動機
Alexaに話者登録をするとき、簡単な言葉を2、3文発するだけで登録できてしまいます。
最近の話者認識はすごいなあ。どうやってるんだろうなあ。なんかやってみよ。
話者認識について
話者認識の特徴量と言えばi-vectorをよく聞きますよね。
音素にはMFCC。画像にはHOG。話者にはi-vector。そんな時代もありました(なお現役?)。
いまはディープラーニング主流の時代ということで、
スペクトログラムを用いた話者認識(分類問題)をやってみようと思います。
文字通り,声紋認証ですね!
学習データについて
男女5人ずつの音声データを用意します。ひとりあたり60~80秒。相当短いです。
VGG16は入力サイズが(224,224,3)なので,それに合わせてスペクトログラムをつくります。
使用モデルについて
世の偉人の力を借りて、画像分類モデルVGG16を用いた転移学習(Transfer Learning)しようと思います。
学習データが相当少ないこともあり、転移学習の威力を実感するにはちょうど良い?
学生時代は「少ない話者データから頑健な音響モデルをつくる」みたいなことをやっていたので、なんだか哀愁も漂ってきました。
特徴量抽出
繰り返しになりますが、音を画像モデルとして扱うので、特徴量はスペクトログラムを用います。
周波数はメル変換せず、対数スペクトログラムでやってみます。
パラメータ設定は音声信号処理でよく使われる下記の設定にしました。
| パラメータ | 変数名 | 値[単位] | |
|---|---|---|---|
| サンプリング周波数 | FS | 16000[Hz] | |
| FFTポイント数 | FFTSIZE | 512[pt] | 0.032[s] |
| STFTフレーム長 | FRAMESEC | 0.025[s] | |
| STFTオーバーラップ割合 | OVERLAPRATIO | 0.6 | 60% |
| オーバーラップ割合はフレーム長に対しての割合、つまり15msになります。 | |||
| FFTの窓関数はhann窓を使います。 |
from scipy.signal import stft
import numpy as np
# -- constant parameters
FS=16000
FFTSIZE=512
FRAMESEC=.025
OVERLAPRATIO=.6
# -- function for feature extraction
def normalize8(X):
'''
normalize 0-1 unsigned 8 bit
'''
mn,mx = X.min(),X.max()
mx -= mn
X = ((X - mn)/mx)*255
return X.astype(np.uint8)/255
def make_spectrogram_224(x):
f,t,S=stft(x,
fs=FS,
nperseg=int(FRAMESEC*FS),
noverlap=int(FRAMESEC*FS*OVERLAPRATIO),
nfft=FFTSIZE) #(257,226)
S_mag=np.abs(S)
S_log=20*np.log10(S_mag)
S_8bit=normalize8(S_log)[4:228,:] #125[Hz]~7125[Hz]
S_8bit_3d=np.dstack((S_8bit,S_8bit,S_8bit)) #画像を3次元にする
#-- スペクトログラムを224列ごとに区切る
_S=S_8bit_3d[:,:224*(S_8bit_3d.shape[1]//224)] #余りを切り捨て
S_8bits=np.array_split(_S,_S.shape[1]//224,axis=1) #224列ごとに区切る
return f[:224],t[:224],np.array(S_8bits)
- 画像サイズを(224,224)にするために、前述のパラメータ条件下でお行儀悪くハードコーディングしています。
- make_spectrogramでスペクトログラムを実際に計算して、時間方向に224個ずつに区切ってリスト化しています。
このとき、dstackで画像を3次元にしています(VGG16の入力サイズ(224,224,3)の部分を作っています)。 - normalize8は、値をunsignedの8bitに正規化して、画像と同じ値域[0,255]にする役割を担います。
ここでは計算したスペクトログラムに対して8bit正規化を行っています。
ちなみに、一枚の画像は↓こんな感じになります。
今回のパラメータでは、時間は約2.23秒間&周波数は125~7125Hzです。
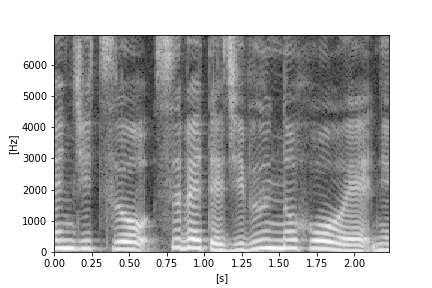
なんと美しい声紋なのでしょうか。
モデル定義
ではモデルをつくっていきます。今回はVGG16が元なので、kerasでimportしてきます。
なんと便利な世の中なのでしょうか。
# keras VGG16
from keras.models import Model
from keras.layers import Dense, GlobalAveragePooling2D,Input
from keras.applications.vgg16 import VGG16
n_categories=10
n_nodes=1024
base_model=VGG16(weights='imagenet',include_top=False,
input_tensor=Input(shape=(224,224,3)))
# -- 自作のモデルを連結
x=base_model.output
x=GlobalAveragePooling2D()(x)
x=Dense(n_nodes,activation='relu')(x)
output=Dense(n_categories,activation='softmax')(x)
model=Model(inputs=base_model.input,outputs=output)
# VGG16のレイヤー重みを固定
for layer in base_model.layers[:15]:
layer.trainable=False
model.compile(optimizer='Adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.summary()
モデルの後半はこんな感じになります↓
block5_pool (MaxPooling2D) (None, 7, 7, 512) 0
global_average_pooling2d (G (None, 512) 0
lobalAveragePooling2D)
dense (Dense) (None, 1024) 525312
dense_1 (Dense) (None, 10) 10250
モデル学習
データを訓練/テストに分けて学習します。
# -- split parameters
from sklearn.model_selection import train_test_split
from keras.utils import np_utils
Y=np_utils.to_categorical(Y, len(id_all)) #one-hot
X_train, X_test, y_train, y_test = train_test_split(X, Y,test_size=.2,random_state=42)
# -- model training
result=model.fit(X_train, y_train, batch_size=32, epochs=40)
# -- model plot
plt.plot(result.history['loss'])
plt.plot(result.history['accuracy'])
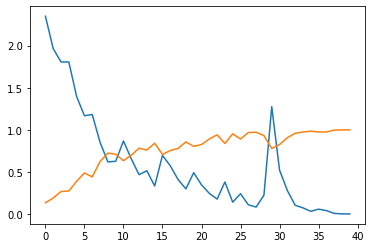
エポックごとのlossと正解率の推移は↑のような感じになりました。順調に学習が進んでいます(か?)
↓そしてモデルの汎化精度は90%程度でした。
訓練データでは100%を達成しているので、過学習のニオイもします...
# -- model evaluate
>>model.evaluate(X_test, y_test)
3/3 [==============================] - 1s 229ms/step - loss: 0.2917 - accuracy: 0.9136
[0.2916698753833771, 0.9135802388191223]
中間特徴量の可視化
出力で10ノードにする手前の、n_nodes次元の特徴量を可視化してみます。
精度100%の訓練データを用いることにします。
二次元に可視化するためにお馴染みのPCAを用います。
話者毎とは言わずとも、男女毎に線形分離可能っぽい分かれ方をしていると良いなあ
# -- 中間層の値を出力
layer_name = 'dense' # n_nodes数を持つDenseLayerの名前を指定
hidden_layer_model = Model(inputs=model.input, outputs=model.get_layer(layer_name).output) # 新たにモデルを生成
hidden_output = hidden_layer_model.predict(X_train)
# -- PCA
from sklearn.decomposition import PCA
pca = PCA(n_components=3)
X_pca=pca.fit_transform(hidden_output)
# -- PCA処理結果をプロット
_y=np.argmax(y_train,axis=1) #one-hotを1次元ベクトルに戻す
fig = plt.figure(figsize=(8,6))
ax = fig.add_subplot(111)
ax.scatter(X_pca[:, 0], X_pca[:, 1], c=_y,cmap='jet')
ax.set_xlabel('Principal Component 1', size=14)
ax.set_ylabel('Principal Component 2', size=14)
ax.set_title('PCA', size=16)
plt.show()
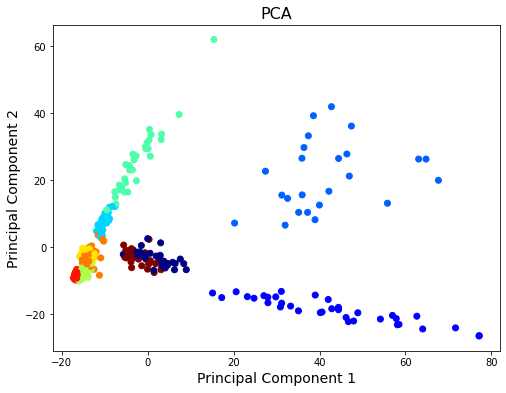
座標的には密集していますね...
三次元でみたらどうなる?

X-Y平面→X-Z平面に。こう見ると、しっかりくっきり分かれていそうです!
カーネル法の説明図みたいになってしまいましたが、3次元空間でもそれなりに特徴が捉えられていることがわかります。ちなみにこの3次元の累積寄与率は80%でした。
じゃあn_nodesもそんなに大きくなくて良いかも。
まとめ
今回は、学習済みモデルであるVGG16を用いた声紋認証を行ってみました。
男女各5人ずつ、そして1人あたりの声紋画像は25~30枚程度(1枚2.2秒)と非常に少ないデータ数でした。
それでも、汎化性能で90%と高い正解率。元モデルが画像分類用(≠音声)のモデルであることも興味深いです。
VGGishやYAMNet、ASTなど音声分類用の学習済モデルもあるので、それらを用いることでさらなる精度向上や応用もできそうですね。
とりあえず今回のモデルを組み込んで声紋認証でロック解除!とかできたら面白そうです。