はじめに
Webサービスのパフォーマンス調査や、Webサービス利用に必要なネットワーク帯域幅の見積もりをする際に、Webサーバーのアクセスログを解析する事があります。
解析したい情報は、以下のようなものになります。
- 1日あたりのリクエスト数
- サーバー処理時間が閾値(3秒など)以上かかったリクエスト数と比率
- 1秒あたりの最大同時リクエスト数
- 1リクエストあたりの平均転送量
以前は、Excel、Log Parser Studioなどで解析していましたが、ログファイルの数が多かったりすると解析が面倒だったため、スクリプトで必要情報を解析する事にしました。
スクリプトを書こうと思ったとは言え、10年以上まともなコードを書いていない状況でした。
しかし、最近弊社内のクローズドな環境で機密情報を損なう事なく利用できる生成AI(OpenAIベース)が使えるようになったため、生成AIにお願いしながらスクリプトを書いてみました。
生成AIにどのようにお願いしたか、この記事では触れませんが、コードを書くための要件や制約条件、Input/Output情報、サンプルデータといった、開発に必要な情報をインプットできれば(それなりの開発経験は必要)、それらしいコードをすぐに提案してくれます。
ただし、そのままでは動かなかったり、意図と違う動作をするので、実際に動かして検証しつつ、微調整をしていきます。
今回作成したスクリプトは、検証含め8時間程度で作成する事ができました。
前提条件
今回解析するWebサーバー(Apache)のアクセスログのログフォーマットは以下の通りです。
LogFormat "\"%A\",\"%h\",\"%{%Y/%m/%d}t\",\"%{%H:%M:%S}t\",\"%r\",\"%>s\",\"%b\",\"%T\",\"%{JSESSIONID}C\""
%bで「送信されたバイト数」、%Tで「処理にかかった時間(秒)≒サーバー処理時間」を確認する事ができます。
アクセスログのヘッダー名は、以下のように定義しました(アクセスログにヘッダー行を追加する必要はありません)。
"host_ip_address", "remote_hostname", "date", "time", "method_uri", "http_status", "transfer(bytes)", "res_time", "JSESSIONID"
また、サンプルデータは以下になります。
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:28","GET /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","4752","0","0000YiL4D_Y5ZFeSIUIQIj2kYcp:1cb90kuiq"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:29","GET /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","4995","0","0000ySQktriUe_DZ550akj-VqOT:1cb90kvlf"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:30","GET /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","4973","0","0000uI7u3PYjXncv8ZlZ5cFZpbK:1cb90kvb7"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:31","GET /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","6145","0","0000ySQktriUe_DZ550akj-VqOT:1cb90kvlf"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:33","POST /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","6145","0","0000ySQktriUe_DZ550akj-VqOT:1cb90kvlf"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:33","POST /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","6145","0","0000ySQktriUe_DZ550akj-VqOT:1cb90kvlf"
"XX.X.XX.XX","YY.YYY.YYY.YY","2024/02/01","07:12:33","GET /xxxxxxx/xxx?xxxx=xxxx&xxxx=xxxx HTTP/1.1","200","6145","0","0000ySQktriUe_DZ550akj-VqOT:1cb90kvlf"
事前準備
アクセスログに、アイコン、画像ファイル、CSS、jsといった静的コンテンツへのリクエストが含まれている場合は、grepなどして該当行を削除しておきます。
サクラエディタで該当行を置換する場合は、「検索」→「Grep置換」を選択後、以下を指定して「置換」します。
置換前: ^.*\.(gif|jpeg|jpg|png|css|js|ico).*\r\n
置換後: (空白)
検索場所:ログファイルが保管されているディレクトリを指定
対象ファイル: *.log
※「正規表現」、「サブフォルダーも検索」にチェックを入れてください
アクセスログ解析スクリプトの説明
今回4つのスクリプトを作成しましたが、全て以下のような動作をします。
- configディレクトリ以下に配置したCSVファイルを読み込んで実行します(CSVファイルの場所はスクリプト内で指定しているので、必要に応じてスクリプトを修正してください)
- CSVファイルには、アクセスログが保管されているディレクトリパスと、解析結果を出力するCSVファイルのファイルパスを指定します
- ログディレクトリの指定では、最後に必ず「/」を付ける必要があります
- ログと解析結果の組み合わせは複数指定可能で、ログディレクトリは、子階層についてもログファイルを参照しにいきます
- パスにマルチバイト文字が含まれていると動作しません(いけてなくてすみません)
- アクセスログファイル名は、「access_YYYYMMDD.log」(例:access_20240328.log)という前提です(必要に応じてスクリプトを修正してください)
- 各スクリプトは、Python 3.12.2で動作確認しています。また、pipでpandasを別途インストールする必要があります
configディレクトリ以下のCSVファイルの例(スクリプト毎に4つのCSVファイルを作成します)
Log Directory,Output File
C:/performance/SystemA/accesslog/,C:/performance/SystemA/performance_check_sysA.csv
C:/performance/SystemB/accesslog/,C:/performance/SystemB/performance_check_sysB.csv
C:/performance/SystemC/accesslog/,C:/performance/SystemC/performance_check_sysC.csv
各スクリプトの概要とコード
■avg_transfer_per_request.py
- configディレクトリ以下の「avg_transfer_per_request_config.csv」を読み込み、ログを解析します
- アクセスログを解析し、日毎の1リクエストあたりの平均転送量をByte、KByte単位でCSVファイルに出力します
avg_transfer_per_request.py
import os
import glob
import pandas as pd
# log_directory_output_filesを指定するCSVファイルパスを変更してください
config_file = "C:/performance/scripts/config/avg_transfer_per_request_config.csv"
# アクセスログフォーマットの列名
columns = ["host_ip_address", "remote_hostname", "date", "time", "method_uri",
"http_status", "transfer(bytes)", "res_time", "JSESSIONID"]
# 解析結果を格納するDataFrameを作成
data = []
# config_fileから組み合わせを取得
log_directory_output_files = pd.read_csv(config_file)
# 各組み合わせごとに解析を実行
for _, row in log_directory_output_files.iterrows():
log_directory = row["Log Directory"]
output_file = row["Output File"]
print(log_directory)
# ディレクトリ内のアクセスログファイルを取得
log_files = glob.glob(os.path.join(log_directory, "**", "access_*.log"), recursive=True)
# 各ログファイルを処理
for log_file in log_files:
# ログファイル名から日付を抽出
date_str = os.path.basename(log_file).split(".")[0].split("_")[-1]
print(date_str)
# アクセスログデータを読み込み
df = pd.read_csv(log_file, names=columns, header=None)
# "-"の値をNaNに変換
df["transfer(bytes)"] = pd.to_numeric(df["transfer(bytes)"], errors="coerce")
# 1リクエストあたりの平均転送量を算出
avg_transfer_per_request = df["transfer(bytes)"].mean()
# NaNの場合は平均算出対象外とする
if pd.notnull(avg_transfer_per_request):
avg_transfer_per_request_kb = avg_transfer_per_request / 1024 # 単位をKBに変換
# 解析結果をリストに追加
data.append([log_directory, output_file, date_str, avg_transfer_per_request, avg_transfer_per_request_kb])
# 解析結果をDataFrameに変換
result_df = pd.DataFrame(data, columns=["Log Directory", "Output File", "Date", "Avg Transfer per Request (Bytes)", "Avg Transfer per Request (KB)"])
# 日付を基準に昇順ソート
result_df = result_df.sort_values("Date", ascending=True)
# 解析結果を各出力ファイルに出力
output_files = result_df["Output File"].unique()
for output_file in output_files:
print(output_file)
filtered_df = result_df[result_df["Output File"] == output_file]
filtered_df.to_csv(output_file, index=False)
■max_requests_per_second_per_day.py
- configディレクトリ以下の「max_requests_per_second_per_day_config.csv」を読み込み、ログを解析します
- アクセスログを解析し、日毎に以下の情報をCSVファイルに出力します
- 秒間最大同時リクエスト数
- 秒間最大同時リクエストがあった日時
- 10分間での最大リクエスト数
- 10分間での最大リクエストがあった時間帯
max_requests_per_second_per_day.py
import os
import glob
import pandas as pd
# log_directory_output_filesを指定するCSVファイルパスを変更してください
config_file = "C:/performance/scripts/config/max_requests_per_second_per_day_config.csv"
# アクセスログフォーマットの列名
columns = ["host_ip_address", "remote_hostname", "date", "time", "method_uri",
"http_status", "transfer(bytes)", "res_time", "JSESSIONID"]
# 解析結果を格納するDataFrameを作成
data = []
# config_fileから組み合わせを取得
log_directory_output_files = pd.read_csv(config_file)
# 各組み合わせごとに解析を実行
for _, row in log_directory_output_files.iterrows():
log_directory = row["Log Directory"]
output_file = row["Output File"]
print(log_directory)
# ディレクトリ内のアクセスログファイルを取得
log_files = glob.glob(os.path.join(log_directory, "**", "access_*.log"), recursive=True)
# 各ログファイルを処理
for log_file in log_files:
# ログファイル名から日付を抽出
date_str = os.path.basename(log_file).split(".")[0].split("_")[-1]
print(date_str)
# アクセスログデータを読み込み
df = pd.read_csv(log_file, names=columns, header=None)
# GETリクエストのみをフィルタリング
# df = df[df["method_uri"].str.startswith("GET")]
# 日時列を結合してDateTime型に変換
df["datetime"] = pd.to_datetime(df["date"] + " " + df["time"])
# 毎秒のリクエスト数を集計
requests_per_sec = df.groupby(pd.Grouper(key="datetime", freq="s")).size()
# 1秒あたりの最大同時リクエスト数を算出
max_requests_per_sec = requests_per_sec.max()
if max_requests_per_sec >= 1:
max_request_time = requests_per_sec.idxmax()
else:
max_requests_per_sec = 0
max_request_time = "nan"
# 10分毎のリクエスト数を集計
requests_per_10min = df.groupby(pd.Grouper(key="datetime", freq="10Min")).size()
# 10分間で最も多かったリクエスト数を取得
max_requests_per_10min = requests_per_10min.max()
if max_requests_per_10min >= 1:
# 最も多かったリクエスト数の時間帯を取得
max_count_time = requests_per_10min.idxmax().strftime("%Y/%m/%d %H:%M:%S")
else:
max_requests_per_10min = 0
max_count_time = "nan"
# 解析結果をリストに追加
data.append([log_directory, output_file, date_str, max_requests_per_sec, max_request_time, max_requests_per_10min, max_count_time])
# 解析結果をDataFrameに変換
result_df = pd.DataFrame(data, columns=["Log Directory", "Output File", "Date", "Max Requests per Second", "Max Request Time(sec)", "Max Requests per 10min", "Max Request Time(10min)"])
# 日付を基準に昇順ソート
result_df = result_df.sort_values("Date", ascending=True)
# 解析結果をCSVファイルに出力
output_files = result_df["Output File"].unique()
for output_file in output_files:
print(output_file)
filtered_df = result_df[result_df["Output File"] == output_file]
filtered_df.to_csv(output_file, index=False)
■performance_check.py
- configディレクトリ以下の「performance_check_config.csv」を読み込み、ログを解析します
- アクセスログを解析し、日毎に以下の情報をCSVファイルに出力します
- 1日あたりのリクエスト数
- サーバー処理時間が3秒以上のリクエスト数
- サーバー処理時間が3秒以上のリクエストの平均値
- サーバー処理時間が3秒以上のリクエストの最大値
- サーバー処理時間が3秒以上のリクエストが多かった時間帯(10分間)
- 1日あたりのリクエストの内、サーバー処理時間が3秒以上だったリクエストの割合(%)
performance_check.py
import os
import glob
import pandas as pd
# log_directory_output_filesを指定するCSVファイルパスを変更してください
config_file = "C:/performance/scripts/config/performance_check_config.csv"
# アクセスログフォーマットの列名
columns = ["host_ip_address", "remote_hostname", "date", "time", "method_uri",
"http_status", "transfer(bytes)", "res_time", "JSESSIONID"]
# 解析結果を格納するDataFrameを作成
data = []
# config_fileから組み合わせを取得
log_directory_output_files = pd.read_csv(config_file)
# 各組み合わせごとに解析を実行
for _, row in log_directory_output_files.iterrows():
log_directory = row["Log Directory"]
output_file = row["Output File"]
print(log_directory)
# ディレクトリ内のアクセスログファイルを取得
log_files = glob.glob(os.path.join(log_directory, "**", "access_*.log"), recursive=True)
# グローバルなフィルタリング結果を格納するDataFrame
filtered_df_concat = pd.DataFrame(columns=["host_ip_address", "remote_hostname", "date", "time", "method_uri",
"http_status", "transfer(bytes)", "res_time", "JSESSIONID"])
# 各ログファイルを処理
for log_file in log_files:
# ログファイル名から日付を抽出
date_str = os.path.basename(log_file).split(".")[0].split("_")[-1]
print(date_str)
# アクセスログデータを読み込み
df = pd.read_csv(log_file, names=columns, header=None)
# "-"をNaNに変換
df["res_time"] = pd.to_numeric(df["res_time"], errors="coerce")
# "res_time"の値が3以上のリクエストのみをフィルタリング
filtered_df = df[df["res_time"] >= 3]
# 各ログファイルのフィルタリング結果を格納
filtered_df_concat = pd.concat([filtered_df_concat, filtered_df])
# 1日あたりのリクエスト数
total_requests = len(df)
# "res_time"が3以上のリクエスト数
filtered_requests = len(filtered_df)
# "res_time"が3以上のリクエストの平均値
filtered_mean = filtered_df["res_time"].mean()
# "res_time"が3以上のリクエストの最大値
filtered_max = filtered_df["res_time"].max()
# 日時列を明示的に設定
filtered_df_concat["time"] = pd.to_datetime(filtered_df_concat["time"])
# "res_time"が3以上のリクエストが最も多かった時間帯(10分単位)
filtered_df["time"] = pd.to_datetime(filtered_df["time"])
if filtered_df.size >= 1:
filtered_df["time"] = filtered_df["time"].dt.floor("10min")
time_counts = filtered_df.groupby("time").size()
max_count_time = time_counts.idxmax().strftime("%H:%M:%S")
else:
max_count_time = "-"
# "res_time"が3以上のリクエストの割合(%)を求める
filtered_ratio = (filtered_requests / total_requests) * 100
# 解析結果をリストに追加
data.append([log_directory, output_file, date_str, total_requests, filtered_requests,
filtered_mean, filtered_max, max_count_time, filtered_ratio])
# 解析結果をDataFrameに変換
result_df = pd.DataFrame(data, columns=["Log Directory", "Output File", "Date", "Total Requests",
"Slow Requests(>=3sec)","Slow Request Mean", "Slow Request Max",
"Max Count Time of Slow Requests(10 min interval)", "Slow Requests Retio(%)"])
# 日付を基準に昇順ソート
result_df = result_df.sort_values("Date", ascending=True)
# 解析結果を各出力ファイルに出力
output_files = result_df["Output File"].unique()
for output_file in output_files:
print(output_file)
filtered_df = result_df[result_df["Output File"] == output_file]
filtered_df.to_csv(output_file, index=False)
■http_status_check.py
- configディレクトリ以下の「http_status_check_config.csv」を読み込み、ログを解析します
- アクセスログを解析し、日毎、HTTPステータス毎のリクエスト数をCSVファイルに出力します
http_status_check.py
import os
import glob
import pandas as pd
# log_directory_output_filesを指定するCSVファイルパスを変更してください
config_file = "C:/performance/scripts/config/http_status_check_config.csv"
# アクセスログフォーマットの列名
columns = ["host_ip_address", "remote_hostname", "date", "time", "method_uri",
"http_status", "transfer(bytes)", "res_time", "JSESSIONID"]
# 解析結果を格納するDataFrameを作成
data = []
# config_fileから組み合わせを取得
log_directory_output_files = pd.read_csv(config_file)
# 各組み合わせごとに解析を実行
for _, row in log_directory_output_files.iterrows():
log_directory = row["Log Directory"]
output_file = row["Output File"]
print(log_directory)
# ディレクトリ内のアクセスログファイルを取得
log_files = glob.glob(os.path.join(log_directory, "**", "access_*.log"), recursive=True)
# 各ログファイルを処理
for log_file in log_files:
# ログファイルのパスから日付を取得
date_str = os.path.basename(log_file).split(".")[0].split("_")[-1]
print(date_str)
date = pd.to_datetime(date_str).strftime("%Y%m%d")
# アクセスログデータを読み込み
df = pd.read_csv(log_file, names=columns, header=None)
# "-"をNaNに変換
df["http_status"] = pd.to_numeric(df["http_status"], errors="coerce")
# 200以外のHTTPステータスのみをフィルタリング
filtered_df = df[df["http_status"] != 200]
# HTTPステータスごとにリクエスト数を集計
status_counts = filtered_df["http_status"].value_counts()
# 解析結果をリストに追加
for status, count in status_counts.items():
data.append([log_directory, output_file, date, status, count])
# 解析結果をDataFrameに変換
result_df = pd.DataFrame(data, columns=["Log Directory", "Output File", "Date", "HTTP STATUS", "COUNT"])
# 日付を基準に昇順ソート
result_df = result_df.sort_values("Date", ascending=True)
# 解析結果をCSVファイルに出力
output_files = result_df["Output File"].unique()
for output_file in output_files:
print(output_file)
filtered_df = result_df[result_df["Output File"] == output_file]
filtered_df.to_csv(output_file, index=False)
各スクリプトの実行結果サンプル
上記スクリプトを実行すると、以下のような解析結果がCSV形式で出力されます。
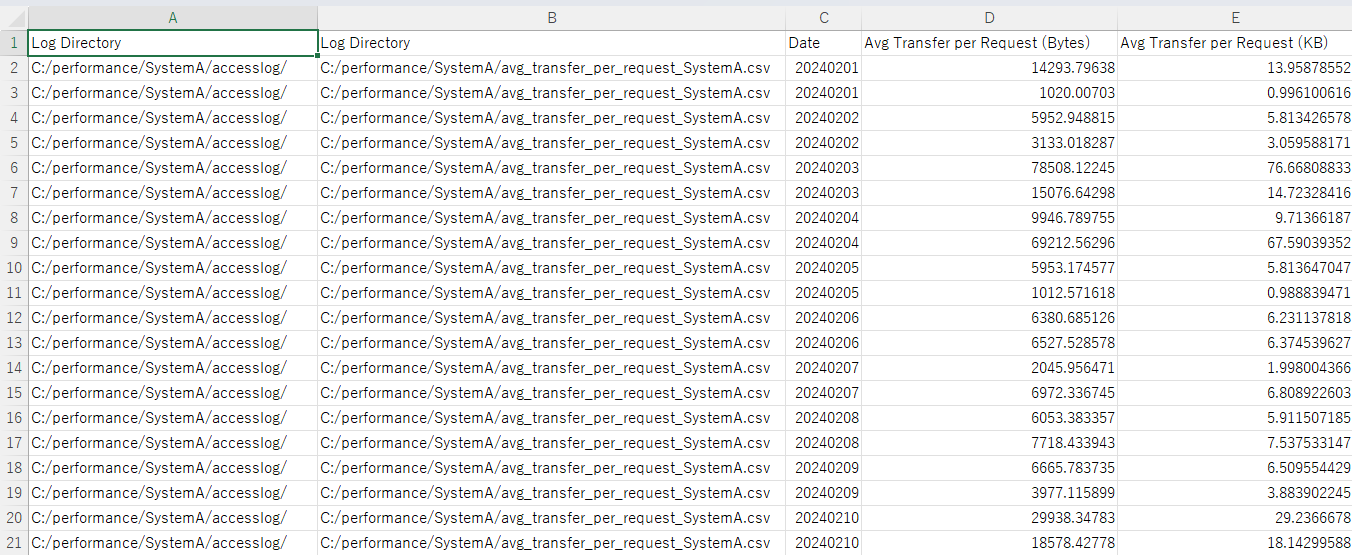
■avg_transfer_per_request.py
> python avg_transfer_per_request.py
実行結果例(CSVファイルをExcelで開いた結果)
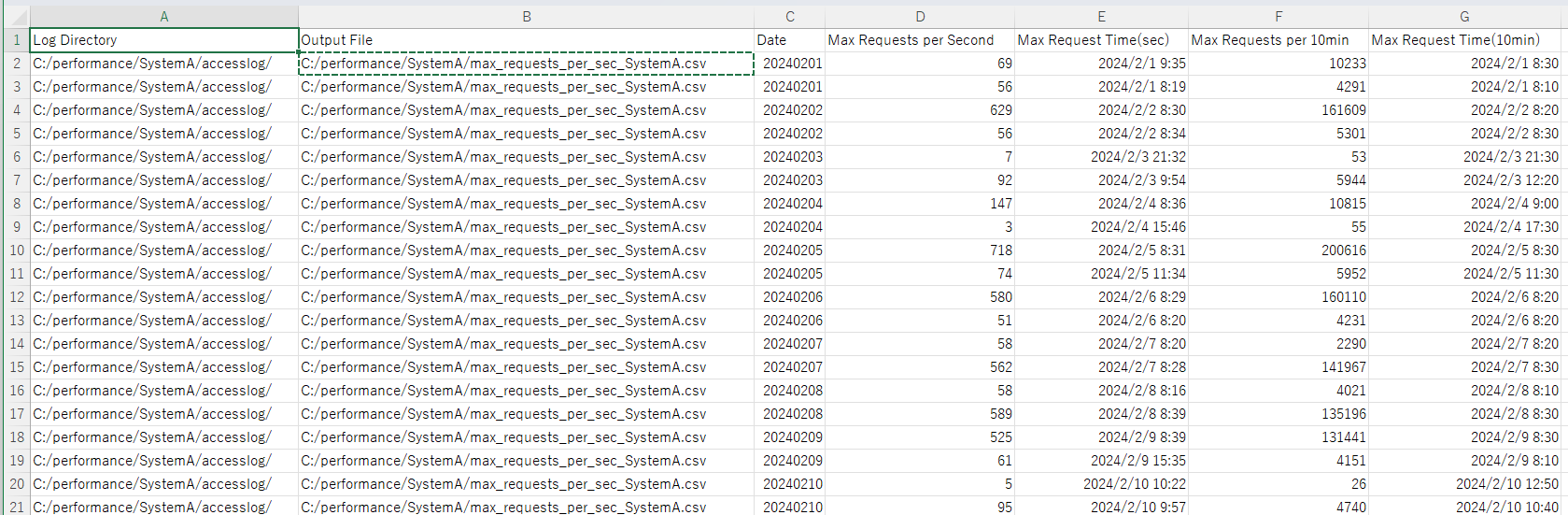
■max_requests_per_second_per_day.py
> python max_requests_per_second_per_day.py
実行結果例(CSVファイルをExcelで開いた結果)
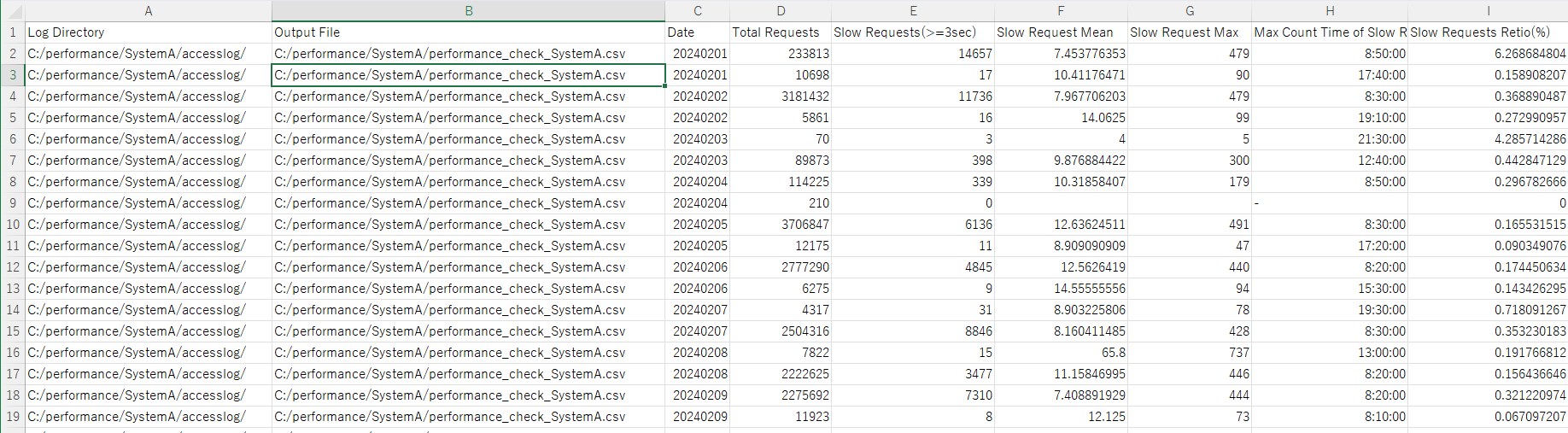
■performance_check.py
> python performance_check.py
実行結果例(CSVファイルをExcelで開いた結果)
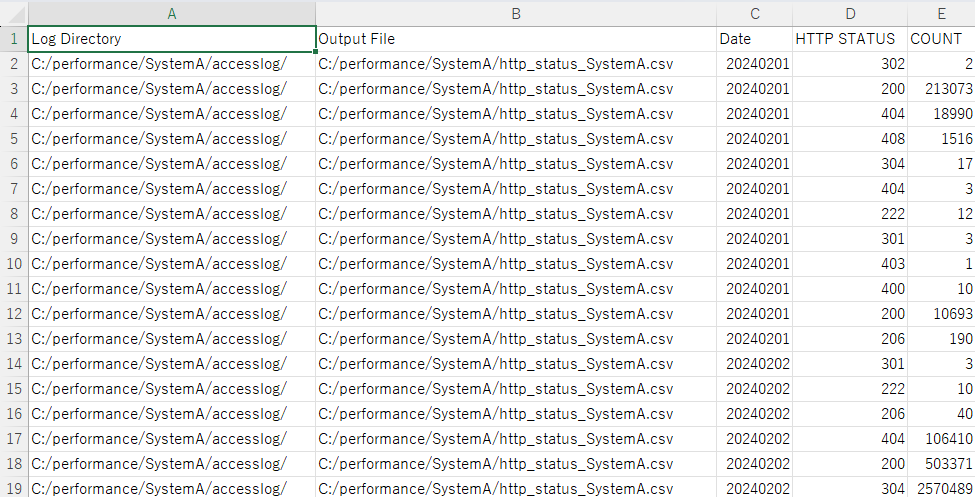
■http_status_check.py
> python http_status_check.py
実行結果例(CSVファイルをExcelで開いた結果)
アクセスログ解析結果の活用
「max_requests_per_second_per_day.py」、「performance_check.py」の実行結果をまとめると、以下のようにお客様本番環境のパフォーマンス状況を確認する事ができます。
この情報を基に、アプリケーションやMWなどのチューニングや、サーバーサイジング用の情報として活用する事も可能です。
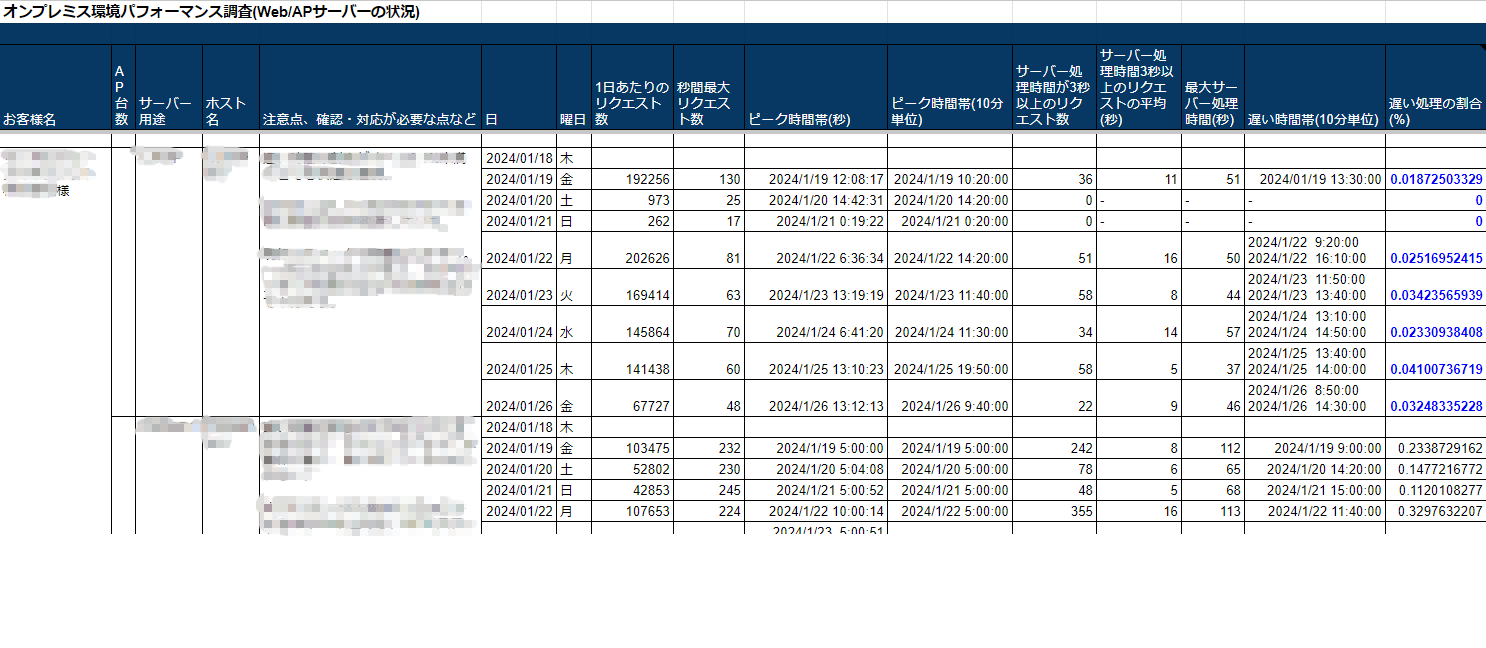
「avg_transfer_per_request.py」と「max_requests_per_second_per_day.py」の実行結果からは、Webサービスの利用にあたり、ネットワーク帯域幅がどの程度必要かを見積もる事が可能です。
ネットワーク帯域幅見積もりの考え方は、以下の記事を参照ください。
おわりに
Webサーバーのアクセスログをスクリプトで解析できるようにする事で、調査時間を大幅に短縮できました。
本記事に掲載したスクリプトは、そのままでは動作しないかもしれませんが、ご自由に改変してご利用ください。
※今一な実装になっている箇所が多々あるかと思いますが、その点はご容赦ください。