はじめに
Pyhonは、近年ではスタンダードになりつつあるプログラミング言語で、プログラミング初心者にもとっつきやすく、一方でAI開発などの高度な使い方までができるのが特徴となっています。
以前に、Pythonの超初心者向けとして、
【初心者向け】GoogleColabでPythonを使ってみよう!
https://qiita.com/tech-nami/items/5ccc313539563eeab117
という記事を投稿させていただきましたが、その後、子供の情報の授業で、GoogleColabでPythonを使って何かプログラムを作れという課題が出て頑張っているのを見て、私も少しやってみようと思い、成績管理をするイメージでプログラムを作ってみました。
CやJavaは理解しているつもりですが、Pythonは配列などのデータの扱いがこれまでの言語とは異なるため、少し苦労しました。もちろん便利に自動化してくれていると思うのですが、逆にC言語等で開発してきた私にとっては少し理解しにくく、難しく感じます。正直まだ完成形とは言えない状態ですが、こんな感じで使えるよ、といった参考になれば幸いです。
#ここをこう改善すべきというご意見がございましたら、ぜひコメントください!
GoogleColabでPythonを使って成績をグラフ化
まずは、GoogleColabで新しいノートブックを準備をしてください。
(参考)【初心者向け】GoogleColabでPythonを使ってみよう!
https://qiita.com/tech-nami/items/5ccc313539563eeab117
1.「Colaboratoryへようこそ」画面にて、
「ファイル」「ドライブの新しいノートブック」を選択します。

2.新しいノートブックが表示されるので、

早速ですが、下記のように入力して実行してみてください。
import pandas as pd
import numpy as np
from google.colab import files
from IPython.display import display, HTML
import matplotlib.pyplot as plt
# 日本語対応のmatplotlibをインストール
import importlib
if not importlib.util.find_spec('japanize_matplotlib'):
!pip install japanize-matplotlib
import japanize_matplotlib
# ファイル名をファイル指定ダイアログにて取得
uploaded = files.upload()
if not uploaded:
print("ファイルがアップロードされませんでした。")
exit()
file_name = list(uploaded.keys())[0]
# ファイルの拡張子によってメソッドを変更して読み込み
if file_name.endswith('.csv'):
df = pd.read_csv(file_name, encoding='utf-8')
elif file_name.endswith(('.xls', '.xlsx')):
df = pd.read_excel(file_name)
else:
print("対応していないファイル形式です。")
exit()
subjects = ['英語', '数学', '国語', '理科', '社会', '情報']
for subject in subjects:
if subject not in df.columns:
print(f"{subject}列が見つかりません。")
exit()
# 合計点、平均点、偏差値の計算
df['合計点'] = df[subjects].sum(axis=1)
df['平均点'] = df[subjects].mean(axis=1).round(1)
df['偏差値'] = ((df['合計点'] - df['合計点'].mean()) / df['合計点'].std() * 10 + 50).round(1)
# 科目ごとの成績比較グラフを作成
plt.figure(figsize=(10, 6))
plt.bar(df['氏名'], height=df['英語'], label=df['英語'], color='red')
plt.bar(df['氏名'], height=df['数学'], bottom=df['英語'], label=df['数学'], color='blue')
plt.bar(df['氏名'], height=df['国語'], bottom=df['英語']+df['数学'], label=df['国語'], color='yellow')
plt.bar(df['氏名'], height=df['理科'], bottom=df['英語']+df['数学']+df['国語'], label=df['理科'], color='skyblue')
plt.bar(df['氏名'], height=df['社会'], bottom=df['英語']+df['数学']+df['国語']+df['理科'], label=df['社会'], color='green')
plt.bar(df['氏名'], height=df['情報'], bottom=df['英語']+df['数学']+df['国語']+df['理科']+df['社会'], label=df['情報'], color='purple')
plt.legend(subjects, labelcolor=['red', 'blue', 'yellow', 'skyblue', 'green', 'purple'], handlelength=0, loc='best')
# グラフに表示するラベルを設定
plt.title('生徒ごとの合計点比較')
plt.xlabel('氏名')
plt.ylabel('合計点')
plt.xticks(ticks=df['氏名'], labels=df['氏名'])
# 偏差値を折れ線グラフで表示
plt.plot(df['氏名'], df['偏差値']*10-100)
plt.xticks(rotation=90) # x軸ラベルを回転
plt.tight_layout() # ラベルが重ならないように調整
plt.show() # グラフを表示
#dfに設定した成績情報をHTMLの表形式で表示
display(HTML(df.to_html(index=False, border=0)))
print("\n科目別平均点")
for subject in subjects:
print(subject+":"+str(df[subject].mean().round(1)))
#全科目合計の平均点を表示
print("\n全科目合計平均点:"+str(df["合計点"].mean().round(1)))
これを実行すると、入力するファイルを聞かれますので、
デスクトップ等に下記の様なExcelファイル(またはCSVファイル)を作成しておき、

そのファイルを指定すると、下記のようなグラフが表示されます。
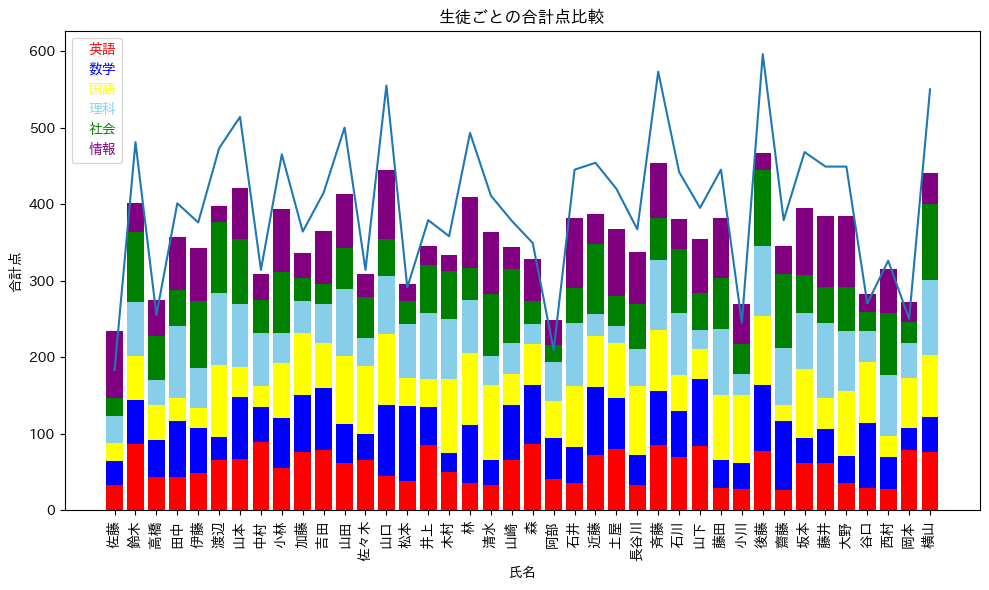
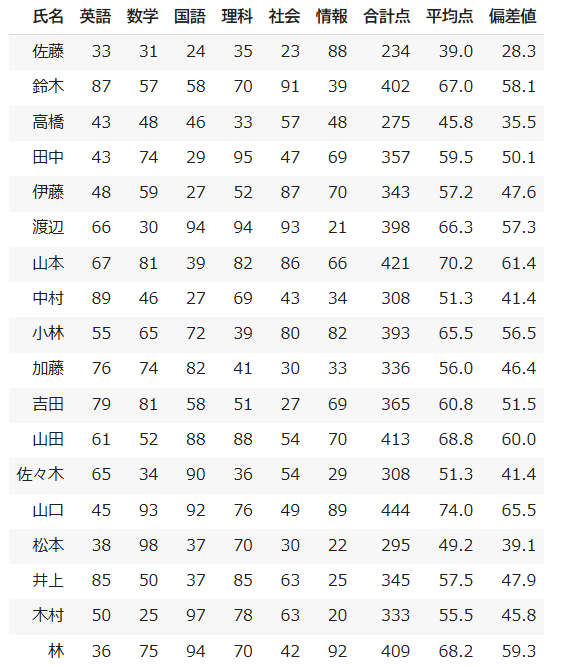
また、その下に、このような表が表示されます。
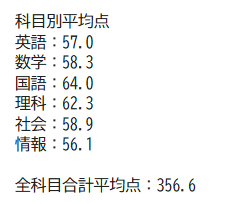
(追記)科目ごとの平均点と、合計点の平均点も出力するようにしました。
参考までに、下記の様に 「AIで生成」 に依頼することで、名前リストを簡単に作成できます。
(生成されたコードを実行すると、Excelに張り付けやすいリストができます)
# prompt: 適当な日本人の苗字を40個作成するプログラムを作成してください。
# 苗字は重複しないようにして、1つごとに改行してください。
surnames = ["佐藤", "鈴木", "高橋", "田中", "伊藤", "渡辺", "山本", "中村", "小林", "加藤",
"吉田", "山田", "佐々木", "山口", "松本", "井上", "木村", "林", "清水", "山崎",
"森", "阿部", "石井", "近藤", "土屋", "長谷川", "斉藤", "石川", "山下", "藤田",
"小川", "後藤", "齋藤", "坂本", "藤井", "大野", "谷口", "西村", "岡本", "横山"]
for surname in surnames:
print(surname)
プログラムのポイント
簡単に、私の考えるポイントについて記載します。
・日本語のラベルを使ったグラフ作成には、「japanize_matplotlib」が使える
・パッケージのインストールができていない場合、
import importlib
if not importlib.util.find_spec('japanize_matplotlib'):
!pip install japanize-matplotlib
import japanize_matplotlib
のように記載すると、1つのコードセル内でインストールを済ませることができる。
(当初try~exceptで記載していましたが、コメントを頂き、そちらの方が良い記載方法と思い、差し替えさせていただきました)
・ファイル名をファイル指定ダイアログにて取得するには、
from google.colab import files
uploaded = files.upload()
file_name = list(uploaded.keys())[0]
のように記載することで実行できる。
・グラフの作成には matplotlib を使い、次の手順で実施しました。
英語、数学、国語、理科、社会、情報の順に積み重ねるように棒グラフを設定する。
英語の点数を bottom として、そこに数学を重ねる
英語+数学の点数を bottom として、そこに国語を重ねる
・・・
といった方法で棒グラフを重ねていってます。
(が、もっと良い方法がありましたら教えてください)
・棒グラフの下に、HTMLの表形式で出力しています。
pandas の dataframe にデータを格納しておくことで、
display(HTML(df.to_html(index=False, border=0)))
の様に記載するだけできれいに整形して表示してくれます。
今回、GoogleColab の「AIで生成」に、下記のプロンプトを入力して、ソースのベースを作成してもらったのですが、科目ごとのグラフを重ねる部分をうまく伝えることができず、自力で試行錯誤して表示できるようになりました。
# prompt: excelまたはcsvファイルを読み込みます。ファイルはユーザがファイル選択より選択して指定するようにしてください。
# ファイルには、生徒の氏名と、生徒ごとの英語、数学、国語、理科、社会、情報の点数が記載されています。
# 生徒ごとの合計点、平均点、偏差値を表示してください。また、生徒ごとの合計点の比較をするグラフを作成してください。
# また、科目ごとの成績を比較するグラフも作成してください。
# matplotlibを使ってグラフを描画し、合計、平均、標準偏差、最大値、最小値を求めるプログラムを作ってください
まとめ
今回は、GoogleColab上で、Pythonを使って
①Excel/CSVファイルをファイルダイアログを使って読み込む
②pandas の dataframe を使ってグラフを描画する
③pandas の dataframe を使ってHTMLの表形式でデータを出力する
といったプログラムを作成することについて記載しました。
みなさんも、Pythonを使っていろいろなプログラムを作ってみてください!