Prophetとは
ProphetはFaceBookが開発した時系列予測のパッケージです。
下記のslide shareがとても分かりやすいので、最初に目を通すことをお勧めします。
本記事はProphetの公式ドキュメントを中心に、Prophetの使い方を自分なりにまとめたものとなります。
使用するライブラリのインストール
環境はGoogle Colaboratoryです。
!pip install fbprophet
import pandas as pd
from fbprophet import Prophet
from fbprophet import plot
from fbprophet.diagnostics import cross_validation, performance_metrics
データセットの準備
今回は公式のチュートリアルでも使用されているペイトンマニング(アメフト選手)のWikipediaのアクセス数のデータを使用します。なお、Prophetでモデリングをする際に使用するデータセットは下記の2つのカラムが必須となります。
- ds:日付データ
- y:予測したいデータ
df = pd.read_csv('http://logopt.com/data/peyton_manning.csv')
基本的な使い方
学習 → 予測 → 可視化の一連の流れは下記のコードで簡単に実装できます。
学習
sklearnと同じ、インスタンス作成 → fitの流れです。
m = Prophet()
m.fit(df)
予測
まずは予測用のDataFrameをmake_future_dataframeで指定の期間分作成します。期間は引数periodで指定することができます。DataFrame完成後はpredictメソッドで予測を行います。
# 予測値を格納するためのDataFrameを作成し、予測
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
forecast.head(3)

可視化
予実プロット
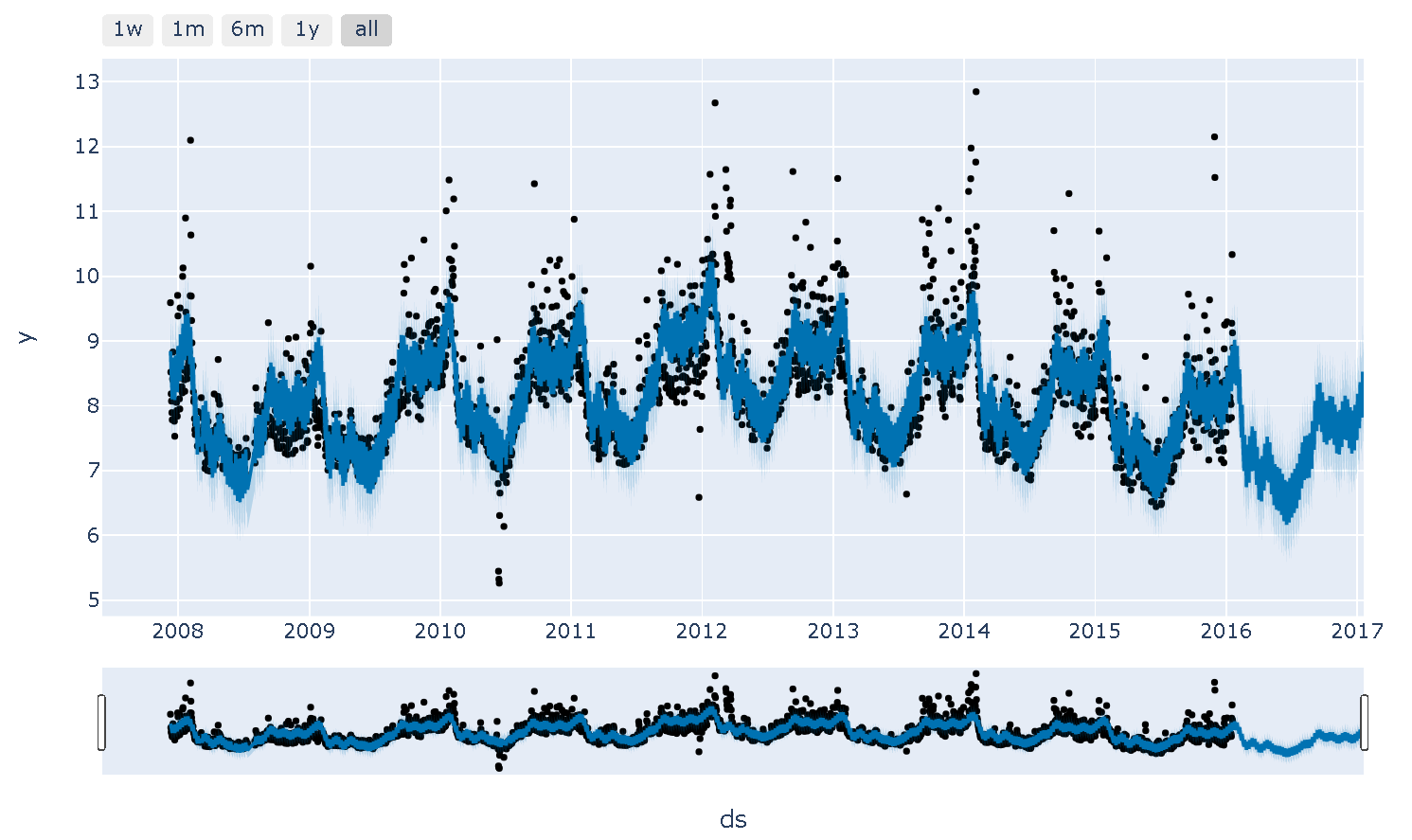
実際の値と予測値をプロットする際はplot.plot_plotlyを使用します。黒丸が実際の値、濃い青が予測値、薄い青が予測幅です。plotlyを使用しているため、動的にアウトプットの拡大縮小も可能です。
plot.plot_plotly(m, forecast)
要素別の予測値プロット
Prophetのモデル式は下記の通りで、トレンド($g_t$)、季節($s_t$)、イベント($h_t$)、誤差($\epsilon_t $)で構成されています。
$$
y_t =g_t + s_t + h_t + \epsilon_t
$$
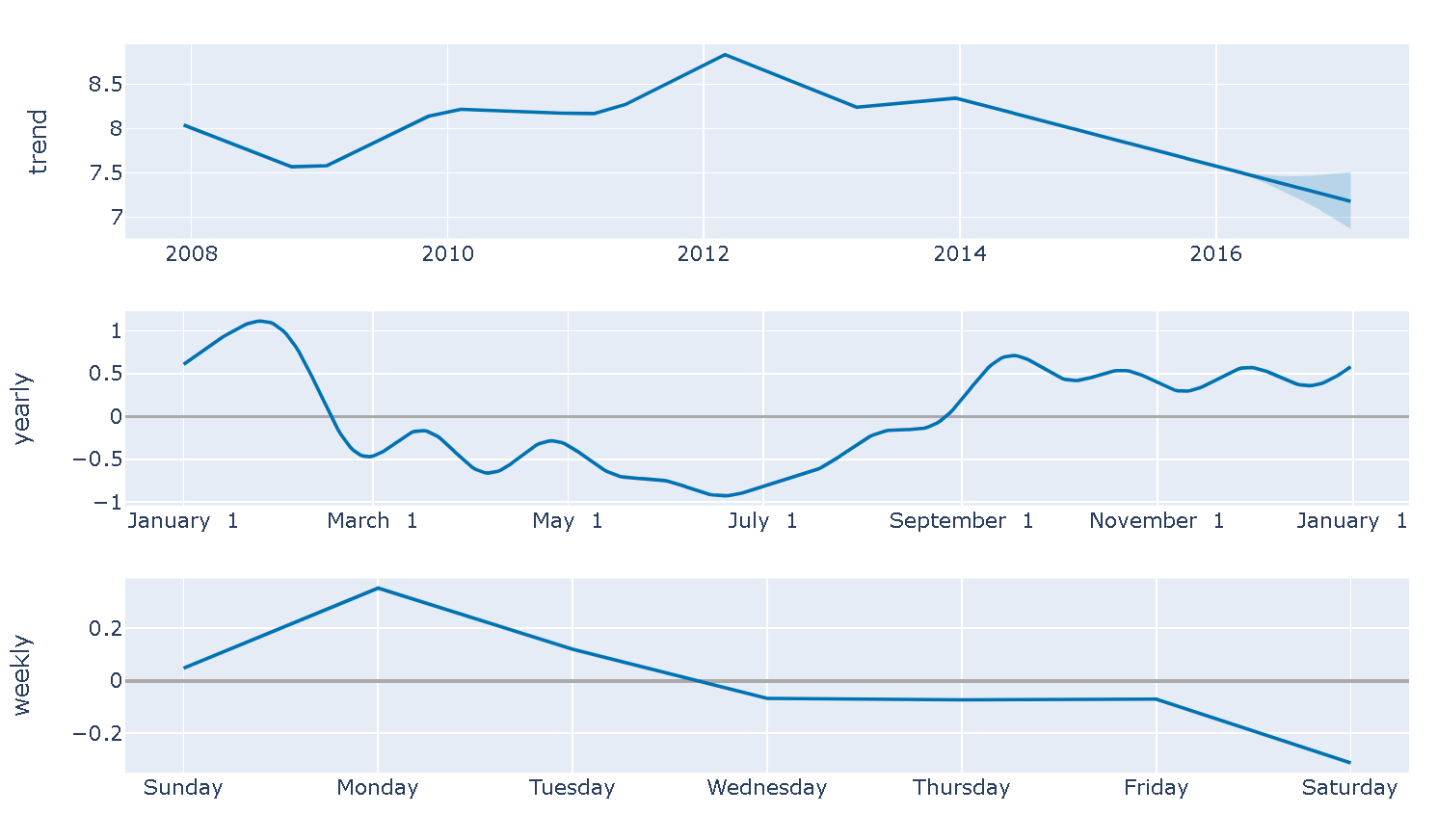
plot.plot_components_plotlyを使用することで、予測値を各要素に分解してプロットすることができます。デフォルトでプロットされるのはトレンド要素と季節要素(年次、週次)ですが、イベント要素もプロット可能です。
plot.plot_components_plotly(m, forecast)
モデルのカスタマイズ
ここからはデフォルトから色々と値を変えてモデルをカスタマイズする方法について記載していきます。
- トレンド項を非線形トレンドへの変更
- トレンド変化点の変更
- 要素の追加
- 季節変動を乗法的モデルへ変更
トレンド項を非線形トレンドへの変更
トレンド項はデフォルトでは線形になっていますが、非線形にも変更できます。非線形にする場合は予測上限(cap)を指定するカラムが必須となります。なお予測下限(floor)を指定するカラムを用意すれば、予測下限も指定可能です。
# dfに予測の上限値(cap)、下限値(floor)カラムを予め追加
df["cap"] = 10
df["floor"] = 0
# 引数growthをlogisticに変更
m = Prophet(growth='logistic')
m.fit(df)
# 予測用データフレームにも上限値(cap)、下限値(floor)カラムが必要
future = m.make_future_dataframe(periods=365)
future["cap"] = 10
future["floor"] = 0
forecast = m.predict(future)
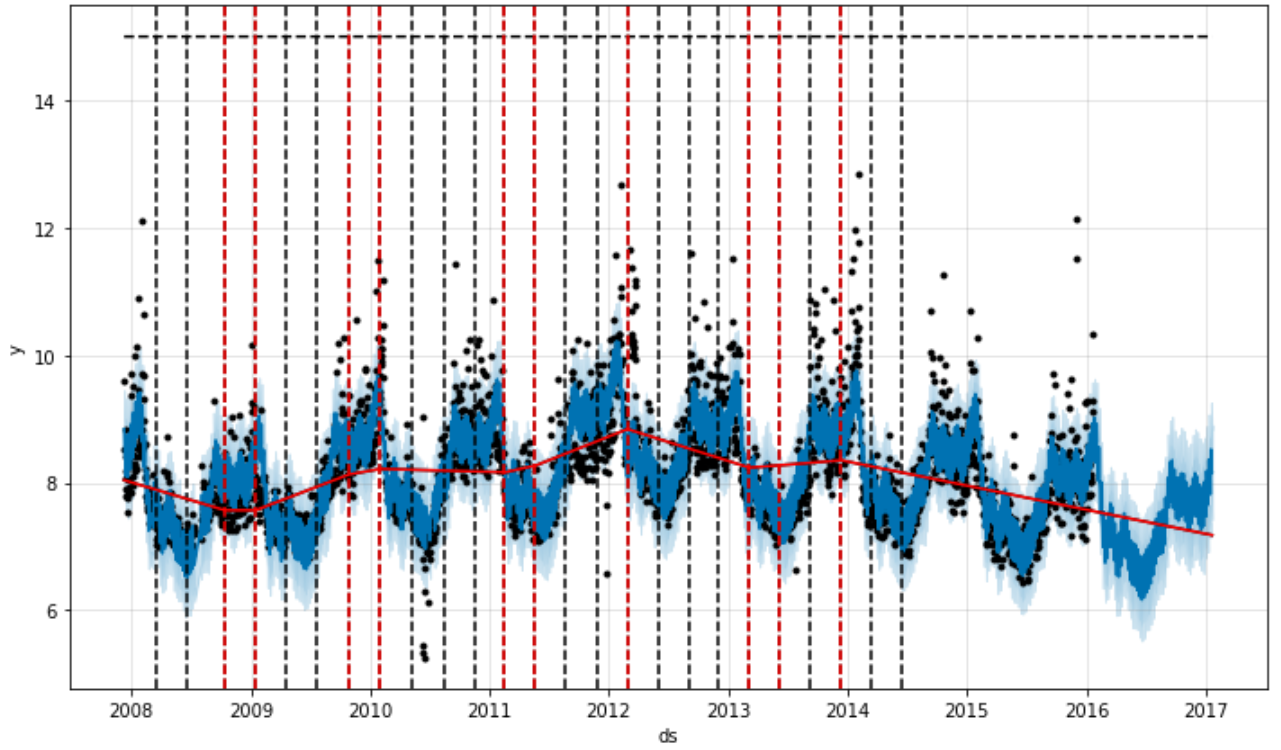
トレンド変化点
Prophetではモデル作成時にトレンドの変化点の検知が行われます。デフォルトでは、データの前半80%を使用して25個のトレンド変化点候補を均等に配置し、変化量が一定量以上の点を変化点として扱います。80%、25個、という数値はそれぞれchangepoint_range 、n_changepointsで変更可能です。
m = Prophet(changepoint_range=0.8, n_changepoints=25) # ここの値を変更
m.fit(df)
# 予測値を格納するためのDataFrameを作成
future = m.make_future_dataframe(periods=365)
# 予測
forecast = m.predict(future)
# 変化点の可視化
# 変化点として採用されたが赤、変化量が微量のため不採用なのが黒
fig = m.plot(forecast)
# 不採用となった候補点のplotが不要な場合は1つ目をコメントアウト
a = add_changepoints_to_plot(fig.gca(), m, forecast, threshold=0, cp_color="black")
a = add_changepoints_to_plot(fig.gca(), m, forecast)
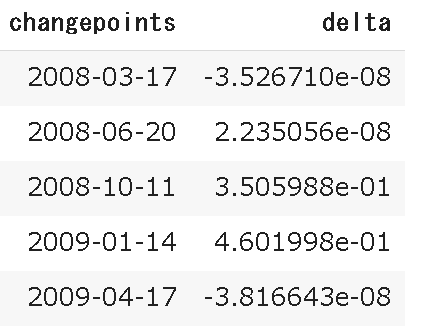
設定されたchangepointと変化量は下記のコードで確認可能です。
changepoints_delta = pd.DataFrame(
{
"changepoints":m.changepoints,
"delta":m.params["delta"][0]
}
)
changepoints_delta.head()
要素の追加
デフォルトの要素以外に、下記の要素をモデルに取り入れることができます。
- 季節変動
- 年次、週次以外の季節変動(月次など)
- 他の要素に依存する季節変動(シーズンオフ、シーズン中など)
- 予測因子(特別な日、天気、気温など)
- イベント(休日、プレーオフ、クリスマスなど)
要素の追加方法
他の要素に依存する季節変動 / 予測因子 の追加準備
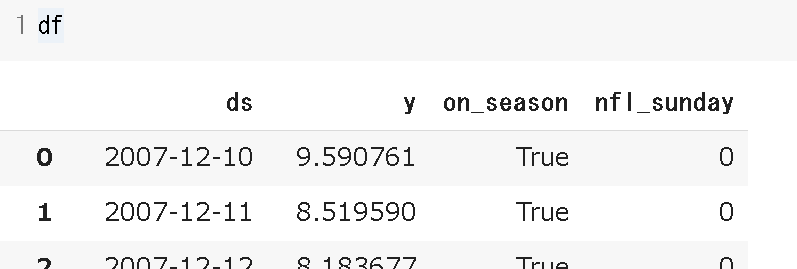
シーズンオフ、シーズン中といった他の要素に依存する季節変動と予測因子を追加する際は、元のDataFrameにカラムを追加します。他の要素に依存する季節変動はbool型、因子は数値型である必要があります。下記は先ほどのペイトンマニングのデータに対して、on_season(シーズン中かどうか)、nfl_sunday(試合が開催される日曜日フラグ)を追加した例となります。
コード
def is_nfl_season(ds):
date = pd.to_datetime(ds)
return (date.month > 8 or date.month < 2)
def nfl_sunday(ds):
date = pd.to_datetime(ds)
if date.weekday() == 6 and (date.month > 8 or date.month < 2):
return 1
else:
return 0
df['on_season'] = df['ds'].apply(is_nfl_season)
df['nfl_sunday'] = df['ds'].apply(nfl_sunday)
イベント(休日、プレーオフ、クリスマスなど)の追加準備
イベント要素を追加するためには別途下記の要素で構成されるDataFrameを用意する必要があります。なお、祝日に関してはadd_country_holidaysというメソッドが用意されているので、自分で作る必要はありません(ただし日本のやつは若干ずれてるという情報もあるため使用する際はあっているか確認要)
- ds:日時
- holiday:イベント名
- lower_window:イベントの影響範囲(3なら3日前から影響)
- upper_window:イベントの影響範囲(3なら3日後まで影響)
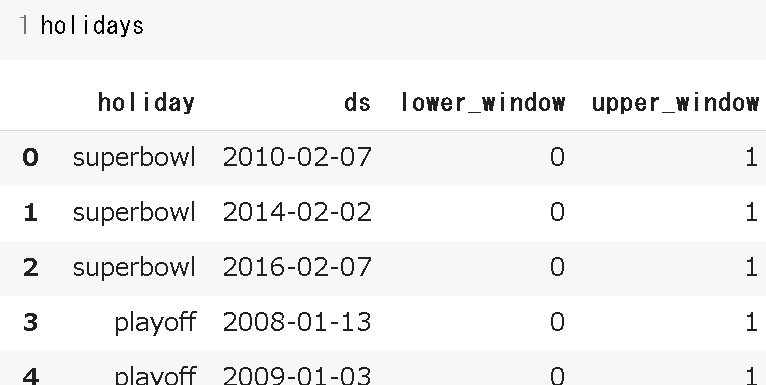
下記はアメフトのスーバーボウルとプレーオフをDataFrameに格納した際の例となります。
コード
superbowls = pd.DataFrame({
'holiday': 'superbowl',
'ds': pd.to_datetime(['2010-02-07', '2014-02-02', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
playoffs = pd.DataFrame({
'holiday': 'playoff',
'ds': pd.to_datetime(['2008-01-13', '2009-01-03', '2010-01-16',
'2010-01-24', '2010-02-07', '2011-01-08',
'2013-01-12', '2014-01-12', '2014-01-19',
'2014-02-02', '2015-01-11', '2016-01-17',
'2016-01-24', '2016-02-07']),
'lower_window': 0,
'upper_window': 1,
})
holidays = pd.concat((superbowls,playoffs)).reset_index(drop=True)
要素を追加した上での学習
準備してきた要素を加えて学習する際のコードは下記の通りとなります。holidays_prior_scale、holidays_prior_scaleで各要素がモデルに与える影響度を調整できます。
# イベントの追加
m = Prophet(holidays=holidays, holidays_prior_scale=0.05)
# 祝日の追加はメソッドが用意されている
m.add_country_holidays(country_name='US') # 日本はJP
# 年次、週次以外の季節変動要素の追加
m.add_seasonality(name='monthly', period=30.5, fourier_order=5)
# 他の要素に依存する季節変動(condition_nameに対応するカラム名)
m.add_seasonality(name='weekly_on_season', period=7, fourier_order=3, condition_name='on_season', prior_scale=0.1)
# 因子の追加
m.add_regressor('nfl_sunday')
m.fit(df)
# 予測値を格納するためのDataFrameを作成
future = m.make_future_dataframe(periods=365)
# 追加したカラムは予測用DataFrameにも必要
future['on_season'] = future['ds'].apply(is_nfl_season)
future['nfl_sunday'] = future['ds'].apply(nfl_sunday)
# 予測
forecast = m.predict(future)
# 指定したイベントの可視化。3つ目の引数にイベント名を入れる
plot.plot_forecast_component(m, forecast, 'playoff')
季節変動を乗法的モデルへ変更
デフォルトでは季節変動は加法的モデルですが、インスタンス化する際に引数seasonality_modeで乗法的モデルを指定します。
# 季節変動を乗法的モデルへ変更
m = Prophet(seasonality_mode='multiplicative')
どちらを使うのがよいか?について、季節パターンの大きさがyの大きさに比例する(yの値が大きければ季節変動の振れ幅も大きくなる)場合は乗法的モデル、それ以外の場合は加法的モデルを使用します。(参考:加法的モデルと乗法的モデル)
検証と誤差の評価
クロスバリデーションの実行
cross_validationというメソッドを使用することクロスバリデーションが可能です。
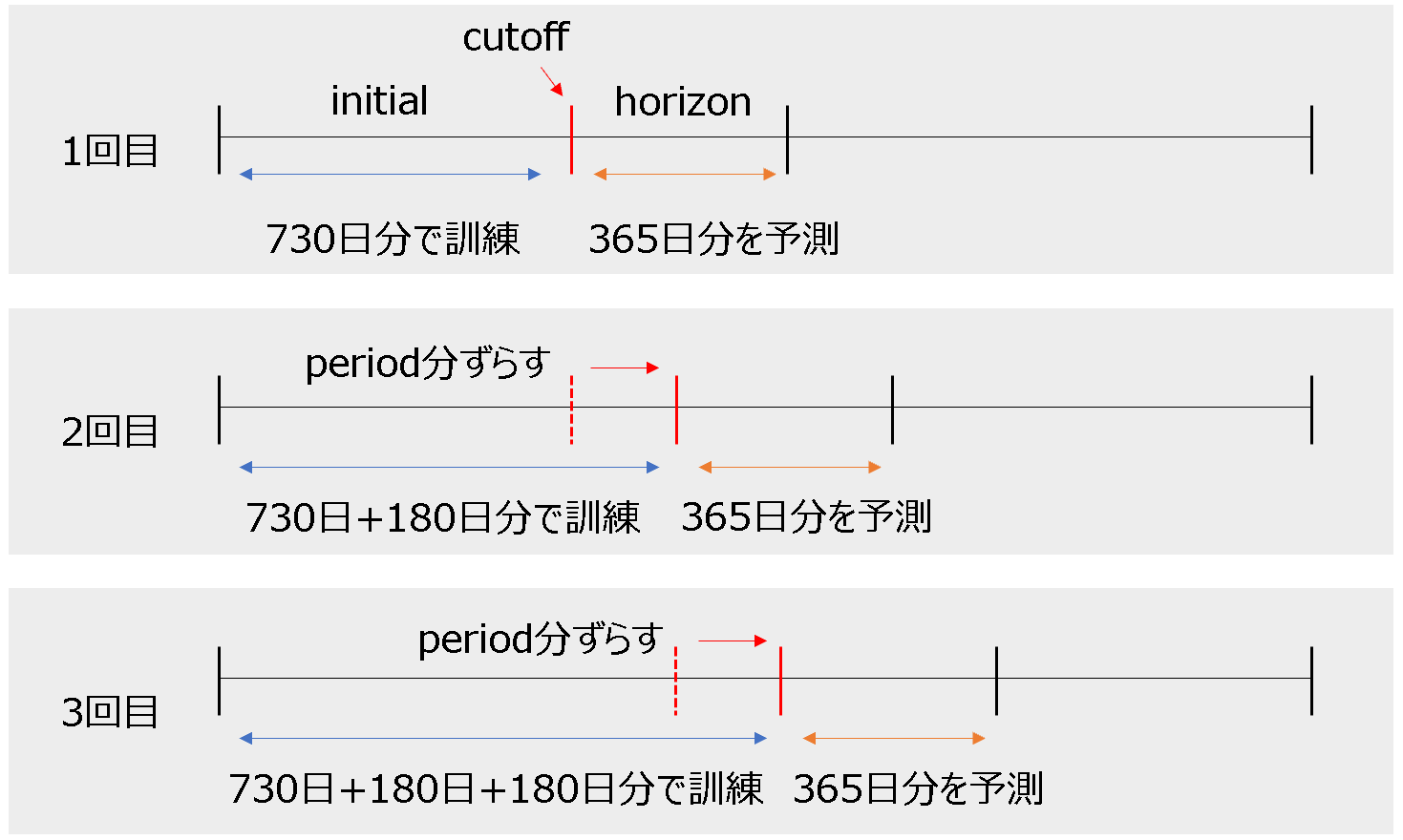
df_cv = cross_validation(m, initial='730 days', period='180 days', horizon = '365 days')
initialは訓練期間の初期値、horizonは予測する期間を表します。そしてperiodで指定した日数分ずつ、学習期間が延ばすことをデータがなくなるまで繰り返します。
結果の確認
クロスバリデーションの結果を格納したdf_cvの中身は下記のようになっています。cutoffは上記のイメージにもありますが、訓練データと予測データの境目となる日付です。yは実際の値、yhatは予測値、yhat_upperは予測上限、yhat_lowerは予測下限です。

評価尺度の計算
performance_metricsメソッドを使用すると各種評価指標を計算できます。horizonは予測期間の何日目かを表しており、デフォルトで前半10%は削除されていますが、こちらはrolling_windowで調整できます。(今回は予測期間が365日分なので37日目から計算が行われている)。
df_p = performance_metrics(df_cv, rolling_window=0.1)
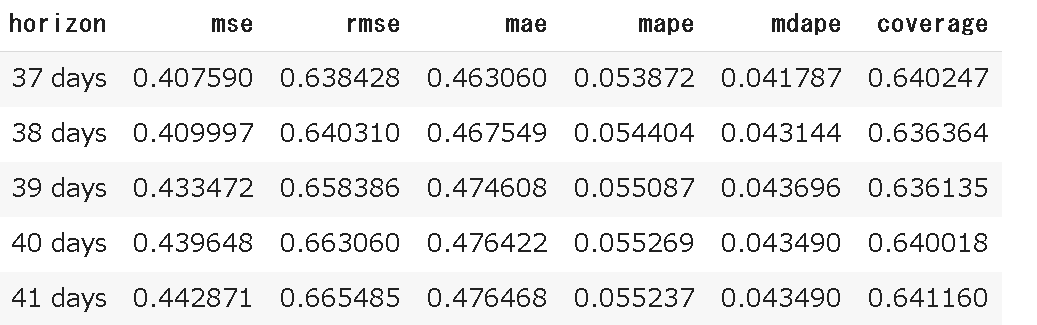
各評価指標の説明は下記の通りです
- MSE(mean squared error:平均平方誤差)
- RMSE(root mean squared error: 平均平方誤差の平方根)
- MAE(mean absolute error: 平均絶対誤差)
- MAPE(mean absolute percent error : 平均絶対パーセント誤差)
- coverage(被覆率 : yhat_lower とyhat_upper の間に入っている割合)
評価指標の可視化
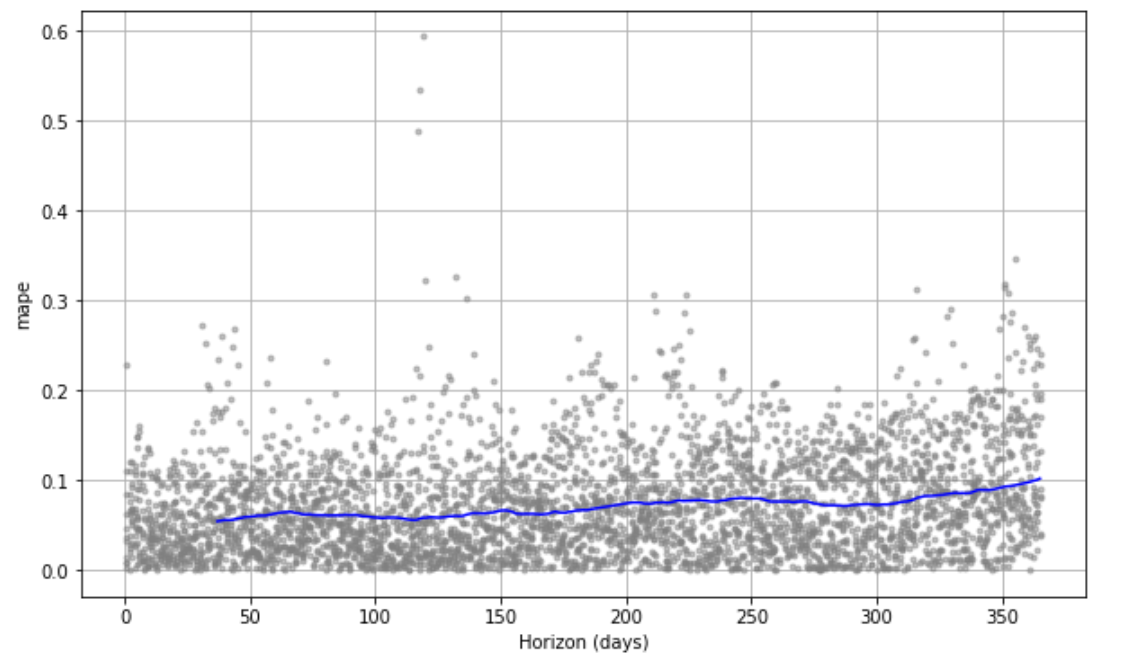
plot_cross_validation_metricを使用すると評価指標を可視化することができます。可視化したい指標をmetricで指定しましょう。
fig = plot.plot_cross_validation_metric(df_cv, metric='mape')
参考
Prophetによる時系列データの予測
Facebookの予測ライブラリProphetを用いたトレンド抽出と変化点検知
Prophetのモデル式を1から理解する