はじめに
AWS AIのサービスに、下記のようなものがある。
- 音声をテキストに変換するtranscribe
- テキストを他言語翻訳するtranslate
- テキストを音声に変換するpolly
これらを組み合わせれば、ほんやくコンニャクができるのではないか?
ちなみに私はおみそ味を食べてみたい。
ということでほんやくコンニャクのLINEBOTを作ってみた。
基本的にはAWSサービスをぽちぽちと繋げていくだけで、LINE設定含め半日あればできる。
世の中のN番煎じではあるが、いろいろとハマッた部分もあったので記録。
構成と流れ
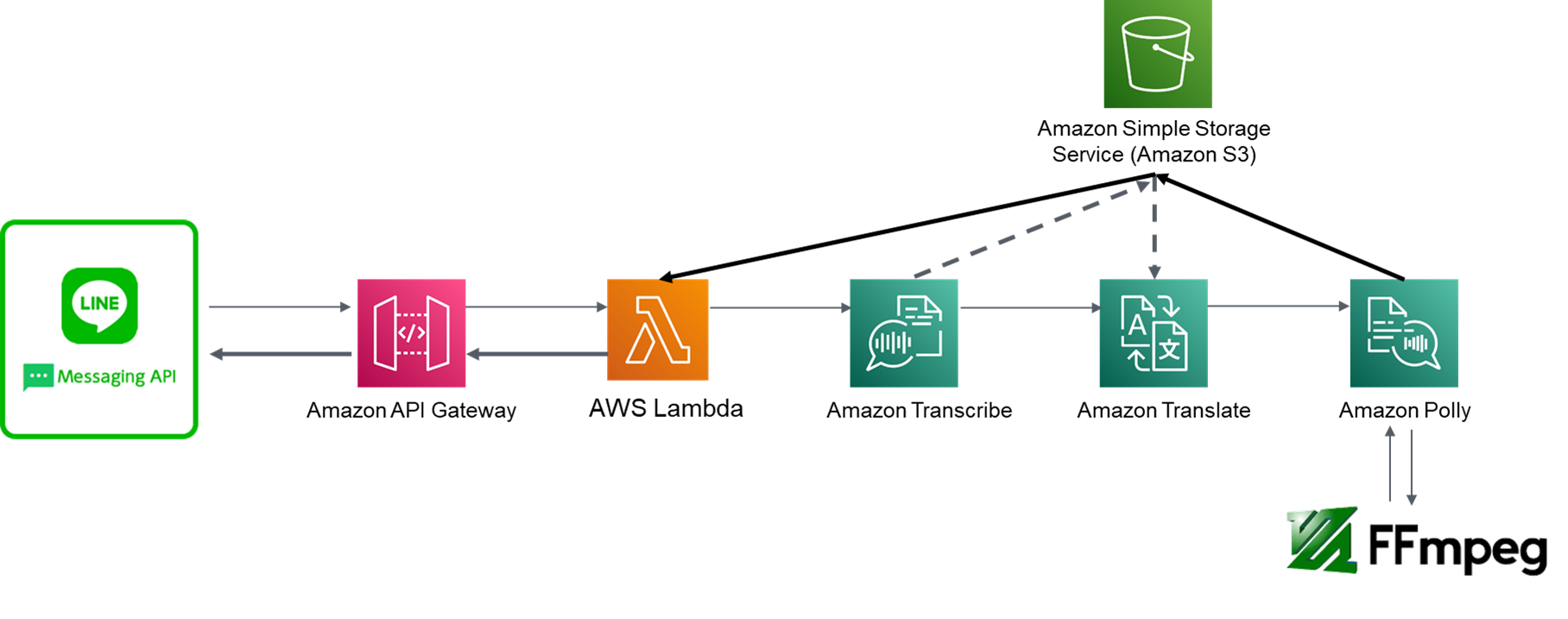
1.LINEから音声データを取得し,S3へ保存(.mp4)
2.S3から1.の音声データを取得してtranscribeで書き起こし,S3へ保存(.json)
3.S3から2.の書き起こしデータを取得してtranslateでテキスト翻訳
4.上記の3.の翻訳データをPollyで音声合成し,S3へ保存(.mp3)
5.S3内の4.のmp3データについて,認証付きURLを発行
6.ffmpegを用いてmp3をm4aフォーマットに変換し,S3へ保存(.m4a)
7.S3内の6.のm4aに5.を適用し,LINEで送信

ざっとコード解説
各手順を関数化したコードを晒していきます。
全体のコードはgithubにて。
1.LINEから音声データを取得し,S3へ保存(.mp4)
s3 = boto3.resource('s3')
def get_content_from_line(event,bucket_name,bucket_key):
if event['message']['type']=='audio':
MessageId = event['message']['id'] # メッセージID
AudioFile = requests.get('https://api-data.line.me/v2/bot/message/'+ MessageId +'/content',headers=HEADER) #Audiocontent取得
Audio_bin = BytesIO(AudioFile.content)
Audio = Audio_bin.getvalue() # 音声取得
obj = s3.Object(bucket_name,bucket_key)
obj.put( Body=content )
return 0
else:
return -1
LINEから送られてきたメッセージがオーディオの場合は,音声の値を取得。
BytesIOを経由して音声ファイルをS3に保存している。
このとき,引数のbucket_keyには.mp4拡張子を付与する。
2.S3から音声データ取得→書き起こし結果をS3へ保存(.json)
transcribe = boto3.client('transcribe')
def speech_to_text(job_name, bucket_name, bucket_key_src, bucket_key_dst):
job_uri = "s3://%s/%s"%(bucket_name,bucket_key_src)
transcribe.start_transcription_job(
TranscriptionJobName=job_name,
Media={'MediaFileUri': job_uri},
MediaFormat='mp4',
LanguageCode='ja-JP',
OutputBucketName=bucket_name,
OutputKey=bucket_key_dst,
)
while True:
status = transcribe.get_transcription_job(TranscriptionJobName=job_name)
if status['TranscriptionJob']['TranscriptionJobStatus'] in ['COMPLETED', 'FAILED']:
break
print("Not ready yet...")
time.sleep(5)
return 0
transcribeは,s3のuriを指定することができる。また,保存先のS3キーも引数で指定。
そしてwhile TrueでステータスがCOMPLETED/FAILEDになるまで抜けられない。
後述するが,このパートはとても時間がかかる。(もともと、議事録等の長文でこそ力を発揮するサービスのため)
3.S3から2の書き起こしデータを取得→translateでテキスト翻訳
# 3-1.
def get_content_from_s3(bucket_name,bucket_key):
obj = s3.Object(bucket_name,bucket_key)
body = obj.get()['Body'].read()
json_data = json.loads(body.decode('utf-8'))
print(json.dumps(json_data))
transcript=json_data['results']['transcripts'][0]['transcript']
return transcript
# 3-2.
translate = boto3.client('translate')
def translate_transcript(transcript):
res_trans = translate.translate_text(
Text=transcript,
SourceLanguageCode='ja',
TargetLanguageCode='en',
)
res_text=res_trans['TranslatedText']
print('original:%s'%transcript)
print('translated:%s'%res_text)
return res_text
2で保存したtranscriptのファイル(json)を,3-1でstringとして取得している。
そしてそれを3-2のAWS translateに食わせてテキスト翻訳をしている。
SourceLanguageCodeにja(日本語),TargetLanguageCodeをen(英語)に指定。
TargetLanguageCodeの設定により,任意の言語での翻訳機を実現できる。
4.翻訳データをPollyで音声合成し,S3へ保存(.mp3)
def synthesize_speech(text,bucket_name,output_key):
bucket=s3.Bucket(bucket_name)
response = polly.synthesize_speech(
Text=text,
Engine="neural",
VoiceId="Joanna",
OutputFormat="mp3",
)
with closing(response["AudioStream"]) as stream:
bucket.put_object(Key=output_key, Body=stream.read())
return 0
pollyを用いた音声合成。Engine=neuralにするとより自然な音声になる。VoiceIdはお好みで。OutputFormatは,mp3を指定(のちにffmpegでm4aに変換)。
5.データの認証付きURLを発行
def get_signed_url(bucket_name, bucket_key):
s3_source_signed_url = s3_client.generate_presigned_url(
ClientMethod='get_object',
Params={'Bucket': bucket_name, 'Key': bucket_key},
ExpiresIn=10,
)
return s3_source_signed_url
ffmpegへmp3データを渡すため,Pollyで生成したmp3データの認証付きURLを発行する。
この操作は,ffmpeg目的以外に,LINEへメディアを送信する際にも必要になる。
これにより,S3のデータを第三者が一時的に操作できる。「一時的」な時間は引数のExpiresIn(秒)で指定。
6.ffmpegを用いてmp3をm4aフォーマットに変換し,S3へ保存(.m4a)
def convert_mp3_to_aac(url, bucket_name, bucket_key_dst):
ffmpeg_cmd = "/opt/bin/ffmpeg -i \"" + url + "\" -f adts -ab 32k -"
command1 = shlex.split(ffmpeg_cmd)
p1 = subprocess.run(command1, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
resp = s3_client.put_object(Body=p1.stdout, Bucket=bucket_name, Key=bucket_key_dst)
return 0
ここでffmpegを用いた処理を行っている。ffmpegコマンドの詳細は割愛するが,「mp3をm4aに変換」を行っている。末尾に「-」を付与することで標準出力として変換データを得られる。これにより,s3に保存する際もp1.stdoutとすることでm4aフォーマットでのデータを保存可能。
7.LINEで音声ファイルを送信
REQUEST_MESSAGE = [
{
'type': 'audio',
'originalContentUrl': url,
'duration': 5000 #ms
},
]
payload = {'to': userId, 'messages': REQUEST_MESSAGE}
response = requests.post(
'https://api.line.me/v2/bot/message/push', #not the 'reply' message
headers=HEADER,
data=json.dumps(payload)
)
print('request sent!')
ここでREQUEST_MESSAGEに音声を指定。ContentUrlには,先ほど5で述べた認証URLを発行し指定する。
ここでのポイントは,replyでなくpushメッセージとしてリクエストを送信すること。
replyTokenには30秒の期限があり,処理が30秒を超えるとtokenが無効となり送り返すことができない。
そこで,replyではなくUserIDを指定してpushメッセージとして送信する。
ハマりポイント
特にハマッた二つのポイントについて詳細説明。
6. LINEへの音声ファイル送信エラーの対策
LINEに音声メッセージを送る際,その対応フォーマットはm4aのみ。
一方で,Pollyで合成された音声の出力フォーマットはmp3/ogg/pcm。
つまり,Pollyの音声をそのままLINEに送ることはできない。
そこで,ffmpegを用いてmp3をm4aに変換してあげる。
幸い公開LamdaLayerが存在するので,これを使わせていただく。
7. LINEのreplyTokenタイムアウトの対策
今回の構成ではreplyTokenのタイムアウトを超えるため,対処が必要。
というのも、AWS transcribeは非常に時間がかかる。5秒の音声でも書き起こしに20秒近くかかる(※)。
今回は短文想定なので,その他処理を合わせるとLINEのreplyTokenのタイムアウト時間(30秒)を超えてしまう。
これに対処するために,LINEにメッセージを送り返すとき,replyTokenによるreplyリクエストではなく,ユーザー指定によるpushリクエストを発行してあげる。
詳しくはLINE Developersの公式ドキュメントを参照されたい。
いや,そもそも応答に30秒以上かかるbotなんてありえない→ごもっともです。今回はAWSで全部試した結果こうなりました。
(※)補足:AWS transcribeは,本来は議事録などの長文書き起こし向け。なので例えば60分の音声が15分で書き起こし完了する,という点ではウマミがある。
まとめ
今回はやっつけで全部AWSで実現させました。そのためbotと呼ぶにはおこがましいほどの高遅延翻訳機になりました。
とりあえず書いてみたレベルですが,一個人が半日でこういうシステムを作る時代になりました。
今後は各種モジュールの高速化を図って,使い物になるLINEbotにできれば良いですね(他人目線)。
議事録などの長文であれば,WEBアプリ化しても良いかもしれません。需要は低そう。
詳細コードはgithubにて。