はじめに
この記事では、巷で「この技術によりGPUが不要になるかもしれない、NVIDIAなどの半導体関係の株価が...」と話題になっている、BitNet b1.58についての論文を丁寧に解説します。このMicrosoftが先日発表したBitNet b1.58はそのエネルギー効率の凄まじさから2024年初めの大きな技術改革となるかもしれません!!
筆者の見解
関する論文解説に入る前に、この技術に関する私の個人的な意見を述べたいと思います。
1bitの技術を用いることで達成されたその驚異的なエネルギー効率の高さは、既存の大規模言語モデル(LLM)とは一線を画しています。この技術が今後のAI技術の発展にどのように影響を与えるかについては以降の発表がとても楽しみです。
一方で、「GPUが不要になるかもしれない」という意見に関しては、ある程度の限定的な視点からの意見と言えます。BitNet b1.58は、確かに従来の計算資源に依存しない新たな方向性を示していますが、これは主に推論時の処理においての話であり、モデルの構築や学習においては、GPUは依然として重要な役割を果たすことが予想されます。
むしろ工場やIoTなどのオフライン環境においてのエッジコンピューティングやモバイルデバイスでのAIの利用拡大に大きな影響を与えるため、GPUの価値はより一層高まるのでは、と考えています。
公式リファレンス
本論文
Gitリポジトリ
なお本記事の構成は論文の内容に沿った形で展開させていきます。
概要
何が特別なのか
BitNet b1.58は、その名の通り、各パラメータが$[-1、0、1]$という3つの値での動作を実現した1bitのLLMです。つまり、膨大な計算リソースを必要とする従来のモデルとは異なり、非常に効率的に動作します。加えて、この記事で示されている結果では驚くべきことに、性能は従来の高精度モデルを上回ります。
コスト削減
このモデルの最大の特長は、遅延、メモリ使用量、処理能力、そしてエネルギー消費の大幅な削減にが可能になるという点です。これにより、高性能ながらもコスト効率の良い新世代のLLMの訓練が可能になります。つまりより少ないリソースで、より多くのことが実現可能になるということです。
新しい可能性
BitNet b1.58は、1bitLLM向けの特化ハードウェア設計にも影響を及ぼすと述べられています。これまでのモデルでは考えられなかった、新しい計算パラダイムが実現可能になる可能性を示唆していて、これは、AIの研究だけでなく、産業界においても大きな影響を及ぼすと考えられています。
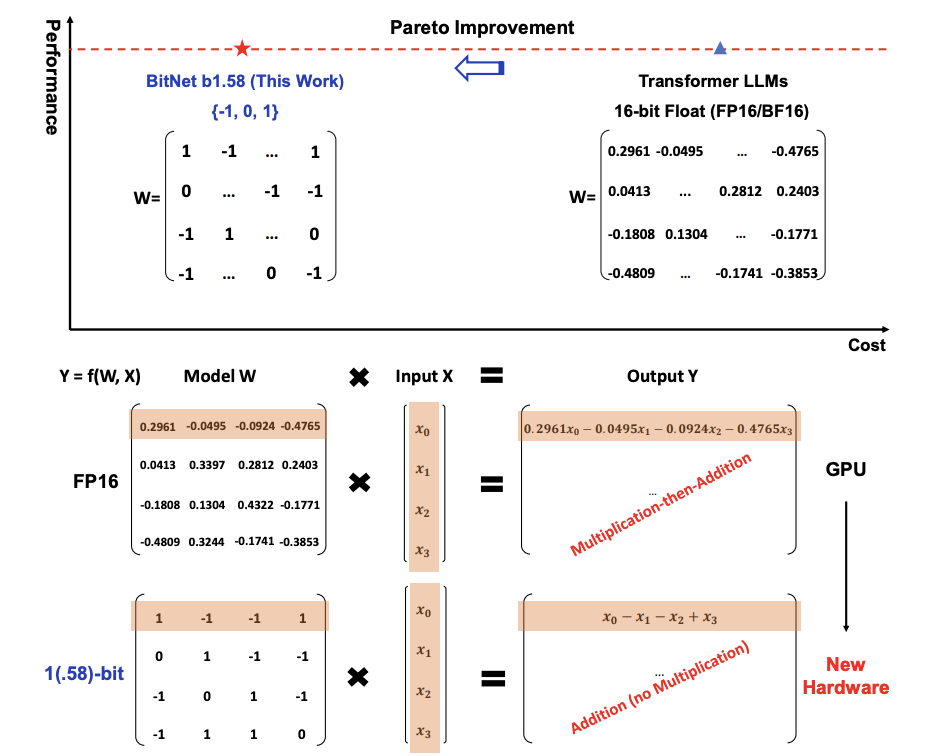
そもそも、b1.58とは何を示しているのか
3つの異なる値$[-1, 0, 1]$を均等な確率でエンコードする場合、エンコードに必要な情報量はエントロピーを用いて計算できます。エントロピーは情報理論において、あるメッセージをエンコードするのに必要なビット数の平均を測る尺度です
3つの値が均等な確率で発生する場合のエントロピー$H$は次の式で計算できます:
$$
H=−∑_{i=1}^np(x_i)log_2p(x_i)
$$
ここで、$p(x_i)$は値$x_i$ の発生確率で、それぞれの値が発生する確率を $1/3$ とすると、
$$
H = -3 × \frac{1}{3}log_2(\frac{1}{3})=log_2(3) \approx1.5849625007211563
$$
よって、この場合、3つの可能な状態を持つシステムのエントロピーが約1.58ビットであることを意味しています。
BitNet b1.58とは
BitNet b1.58は、BitNetアーキテクチャに基づいており、これはnn.LinearをBitLinearで置き換えたトランスフォーマーです。1.58bitの重みと8bitの活性化を用いて、ゼロからトレーニングされます。元のBitNetとのいくつかの変更の導入について下記で紹介します。
量子化関数
重みを$[-1,0,1]$に制約するため、absmean量子化関数を採用している。まず、重み行列をその平均絶対値でスケーリングし、次に各値を$[-1,0,1]$の中で最も近い整数に丸める:
$$
\tilde{W}=RoundClip(\frac{W}{γ+ϵ},−1,1),
$$
$$
RoundClip(x,a,b)=max(a,min(b,round(x))),
$$
$$
γ=\frac{1}{nm}∑_{ij}∣W_{ij}∣
$$
BitNet b1.58の進化における重要な側面の一つは、活性化関数の出力を扱う独自の方法にあリます。通常の計算プロセスでは、活性化関数の出力は特定の範囲内に収められ、量子化された値が実際の数値0をどのように表現するかについて、細心の注意が払われます。このプロセスは「ゼロポイントの調整」と呼ばれ、計算の正確性を保つために不可欠なものです。
しかし、BitNet b1.58はこのプロセスを根本から見直したものです。このモデルでは、活性化関数の出力を0を中心とした範囲$[-Q_b, Q_b]$にスケーリングすることで、ゼロポイントの調整を完全に回避することとなります。この斬新なアプローチにより、モデルの実装とシステムレベルでの最適化において大幅な簡素化を実現しました。
BitNet b1.58のコンポーネント
- RMSNorm: 層の正規化を行う手法で、モデルの安定性と学習速度を向上させる
- SwiGLU: 非線形活性化関数の一種で、モデルの表現力を高める
- 回転埋め込み(Rotary Embedding): シーケンスデータの位置情報をより効果的にモデルに組み込む手法
また、すべてのバイアス項をモデルから取り除くことで、計算の単純化と効率化を図っています。これらの措置により、BitNet b1.58は、既存のオープンソースソフトウェアやフレームワーク(例えば、Hugging Faceやその他のLLM関連のライブラリ)との互換性を持ち、これらのプラットフォームにおいて最小限の労力で使用できるようになっています。
結果
BitNet b1.58とFP16 LLaMA LLMを様々なサイズで比較しました。公平な比較を保証するために、モデルをRedPajamaデータセットで1000億トークンに対して事前学習しました。
その後、モデルの実際の性能を評価するために、様々な言語タスクを用いてモデルが事前学習データを活用し、未知のタスクを解決する能力を測定しました
テストには以下のタスクを使用しています:
- ARC-Easy と ARC-Challenge: 科学的推論を必要とする多肢選択の質問で構成
- Hellaswag: 自然言語の文脈を理解し、与えられたシナリオの最も論理的な続きを予測する能力をテストするためのデータセット
- Winogrande: 特定の文脈で語の意味を理解し、常識的推論を測定するためのデータセット
- PIQA (Physical Interaction Question Answering): 物理的な世界の相互作用に関する問題を解決するAIの能力をテストするためのデータセット
- OpenBookQA: 特定の「オープンブック」の知識を背景に持つ質問で構成
- BoolQ: ブール(Yes/No)質問に答えることで、文書理解の能力をテストするデータセット
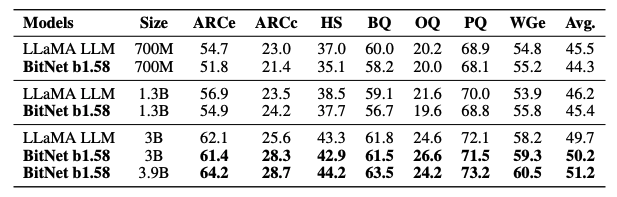
またWikiText2とC4データセットでの検証パープレキシティを検証。パープレキシティは、モデルがテキストをどの程度予測できるかを測る指標で、数値が低いほど良い性能を示唆しています。
- WikiText-2:Wikipediaの記事から抽出されたテキストで構成されており、良質な自然言語テキストを提供
- C4:T5 (Text-to-Text Transfer Transformer) モデルのトレーニングに使用されており、一般的な言語理解と生成タスクのためのモデルを構築する際の基盤
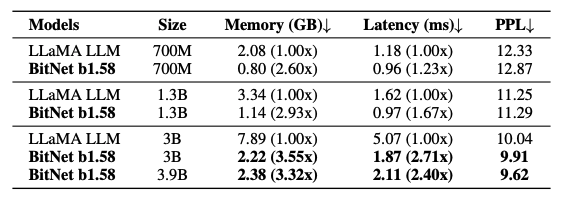
メモリとレイテンシについて
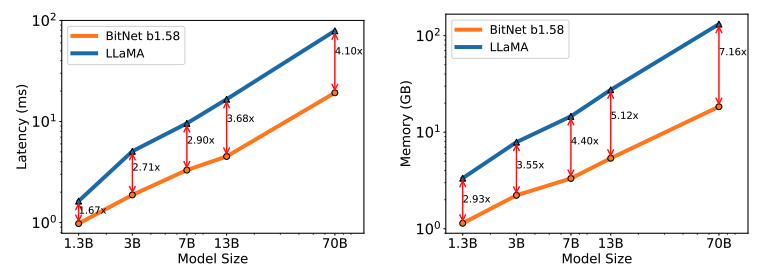
BitNet b1.58モデルの70Bモデルは従来のLLaMA LLMよりも4.1倍の速度を実現しました。しかし、メモリ使用量も大幅に改善することができているが、コストを下げるための最適化を検証し続ける必要があります。
エネルギー消費について
BitNet b1.58は、LLaMA LLMに比べて行列乗算のエネルギー消費を大幅に削減し(約71.4倍効率的)、モデルが大きくなるほどエネルギー効率が良くなります。これは、計算に必要な部分の割合が増え、大きなモデルではコストが相対的に小さくなることを示しています。
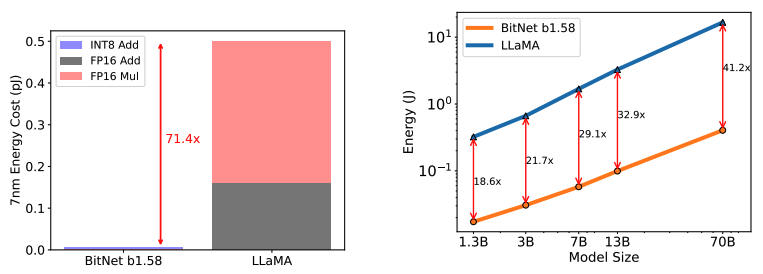
スループットについて
BitNet b1.58 70Bは、LLaMA LLMよりも最大11倍のバッチサイズを扱え、スループットが8.9倍高くなリマス。これは、同じ条件下でBitNet b1.58がより多くのデータを高速に処理できることを意味しています。
BitNet b1.58は、モデルの性能と推論コストに関して新しいスケーリング法則を実現しました。
下記は異なるモデルサイズ間の等価性を示しています。
- 13BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、3BのFP16 LLMよりも効率的
- 30BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、7BのFP16 LLMよりも効率的
- 70BのBitNet b1.58は、レイテンシ、メモリ使用量、エネルギー消費の点で、13BのFP16 LLMよりも効率的
2兆トークンでのトレーニング
最先端のオープンソース3BモデルであるStableLM-3Bのデータレシピに従って、BitNet b1.58モデルを2Tトークンでトレーニングしました。両モデルは、Winogrande、PIQA、SciQ、LAMBADA、ARC-easyを含むベンチマークで評価した。精度と正規化精度で測定されるタスクについては、平均を取得した調査結果では、BitNet b1.58がすべてのエンドタスクで優れたパフォーマンスを達成し、強力な一般化能力を持っていることを示しています。

将来性
1.58bit LLMで解決するMixture-of-Experts(MoE)の課題
メモリフットプリントの削減
1.58bit LLMは、まずメモリフットプリントを大幅に削減。これは、MoEモデルを展開する際に必要となるデバイスの数を減らすことに直結します。メモリ使用量が少なくなると、同じ量の計算を行うために必要なハードウェアリソースが少なくなり、全体的なコストが下がるだけでなく、設置スペースも節約可能になります。
通信オーバーヘッドの削減
さらに、1.58ビットLLMは、ネットワークを介したアクティベーションの転送に関するオーバーヘッドも大幅に削減。これは、データの量が少なくなるため、チップ間やデバイス間でやりとりする情報量が減ることを意味しており結果として、通信の遅延が減り、モデルの応答時間が改善され、効率的な運用が可能になります。
シングルチップへの集約
最も理想的なシナリオでは、全てのモデルを単一のチップ上に配置することです。これが実現すれば、チップ間通信のオーバーヘッドは事実上ゼロにすることができます。これにより、モデルの展開がよりシンプルになり、高速で効率的な運用が実現可能になると確信しています。
LLMでメモリ使用量を削減し長文処理
メモリ効率の改善
BitNet b1.58は、データを表現する際に必要なビット数を従来の16ビットから8ビットに削減することで、メモリ使用量の問題に取り組んでいる。これにより、同じ量のメモリでより長い文章を扱うことが可能になり、言語モデルの適用範囲が大きく広がります。
無損失圧縮への挑戦
さらに、BitNet b1.58の開発チームは、将来的にはデータを4ビット以下に無損失で圧縮する方法を研究しています。これが実現すれば、メモリ使用量をさらに削減しながら長い文章や大規模なデータセットを効率的に処理できるようになることが可能になると期待しています。しかし、この目標にはまだ課題が残っていて、今後の研究で解決を目指しています。
スマートフォンと小型デバイスでの革新
1.58bit技術の革新
1.58bit技術によりスマートフォンや小型デバイスでも高性能な言語処理が実現される。具体的には、データを表現する際に必要なビット数を削減し、同じ量のメモリでより多くの情報を処理可能に、これによりデバイスの性能を最大限に引き出しながら、電力消費を抑えることが可能になります。
新しいアプリケーションの可能性
スマートフォンや小型デバイスで実現可能な新しいアプリケーションや機能が広がります。例えば、リアルタイムでの自然言語理解、高度な会話型AI、翻訳アプリケーションなどが、これまで以上にスムーズに、そして電力を気にすることなく利用できるようになります。
CPUでの効率的な動作
また、1.58ビット技術はCPUにも適しており、これらのデバイスで効率的に動作し、優れた性能を提供。これにより、ユーザーはデバイスの性能に関する妥協をすることなく、高度な言語処理機能を日常生活で活用できるようになります。
1bit LLMのための新しいハードウェア
Groqなどの最近の研究は、大規模言語モデル(LLM)専用の特別なハードウェア(例:LPUs)の開発に成功し、その技術から将来の可能性を大きく秘めています。これに続き、1bit LLMに特化し、最適化された新しいハードウェアとシステムの開発を進めていきます。これは、BitNetで紹介された1.58bitモデルの新しい計算方式を生かすために最適化されたハードウェアとなるでしょう。
終わりに
いかがでしたでしょうか!今回は、BitNet b1.58に関する論文を丁寧に解説しました。
私自身、大規模言語モデル(LLM)に関する知識がまだまだ不足しており、伝えたいことが十分に伝わらなかった部分もあったかと思います。その点については、何卒ご容赦いただければと思います。
また、英語で書かれた論文を日本語に翻訳し、さらにそれをできるだけわかりやすくご説明するという過程で、論文の原文の厳密な表現と異なる箇所が生じてしまった可能性があります。この点で、解釈に誤りがあったり、不自然な日本語があった場合には、ご指摘いただけるとありがたいです!!