Datumixはどのように推薦エンジンを作り出したか
インターネットが世界中に広まり、eコマースのサイトは人々の日常生活の一部となっています。潜在的顧客から注目され購入してもらうために、eコマースサイトは日々成長する競合と比べて秀でていなければいけません。eコマースサイトにおいて最も重要なものの1つは、推薦エンジンです。高性能な推薦エンジンは、顧客の新しい欲求を生み出し、快適なお買い物を可能にします。レコメンドの信頼性が高くなればなるほど、顧客獲得率は上がります。推薦エンジンは、ベストセラーの製品を推薦する時、顧客の購入履歴に合った商品を勧める時、 顧客のカートに似た商品を推薦するとき、など様々な場面で活躍します。
しかし、eコマースの会社が推薦エンジンを開発する際に抱える最大の問題の一つとして、溢れる大量のデータの中からどのように正確に重要な情報を探し出すか、が挙げられます。選択する商品や消費者の嗜好は何万と分かれます。もし推薦エンジンが正しくデータを解釈していなければ、会社は大きな利益を逃している可能性があります。特定のサイトである推薦エンジンが威力を発揮しても、対象となる製品や顧客が違うだけで他のサイトでは使い物にならない可能性があります。そのため、推薦エンジンは大量のデータを得るだけではなく、そのデータからそれぞれの会社の要求を満たした情報のみを抽出しなければなりません。
ユーザーの関心を誤って分析すると、潜在的な利益を逃すことがあります。例えば、新しい商品を欲しているユーザーがその推薦エンジンが効果的でないと判断した場合、競合のサイトに移ってしまうでしょう。そのため、カスタマイズ可能なレコメンドサービスはeコマースの会社の成功に欠かせません。多くの分野で注目されているAIの技術は推薦エンジンに大きく影響します。推薦エンジンのパフォーマンスは、モデルに入力される特徴量に大きく左右されます。Datumixは最新のAI機能を用いて、様々な特徴量を選出/分類することで新しい顧客体験を生み出す推薦エンジンをつくっています。たとえば、ワイド&ディープ学習はDatumixの「Mynee Recommend」というレコメンドに特化したモジュールに搭載されています。このモデルは、少ないデータ量からユーザーの好みを学ぶことができます。
ワイド&ディープ学習
その名の通り、ワイド&ディープ学習は、ワイド学習とディープ学習が統合されています。ワイド学習は 特定のデータを記憶し、誤りなくそのデータを返すことができます。欠点は、顧客が以前検索したもののみしか推薦できないことです。そのため、もしある顧客の購入履歴にバッグしかない場合、バッグの推薦しかすることができません。これに対して、ディープ学習は最初に入力されたデータに関連した汎用的なセットを作ることを得意とし、顧客の好みに合った様々な推薦をすることができます。顧客が過去にバッグだけを買ったならば、ディープ学習は同じブランドの商品、または同じ色の製品を推薦できます。しかし、あらゆる種類の大きなデータに対しては、この汎用化が機能せず、顧客の好みを外してしまう欠点があります。
このワイド学習の特殊性とディープ学習の多様性を統合することで、より正確な推薦を可能にするワイド&ディープ学習が完成します。
最終的には、この2つのモデルの出力結果が一致するならば1が、不一致の場合は0が出力されます。さらにその結果を踏まえ、将来の正確度を上げるためにモデルは再構築されます。Datumixの推薦エンジンの特徴的な点は、各々の顧客のニーズに合わせるためにワイド&ディープ学習法に入力されるデータを編集することができるところです。
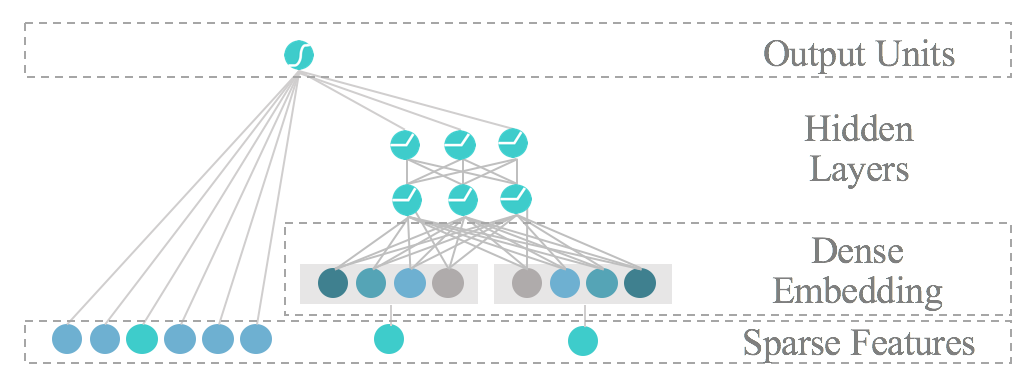
ワイド&ディープ学習モデルは、テキストで書かれた記事データとユーザーデータどちらも取り入れます。私たちの過去のお客様に向けに、Word2vec、CNN、LSTM の三つの技術を用いて、ワイド&ディープ学習モデルに入力する記事データを編集した経験があります。CNNとLSTMは製品の説明と記事データを分類するのに用いられます。この2つは、テキストデータの語の順序に基づき、複数の意味を持つ単語や比喩表現などを正確に分類することができます。
Word2vec
Word2vecは初めに 一組の語(文または製品説明など)を取り入れ、各単語に対し多次元ベクトルを生成します。各々のベクトルは、多次元グラフに入力されます。グラフ中のベクトルの位置は、訓練期間中に、前に入力された情報から相対的に決定されます。グラフ中の2本の単語ベクトルが互いに近くにあるほど、類似性が高いことを示しています。Word2vecの興味深い点は、類似関係のある語群が単純なベクトル加算と減算によって見つかることです。たとえば、v(King)-v(Man)+v(Woman) は v(Queen)となります。このように、一度一般的な関係が見つかれば、他の語に簡単に適用することができます。
Word2vecアルゴリズムは実際に運用されるために訓練期間を経なければなりません。訓練期間の間に、アルゴリズムはある仕事の課題に関する語を含む大きなデータベースを学習します。たとえば、 化粧品サイトの推薦エンジンで使われるWord2vecアルゴリズムは、何万もの美容製品に関する語に対し訓練されます。訓練期間中に時々用いられるロジスティック回帰とは、実際に用いられる役に立つ単語に高い確率を与え、役に立たないノイズとしてみられる単語に低い確率を与えます。
頻繁に用いられる主要なWord2vecとして、Continuous Bag of Words (CBOW)とSkip-gram modelの2つが挙げられます。一般的に、Word2vecは目標の語を予測するために「文脈」を成す周りの単語のベクトルを用いますが、CBOWもまさに同じことをしています。予測したい単語の周りの語を取り入れ、過去のデータに基づき、予測した単語を表示します。一方で、Skip-gram modelはこれとは正反対のことをします。つまり、目標の語を取り入れ、その周りの文脈を作っている語を予測するのです。Datumixは今回、CBOWに比べて大きなデータセットを処理することに優れているSkip-gram modelを使用することにしました。
CNN
次にConvolutional Neural Network(CNN)は大抵、写真識別のために使われる技術です。基本的にCNNは 、写真を取り入れいくつもの層(後で取り上げます)を通して処理した最も重要な特徴量を抽出します。画像認識においてCNNは個々のピクセルをベクトルとみなすので、ベクトルによって表されている限り他の形のデータもCNNを通して処理することができます。よって、CNNはWord2vecによって作成されたベクトルも処理することができるのです!
CNNは主に畳み込み層、プーリング層、全結合層、の3種類の層でできています。CNNは、Word2vecの結果に基づいた入力ベクトルを行列としてとります。その後テキストデータは、行列内で最も重要な特徴を見つけるフィルターとして機能する畳み込み層を通ります。このフィルタは入力データより小さく、入力データの行列の一部分の大きさを持ち、ストライドと呼ばれる値(1ストライドは畳み込み層が一度に1ピクセル動くことを意味する)ずつ行列内を移動していきます。フィルターでカバーされる部分とフィルター自体を掛け合わせることで、 その部分に対応する一つの値を計算します。一旦畳み込み層が全ての行列を処理したのち、掛け合わせによって作られたフィーチャーマップと呼ばれる小さな行列が生成されます。
それから、フィーチャーマップはその代表値を定めるプーリング層を通ります。その代表値はプログラマーによって指定され抽出されます。プーリング層はフィーチャーマップの平均値または最低値をとることができますが、最低値の方がより良い結果を生む傾向があります。各々のフィーチャーマップからの代表値が集められた後、全結合層を通して処理されます。全結合層の一つ一つのニューロンは、前の層のニューロン全てと結合しています。代表値は複数の全結合層を通っていくことによって小さく変えられていきます。全結合層の出力値は、開発者により前もって予想されたいくつかの出力値と比較されます。CNNの最終的な出力値は、全結合層の出力値に最も適合するものになります(ここにあるCNNの説明は単純化されたもので、多くのCNNはこれらの層を複数重ねたものです )
一旦テキストデータがWord2vecとCNNを通して処理されれば、高性能な推薦エンジンが完成されたと思うかもしれません。しかし残念ながら、そうではありません。
Word2vecとCNNは一度に1つの語を処理するだけで、個々の語を分析/予測することは可能であっても 、全体的な製品レビューの語調や意味を理解できないのです。
LSTM
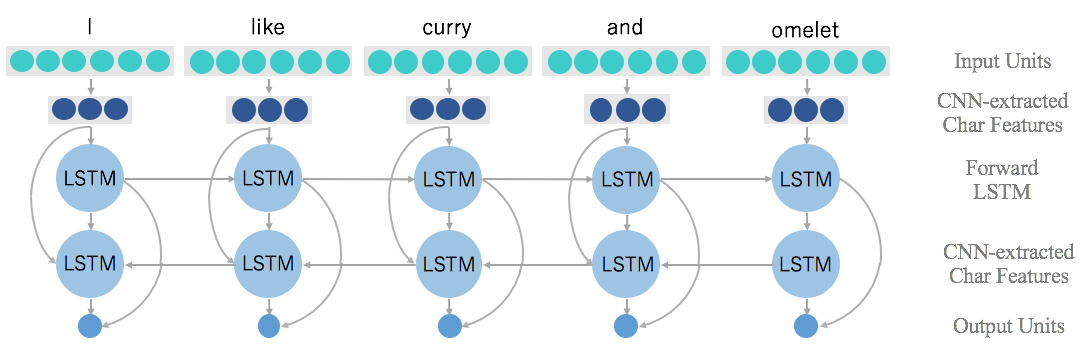
この問題を解決するために、LSTM(Long-Short Term Memory)というもう一つのアルゴリズムが実装されています。最後の2つのプロセスとは異なり、LSTMは語の順序を認識することを得意とし、それにより語の関係性も認識することができます。これはLSTMが次の語に移る前に、入力された語を前もって「覚える」ことができるからです。
これが機能する理由は、LSTMがrecurrent neutral network(RNN)の形態であるからです。RNNには過去の情報を連続的に伝えるループを持っているので、過去の入力を保存することができます。またこのループは、RNNネットワーク内の情報を伝達させることを可能にします。RNNの中に、LSTMは語の関係性を認識し長期間記憶することを得意とします。これは鎖のような構造をしており、“cell state”というベルトコンベアのような横断的な線が、情報をどんどん次の鎖に伝えていきます。
各々の鎖(cellとも呼ばれる)は、cell stateの内容を変えることができる”gate”を持ちます。このgateは、互いに異なる機能を持つ複数の層を保持することができます。たとえば、gate層の入力値はcell stateのどのような情報を更新するか決めることができ、tanh層はcall stateに加えることができる新しい候補値ベクトルを作成します。一旦全てのword2vec、CNN、LSTMの処理が終わると、全テキストデータを代表する一つのベクトルが出力されます。
まとめ
Datumixはそれぞれの会社の製品と顧客ごとに、すでに構築された変幻自在な訓練法を駆使し、最適化された推薦エンジンを作ることができます。また、私たちは各社の嗜好によって推薦エンジンを簡単に変えられるインターフェースを持つAI製品を開発していて、これは全てのeコマースの会社で運用可能です。そのため、これまでのお客様から高い評価を受けています。私たちはこれからも新しいインターフェースでお客様を満足させていくことを楽しみにしています。