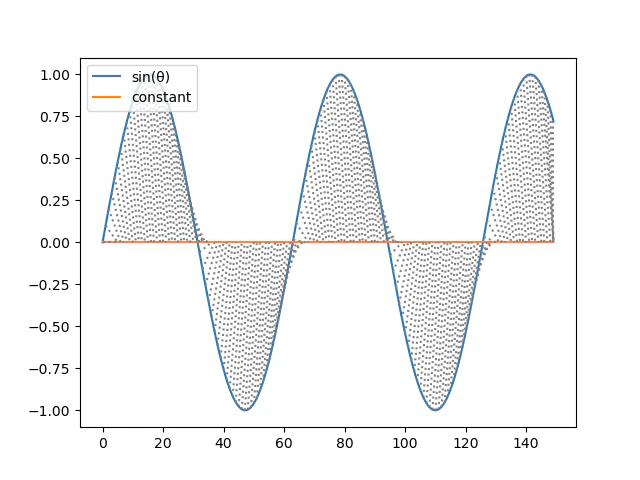
for i, j in path:
plt.plot([i, j], [A[i], B[j]],color='gray', linestyle='dotted')
plt.legend(["sin(θ)", "sin(θ+150*pi)"], fontsize=10, loc=2)
plt.show()
## 結果##
sin(θ)-sin(θ+150*pi): 0.6639470476737607
sin(θ)-constant: 0.5150026855435942
DTW(sin(θ), sin(θ+150*pi)): 16.720461687388624
DTW(sin(θ), constant): 97.26964355198544
DTWのメリット
時系列同士の長さや周期が違っても類似度が求まる
DTWのデメリット
時間軸に関して局所的に加速、減速した部分がある時系列データに対して、直観とは違うアライメントが行われてしまう:
参照:Derivative Dynamic Time Warping by Eamonn等
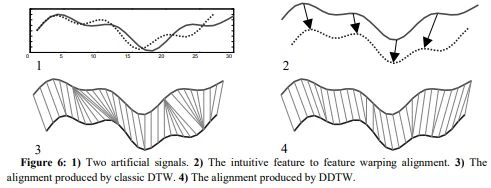
例えば、一方がs高になった場合、DTWはデータ形状を無視してアライメントするため、s高のデータ点はs高前のデータ点とペアの物と対応付けてしまうのが原因
DDTW
DTWを受けて、形状を捉えた情報加味して類似度を測る。
実際には時系列データ$time\ series\ T:t_0,t_1,...,t_N$を以下のように加工した後、DTWする:
T^*:t^*_0,t^*_1,...,t^*_N,\\
where\ t^*_i := \frac{t_i-t_{i-1}+\frac{t_{i+1}-t_{i-1}}{2}}{2}= \frac{t_i-t_{i-1}+\frac{(t_{i+1}-t_i)+(t_i-t_{i-1})}{2}}{2}
この加工は、注目する点$t_i$に関して、左微分$t_i-t_{i-1}$と右微分$t_{i+1}-t_i$の平均と左微分の平均を出したものである。
この加工をDTWするのがDDTWである。
DDTWのメリット
上昇トレンドや下降トレンドなどの形状を考慮した類似度が算出できる
DDTWのデメリット
傾きの平均でよいのだろうか?
code
from concurrent.futures import ProcessPoolExecutor
from concurrent.futures import ThreadPoolExecutor
import time
import numpy as np
import pylab as plt
import seaborn as sns
from fastdtw import fastdtw
from scipy.spatial.distance import euclidean
def get_test_curves(view=False):
T = 150
t = .4
A = np.sin(np.array(range(T)) / 10)
B = np.sin((np.array(range(T)) / 10 + t * np.pi))
C = np.zeros((T))
if view:
plt.plot(A)
plt.plot(B)
plt.plot(C)
plt.legend(['sin(θ)', 'sin(θ+150*pi)', 'constant'], fontsize=10, loc=2)
plt.show()
return {'name': 'sin(θ)', 'data': A}, {'name': 'sin(θ+150*pi)', 'data': B}, {'name': 'constant', 'data': C}
def mse(a, b):
return ((a-b)**2).mean()
def get_DWT_results(T, S, skip=1, view=False):
T_data, S_data = T['data'], S['data']
T_name, S_name = T['name'], S['name']
distance, path = fastdtw(T_data, S_data, dist=euclidean)
print("DTW({}, {}):".format(T_name, S_name), distance)
if view:
plt.plot(T_data)
plt.plot(S_data)
k = -1
for i, j in path:
k += 1
if k % skip == 0:
plt.plot([i, j], [T_data[i], S_data[j]],
color='gray', linestyle='dotted')
plt.legend([T_name, S_name], fontsize=10, loc=2)
plt.title('DWT plot result')
plt.show()
return distance, path
def get_derivative(T):
diff = np.diff(T)
next_diff = np.append(np.delete(diff, 0), 0)
avg = (next_diff + diff) / 2
avg += diff
avg /= 2
return np.delete(avg, -1)
def get_DDWT_results(T, S, skip=1, view=False):
T_data, S_data = T['data'], S['data']
dT_data = get_derivative(T_data)
dS_data = get_derivative(S_data)
T_name, S_name = T['name'], S['name']
distance, path = fastdtw(dT_data, dS_data, dist=euclidean)
print("DDTW({}, {}):".format(T_name, S_name), distance)
if view:
plt.plot(T_data)
plt.plot(S_data)
k = -1
for i, j in path:
k += 1
if k % skip == 0:
plt.plot([i+1, j+1], [T_data[i+1], S_data[j+1]],
color='gray', linestyle='dotted')
plt.legend([T_name, S_name], fontsize=10, loc=2)
plt.title('DDWT plot result')
plt.show()
return distance, path
def get_test_curves_DDTWvsDWT(view=False):
T = 150
t = .4
A = np.zeros((T))
B = np.zeros((T))
# A = np.sin(np.array(range(T)) / 10)
# B = np.sin(np.array(range(T)) / 10+2)+50
s_i = 50
e_i = 60
for i in range(s_i, e_i, 1):
A[i] = np.sin(np.pi*(i-s_i)/(e_i-s_i))
# B[i] = -2.2
if view:
plt.plot(A)
plt.plot(B)
plt.legend(['sin(θ)', 'sin(θ+150*pi)'], fontsize=10, loc=2)
plt.show()
return {'name': 'down', 'data': A}, {'name': 'up', 'data': B}
def main():
print("=== main ===")
# A, B, C = get_test_curves()
A, B = get_test_curves_DDTWvsDWT()
# A["data"] = np.array([2, 0, 1, 1, 2, 4, 2, 1, 2, 0])
# B["data"] = np.array([1, 1, 2, 4, 2, 1, 2, 0])
print("{}-{}:".format(A['name'], B['name']), mse(A['data'], B['data']))
# print("{}-{}:".format(A['name'], C['name']), mse(A['data'], C['data']))
# DTWを計算
get_DWT_results(A, B, skip=5)
get_DDWT_results(A, B, skip=5)
if __name__ == "__main__":
main()
応用記事
DTW(Dynamic Time Warping)動的時間伸縮法 by 白浜公章で2,940社の日本企業の株価変動のクラスタリングをDTWとDDTWを使い、結果の違いを比較。使用データは"トムソン・ロイター データストリーム"を使用。DTW+DDTWが株価データを分類・解析するには最適な類似尺度であることを(目視による)定性的評価により結論付けている。
参照3はコードも実験も載っていてかなり参考になる。気温のデータに適用。
また、k-shapeなるものがあるそうです。これは読んでいないが、距離を相互相関とし、k-meansを使いクラスタリングを行う。
感想
実際に時系列データをDTW/DDTWを使ってクラスタリングをしてみたが上手くいかなかった。
あまり、理解ができていないのが原因である。
ご指摘等ありましたらよろしくお願いいたします。