はじめに
OpenAIのChatGPTを皮切りに、生成AIが急速に発展しています。GoogleのGeminiは、その中でも特に注目を集める大規模言語モデルです。Gemini APIは、この強力なモデルをプログラムから利用できるインターフェースを提供し、テキスト生成だけでなく、画像認識など、多様なタスクに対応可能です。本記事では、Gemini APIのマルチモーダル機能に焦点を当て、画像認識の簡単な例を通して、その可能性を探ります。
Google AI Gemini APIとは
OpenAIでいうGPTに相当するLLM(大規模言語モデル)として、GoogleのGemini(ジェミナイと呼ぶらしい)というモデルが有名ですが、このGeminiは、インターネットからチャット形式での対話ができる環境が公開されています。
もちろん、この環境でもある程度の機能は使えるのですが、アプリケーションプログラマーとしては、APIをつかって、自分のプログラムから呼び出してみたいという衝動に駆られます。Googleからは、本格的なAI開発基盤である、VertexAIが提供されており、VertexAIの機能を使うには、Vertex AI Gemini APIというAPIを使うことで呼び出しが可能になっていますが、それと並行して、もっと気軽に使うことができる、Google AI Gemini APIというAPIがあります。このAPIを使ってGoogle Colabから呼び出しができる仕組みが提供されているので、そちらを使っていろいろ試してみたいと思います。
Google AI Gemini APIのAPIキーを取得
ブラウザより、Google AI Studioの画面を表示します。
https://ai.google.dev/aistudio
画面は結構更新されることがある様ですが、この画面のどこかに、
「Gemini APIキーを取得する」というアイコンがありますので、それをクリックします。
「API キーを取得」画面が表示されますので、その画面の中の「APIキーを作成」ボタンを
押すと、クリップボードにAPIキーがコピーされます。
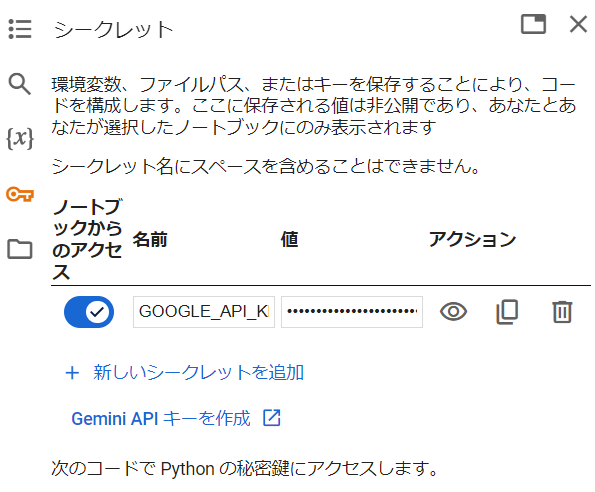
Google Colabの鍵アイコンをクリックすると、シークレットが表示されるので、
名前:「GOOGLE_API_KEY」、値をクリップボードの値をペーストして、
シークレットを保存します。
Google Colab上でAPIをインストールする
Google Colabのノートブックを開き、下記を実行します。
!pip install -q -U google-generativeai
続いて、下記を実行して、APIキーを設定します。
from google.colab import userdata
import google.generativeai as genai
GOOGLE_API_KEY = userdata.get('GOOGLE_API_KEY')
genai.configure(api_key=GOOGLE_API_KEY)
次に、利用可能なモデルを確認します。
for m in genai.list_models():
if "generateContent" in m.supported_generation_methods:
print(m.name)
下記の様に、利用可能なモデルのリストが返されます。
models/gemini-1.0-pro-latest
models/gemini-1.0-pro
models/gemini-pro
models/gemini-1.0-pro-001
models/gemini-1.0-pro-vision-latest
models/gemini-pro-vision
models/gemini-1.5-pro-latest
models/gemini-1.5-pro-001
models/gemini-1.5-pro-002
models/gemini-1.5-pro
models/gemini-1.5-pro-exp-0801
models/gemini-1.5-pro-exp-0827
models/gemini-1.5-flash-latest
models/gemini-1.5-flash-001
models/gemini-1.5-flash-001-tuning
models/gemini-1.5-flash
models/gemini-1.5-flash-exp-0827
models/gemini-1.5-flash-8b-exp-0827
models/gemini-1.5-flash-8b-exp-0924
models/gemini-1.5-flash-002
モデルへの簡単な質問をしてみる
さて、いよいよモデルへの接続です。利用可能なモデルの中から選び、下記を実行します。
model = genai.GenerativeModel("models/gemini-1.5-pro")
モデルへの接続ができましたので、続いてクエリしてみましょう。
response = model.generate_content("Google Gemini APIとは?")
print(response.text)
通常のチャットと同様に、すぐに結果が返ってきます。
Google Gemini API は、Google が開発した大規模言語モデル Gemini を利用したアプリケーションプログラミングインターフェースです。Gemini API を使用すると、開発者は Gemini の高度な言語理解および生成機能をアプリケーションに統合できます。
Gemini API は、次のような機能を提供します。
* テキスト生成
* テキストの要約
* 翻訳
* 質疑応答
* 会話生成
* コード生成
・・・(略)
この様に、Google AI Gemini APIを使うと、非常に簡単にAPIを経由した推論が実行できます。
モデルに読み込み画像への質問をしてみる
マルチモーダルと題しておりますので、簡単ですが画像についても扱ってみます。
まずは、対象となる画像ファイルを準備しておきます。
Google Colabのフォルダアイコンをクリックすると、フォルダが表示されるので、
「content」直下に準備した画像ファイルをドラッグ&ドロップします。

(上記では、test_img1.jpgをコピーしました)
次に、PILという画像イメージを扱うライブラリを使って、画像を読み込みます。
最後の「image」行で画像を表示します。
import PIL.Image
image = PIL.Image.open("test_img1.jpg")
image

先ほど利用したモデルをそのまま使って、質問を行います。
response = model.generate_content([image, "これは何の画像ですか"])
print(response.text)
結果は次の通りです。
これは、柴犬のぬいぐるみの画像です。
概ね予想通りの回答を返してくれました。
(追記)マルチモーダルのすごいところ
この他にも、wavなどの音声データを読み込み、文字起こしや要約を作成することや、mp4等の動画データを読み込み、その動画の要約や、物語であればストーリーをまとめたり、シーンごとに何が描写されているのかを説明してくれたりします。(画像か音声か動画かは自動的に判別してくれます)
それも、基本的に画像の手順と同様に、対象となる音声データや動画をアップロードし、それに対して問い合わせを行うだけです。
まとめ
今回は、Google AI Gemini APIを使って、簡単ではありますが、マルチモーダルの初歩的な確認を行いました。
引き続き、もう少し高度な使い方についてもご紹介していきたいと思います。