はじめに
Oracleに限らず、データベースの処理が原因でパフォーマンスが悪化している場合、明らかにメモリ割り当てが足りなかったり、ハードウェア、OSの問題でない限り、アプリケーションから実行されるSQLに問題がある事が多いです。
SQLの問題というのも、更に深堀りすれば、表や索引といったデータベースの論理設計(データ構造)の問題、データ量を意識しないで実装してしまっている、アプリケーション設計の問題などが根本原因だったりします。
しかし、データベースの論理設計の問題などは、すぐに対処できるレベルのものではないため、この記事では、SQLが問題でパフォーマンス問題が起きてしまった際に、どのようにチューニングしていったらいいか、考え方をまとめてみたいと思います。
(参考)DBのチューニング効果の一般論
一般的には、チューニング効果が大きいのは、以下の順番と言われています。
- ビジネスルールのチューニング
- データ設計(ER図、CRUD図など)のチューニング
- SQLのチューニング(SQL文の書き方、索引やテーブル定義等の設定、設計変更など)
- アプリケーション設計のチューニング(UI/UX、プログラムのロジック、スレッド設計、APサーバー設定など)
- データベース物理構造のチューニング(CPU、メモリ割当て、メモリ競合、I/Oのチューニング)
- OS、ネットワーク、H/Wのチューニング
パフォーマンスに限らず、セキュリティなどについても同様の事が言えますが、開発のなるべく早い段階(アーキテクチャー設計など、設計の初期段階)から、パフォーマンスを意識した実装と定期的な検証を行う事がとても大切です。
SQLを書く際に意識して欲しい事
SQLのチューニングについて記述する前に、SQLを書く際に意識して欲しい事があります。
それは、SQLは集合演算だという事。
DBMSが行う処理には、以下の8つがあります。
- 和演算 →2つのテーブルを1つにまとめる。
- 差演算 →2つのテーブルから1つのテーブル属するデータだけを取り出す。
- 積演算 →2つのテーブルの共通部分だけを取り出す。
- 商演算 →2つのテーブルを比較し、共通するデータの一部を取り出す。
- 選択演算 →指定された条件を満たすデータを取り出す。
- 射影演算 →テーブルから特定の列(項目)だけを取り出す。
- 直積演算 →2つのテーブルのデータを全ての項目で統合する。
- 結合演算 →2つのテーブルに共通しているデータを基準に1つにまとめる。
和演算は、SQLで言うところの、「UNION」、「UNION ALL」に該当する処理、差演算は「MINUS」、積演算は「INTERSECT」、その他も、SELECT文の列指定やJOIN、Where句による絞り込みなどに該当します。
何が言いたいかというと、SQLでは、処理対象とする集合(表)は、なるべく小さい方がよいという事(当たり前の話ではありますが)。
扱う集合を小さくするには、Where句などで適切な条件で絞り込みを行いつつ、索引などの効率よく絞り込みを行える仕組みを活用する。
※根本的には、データ構造(テーブル設計)の見直しが重要
また、索引などを効果的に活用する為のSQL文の記述方法について知っておくことが大切です。
更に言うと、今検索しようとしているテーブルは、将来的にどの程度の行数、データサイズになるのか、絞り込み条件になりうる列のカーディナリティ(列の値の種類)がどの程度かを設計段階から意識しておくのが、パフォーマンス的に大切な要素であり、チューニングの第一歩になります。
SQLのチューニング
Oracle Databaseには、SQLのパフォーマンスを改善するための様々な機能(パラレルクエリ、データ圧縮、パーティションなど)がありますが、殆どがEnterprise Editionでしか利用できない機能です。
その為、多くの環境で利用されていると思われる、Standard Edition環境においては、索引の見直し(索引の追加など)が、最初に検討するチューニングポイントになります。
索引の検討においては、SQLの実行計画を確認する必要があります。
まずは、実行計画の確認方法について説明します。
実行計画の出力方法や問題がありそうなSQLの調査方法については、以下の記事も参考にしていただければと思います。
実行計画の見方
SQLの実行計画では、下図①~⑦の情報を確認する事ができます。

| 情報 | 説明 |
|---|---|
| ①Operation | SQLの処理ステップおよび操作の種類がツリー表示されます。※ただし、IDの順番に処理が行われる訳ではないので、注意が必要です。 |
| ②Name | ステップでの操作対象となる、表や索引などのオブジェクト名 |
| ③Rows | ステップでの操作により、上位ステップに返す見積もり行数 |
| ④Bytes | ステップでの操作により、上位ステップに返すRowsの見積もりバイト数 |
| ⑤Costs | そのステップ以下のステップの累積コスト(Oracleが予測した処理時間(単位なし)) |
| ⑥Time | そのステップ以下のステップの予想処理時間 |
| ⑦補足情報 | Join時の結合条件などの補足情報 |
SQLをどのような順序で処理していくかは、Operationツリーで確認します。
実行計画の解釈は、次のような原則を踏まえ行います。
- レベルの高い(ツリーのリーフにあたる)処理が先に実行され、処理結果を親処理にわたす
- 同じレベルにある処理の場合、上に表示されている処理が先に実行される
- 処理には、他の処理が含まれる場合がある
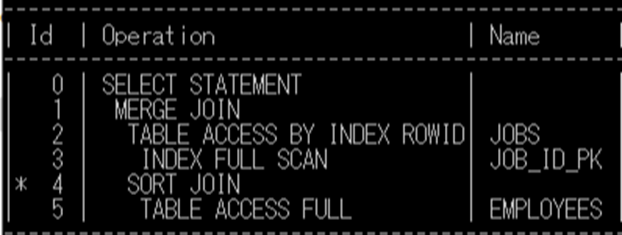
この原則に従うと、上図のSQLの実行計画は、以下の順番で処理されます。
- リーフにあたる処理は、Id3とId5
- このうち、上に表示されているId3の処理(索引JOB_ID_PKをスキャンし、EMPLOYEES表のJOB_IDにマッチするJOBS表のレコードのROWIDを取得)がまず実行され、その結果を使いId2の処理(索引で特定された行データを取得)を実行
- 次にId5の処理(EMPLOYEES表の全データを取得)が行われ、Id4のSORT JOIN処理(MERGE JOINの前処理のソート操作)が行われる
- 2、3の結果をId1でマージ結合処理し、SQL実行結果を返す
※このSQLは、Id3→2→5→4→1の順番に(Id2と3、Id4と5はセットとなる処理)実行されます。
統計値の見方
Rows、Bytes、Cost、Time列には、各ステップの統計値が表示されます。
この中で、Rows統計の値(Bytesも少ない方がよりよい)がチューニング上重要な統計値です。
SQLは「集合演算」と説明した通り、実行計画の処理ステップの早い段階で操作対象のレコード数が絞られる(Rowsの値が小さくなる)ような実行計画が望ましく、それにより処理の高速化が見込めます。
ただし、1つ注意点があります。
それは、通常の方法で確認できる実行計画の統計値は、あくまでもオプティマイザが予測した統計値(見積統計)であり、実際の統計値ではない事です。
統計情報と実データとに大きな乖離があったり(バッチ処理実行後など)すると、適切でない実行計画が作成される場合もあるため、見積もりと実際の結果に乖離がないか、実行統計を調べる事で確認する事ができます。
見積統計および実行統計を確認するには、以下の方法があります。
- 初期化パラメータSTATISTICS_LEVEL=ALLを設定
- 調査対象のSQLを実行
- DBMS_XPLAN.DISPLAY_CURSORに、引数format=>'ALLSTATS LAST'を指定し、共有プール上の実行計画を確認
select * from TABLE(DBMS_XPLAN.DISPLAY_CURSOR(format=>'ALLSTATS LAST'));
見積統計および実行統計を出力した場合、見積統計値は、E-RowsなどE-で始まる項目として、実行統計値は、A-RowsなどA-で始まる項目(その他、Starts、Buffersも)として出力されます。
見積統計と実行統計の差が大きい場合、オプティマイザが見積もりに失敗している可能性が高いため、ヒストグラム(列値の頻度)収集などによりオプティマイザ統計を改善することで、見積もり精度を上げる必要があります。
実行計画のOperationの種類
実行計画のOperationは、実行したSQLに対して、オプティマイザが実際にどのような手段でデータを取得するよう計画したかを示すものです。
以下に、実行計画のOperationの種類のうち、主なものを紹介しますが、NETSTED LOOPやMERGE、HASH、SORT、FULL(SCAN)など、プログラミングをした事がある人であれば、どんなロジックでOracleがデータを取得しようとしているのか、何となくイメージが湧くのではないかと思います。
| 操作(Operation) | オプション | 操作の内容 |
|---|---|---|
| NESTED LOOP | ネステッド・ループ結合 を使用した結合処理 | |
| OUTER | ネストしたループを使用した 外部結合 処理 | |
| MERGE JOIN | 2つの行セットそれぞれを特定の項目でソートして結合した結果を戻す(ソートは別のオペレーターで出てくる) ⇒ ソート・マージ結合 | |
| OUTER | マージ結合による外部結合 | |
| ANTI | マージ結合によるアンチ結合(逆結合) | |
| SEMI | マージ結合によるセミ結合(半結合) | |
| CARTESIAN | マージ結合による CARTESIAN=デカルト積(直積) | |
| HASH JOIN | ハッシュによる 2 つの行セットの結合 | |
| ANTI | ハッシュによるアンチ結合(逆結合) | |
| SEMI | ハッシュによるセミ結合(半結合) | |
| RIGHT ANTI | ハッシュによる右側アンチ結合 | |
| RIGHT SEMI | ハッシュによる右側セミ結合 | |
| OUTER | ハッシュによる(左側)外部結合 | |
| RIGHT OUTER | ハッシュによる右側外部結合 | |
| DOMAIN INDEX | ドメイン・インデックスから ROWID を取得する | |
| INDEX | UNIQUE SCAN | B-Tree 索引 からユニークキーを使用して1つの ROWID を取得する |
| RANGE SCAN | 索引から範囲(スタート・キー、ストップ・キー)をキーにして1または複数 ROWID の取得 | |
| RANGE SCAN DESCENDING | INDEX RANGE SCAN を索引値の降順にスキャン | |
| FULL SCAN | 索引からのすべての ROWID の取得 | |
| FULL SCAN DESCENDING | INDEX FULL SCAN を索引の降順で行なう | |
| FAST FULL SCAN | INDEX FULL SCAN の高速版:マルチブロック読み込みを使用するため取得順番は不定。インデックスに全カラムが含まれている場合 TABLE FULL SCAN と同じ意味になる(※ つまり ROWID だけでなくカラム値も取得する) | |
| SKIP SCAN | INDEX SKIP SCAN を使用した ROWID の取得 | |
| TABLE ACCESS | FULL | 表のすべての行を取得する |
| CLUSTER | 「索引クラスタのキーの値」を使用して表から行を取得する | |
| HASH | 「ハッシュ・クラスタのキーの値」を使用して表からの行を取得する | |
| BY USER ROWID | ROWID を使用して表からの行を取得する(ROWID を条件に指定した場合) | |
| BY INDEX ROWID | 索引を使用して行を取得する(索引はパーティション化していないもの) | |
| BY ROWID RANGE | ROWID 範囲を使用して表からの行を取得する | |
| MAT_VIEW ACCESS | FULL | TABLE ACCESS "FULL" のマテリアライズドビュー版 |
| CLUSTER | 同 CLUSTER オプション操作 | |
| HASH | 同 HASH 操作 | |
| BY USER ROWID | 同 BY USER ROWID オプション操作 | |
| BY INDEX ROWID | 同 BY INDEX ROWID オプション操作 | |
| BY ROWID RANGE | 同 BY ROWID RANGE オプション操作 | |
| MAT_VIEW REWRITE ACCESS | FULL ... etc |
TABLE ACCESS "FULL" のマテリアライズドビュー・リライト版。おそらく MAT_VIEW ACCESS と同じオプション群があると思われる。 |
| VIEW | ビュー の問合せを実行して行を取得する | |
| MINUS | 2つの行セットにおいて最初のセットにあって2番目のセットにない行を取得し、かつ、重複をなくす処理 | |
| INTERSECTION | 2つの行セットから重複をなくし共通部分を戻す | |
| UNION-ALL | 2つの行セットを和を戻す(重複した行の削除は行なわない) | |
| AND-EQUAL | 複数の ROWID のセットを受け取り重複をなくし共通する ROWID を戻す | |
| CONNECT BY | CONNECT BY 問合せにおいて階層順に行を取得する | |
| CONCATENATION | 複数の行のセットの UNION ALL を行なう ⇒ UNION | |
| COUNT | 選択された行数をカウントする | |
| STOPKEY | WHERE における ROWNUM 条件によって戻す行数を制限したカウント処理 | |
| FILTER | 行のセットから条件に合致するものだけを取得する | |
| FIRST ROW | 問合せ結果の最初の行のみを取得する | |
| FOR UPDATE | FOR UPDATE 句 による行ロック処理 | |
| HASH | GROUP BY | ハッシュ化することで行のセットをグループ化する。HASH JOIN とは別物 |
| UNIQUE | ハッシュ化することで行のセットの重複をなくす処理 | |
| INLIST ITERATOR | IN リスト条件 のそれぞれの値に対して後続操作を反復する | |
| CONNECT BY | CONNECT BY 問合せにおいて階層順に行を取得する | |
| REMOTE | リモート・データベースからデータを取得する | |
| SEQUENCE | 順序値 のアクセスをともなう処理 | |
| SORT | AGGREGATE | 選択した行セットにグループ化し、集約された行セットにグループ関数を適用した結果の取得(結果は単一行になる) |
| UNIQUE | 行セットをソートし重複をなくす | |
| GROUP BY | GROUP BY 句によるもの。行セットのグループ化するのための前処理としてのソート ⇒ HASH GROUP BY | |
| JOIN | マージ結合の前処理のソート操作 | |
| ORDER BY | ORDER BY 句による行セットのソート | |
| UNION | 2つの行セットの和集合から重複をなくして取得する UNION ALL 処理 ⇒ CONCATENATION |
索引
Oracleの索引には、以下のような種類があります。
※ただし、OLTPシステムの場合、実際に利用する事が多いのは、Bツリー索引です。
※スタンダードエディションでは利用できない索引もあるため注意です。
| 索引の種類 | 特徴 |
|---|---|
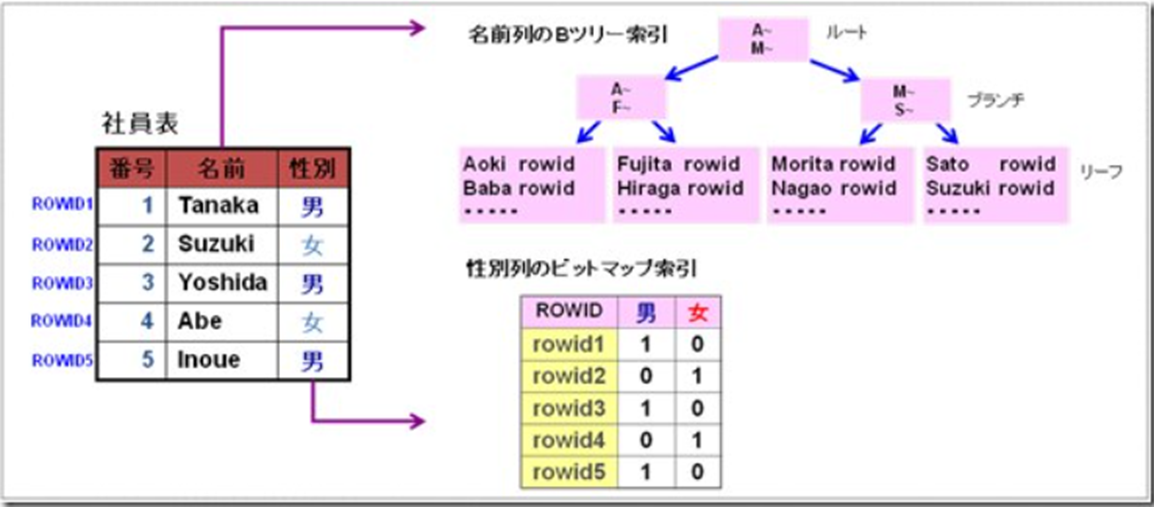
| Bツリー索引 | Bツリー索引はキーをツリー構造(上からルート・ブロック、ブランチ・ブロック、リーフ・ブロック)で管理します。 リーフ・ブロックには、行を特定するROWID(行ポインタ)を持っており、検索条件にマッチするキーをルート・ブロックからツリーを探索して、該当するリーフ・ブロックを特定し、データブロックにアクセスします。 Bツリー索引は、データの種類が多い(カーディナリティが高い)列に対して付けられます。 特定レコードの検索、範囲検索に有効な索引ですが、データの挿入・更新・削除を行うと、索引の構成も更新する必要があるため、更新系処理が遅くなる場合があります。 |
| ビットマップ索引 | ビットマップ索引はそれぞれのキー値ごとに、各行がその値かをビットマップ(1,0)で管理する構造です。 検索条件にマッチするキーをビット演算により探索し、ビットマップをROWIDに変換してデータブロックにアクセスします。 フラグ値や性別など、データの種類が少ない列をキーにした検索に有効な索引ですが、キー値の更新時には、その都度キー値からビットデータを作成する必要があるため、頻繁に更新されるデータには向きません。 |
| ファンクション索引 | 関数や演算子を利用した式の結果を格納した索引です。 SQL文のWHERE句に関数などの式を含んだ検索で、フルスキャンではなくインデックススキャンが利用可能となり、行ごとに計算結果を評価する必要がなくなるため、パフォーマンスが向上する場合があります。 |
| 索引構成表 | 索引スキャンは、索引にアクセスしてからROWIDでデータにアクセスするので、最低でも2ブロック(索引ブロックとデータブロック)アクセスする必要があります。 そこで、アクセスするブロック数をできるだけ少なくするために、索引に全てのデータを管理する構造としたのが索引構成表です(正確にはリーフ・ブロックに全てのデータを格納します)。 また、重複データなどのレンジ・スキャンのアクセスも改善されます。これは、重複データなどは索引ブロックでは隣接されるので(ソートされているので)、アクセスが1ブロックで可能になります。 ただし、レコードサイズが長いとリーフ・ブロックが増えて効率が悪くなる欠点があります。 |
この他にも、逆キーインデックス、索引クラスタ(ハッシュ・クラスタ)といった索引もあります。
参考)Bツリー索引とビットマップ索引の概念図
索引を使うかどうかの目安
※以降、索引はBツリー索引である前提で説明していきます。
パフォーマンスがよくないSQLについて、以下に該当するような列がある場合は、索引(必要に応じて複数列索引)の追加を検討します。
データ件数(サイズ)が多い表に対して、Where句での絞り込み条件や結合条件が指定されているが、フルスキャン(全表走査)になっている
特に、絞り込み条件に指定した列のカーディナリティが高い(列の値の種類が多い)場合、索引の追加が有効である可能性が高いです。
※カーディナリティが高いかについては、Where句の絞り込み条件により返される行数が、表全体の行数の10%未満かどうかが判断の参考値となります。
その他、列の値にNULL値が多く、NULL値以外の値を検索する場合も効果があります。
蛇足ではありますが、「データ件数が多い表に対して、Where句での絞り込み条件や結合条件が指定されているが、フルスキャン(全表走査)になっている」かの確認は、Statspack等で調査した遅いSQLの実行計画を確認して行います。
※実行計画の確認方法については、上述しています。
また、索引の追加による効果については、問題が発生している環境で、索引の追加、統計情報の再取得(可能であればスキーマ単位、無理なら表単位で)後、実行計画とSQLのレスポンスタイムが改善したかを確認します。
なお、索引追加の効果が見られなかった場合、索引を追加する事で、対象列の値が更新された際に、索引の更新も追加で発生して処理が遅くなる可能性があるため、その索引はすぐに削除するようにします。
索引を使わない方がいい場合
逆に、以下のような場合は、索引を作成する事によるデメリットの方が大きくなる為、索引を作成しないようにします。
- データ件数(サイズ)が少ない
- データ件数が少なく、サイズが小さい表については、索引にアクセスするより、全表走査した方が、アクセスするデータ・ブロック数が少なくて済むため
- 表から大部分のレコードを検索する
- Where句の絞り込み条件としてほとんど使われない
- 列の値が頻繁に更新される
- 更新処理のパフォーマンスが悪化するので、検索処理改善とのトレードオフ。ただし、通常絞り込み条件になる列は更新頻度は低い事が多い
(参考)外部キーの存在とUpdate文実行時の注意
外部キー(参照整合性制約)が設定されていると、子表の外部キー列に値が設定されるたびに、親表の主キーの存在チェックが行われます。
外部キーに索引が付けられていない場合、親表に対する削除、または子表が参照している列に影響を与える親表の更新を行うと、子表に表ロックが発生します。
このロックにより、更新処理に待ちが発生し問題になる場合がありますが、外部キーに索引を作成しておく事で、親表の主キー存在チェックを索引で確認する事でロックを回避することができます。
また、外部キーは結合条件となる事が多いので、無条件に索引を付けておく事をお勧めします。
また、(ORマッピングツールを使っていると難しいかもしれませんが)UPDATE文では、全ての列を無条件で更新するのでなく、必要な列のみ更新するようにします(索引列の値が更新されると、索引の構成も更新される為。特に主キーとなっている列は更新しないよう注意)。
SQLの記述により、索引が利用されないパターン
SQLの記述の仕方によっては、索引が意図通りに利用されない場合があります。その例をいくつか紹介します。
・Where句の左辺で、索引付きの列に対して演算を行っている
select * from hoge where col1 * 12 > 25000;
上記SQLでは、col1列に索引が貼られていても利用されません。以下の記述にする事で、col1列の索引が使われるようになります。
select * from hoge where col1 > 25000 / 12;
・Where句の条件にIS NULLが指定されている
索引にはNULL値が含まれていないため。
・索引付きの列に対してSQL関数が使用されている
select * from fuga where SUBSTR(col1, 1, 1) = ‘a’;
上記SQLは、以下のような記述とする事で索引が利用されるようになります。
select * from fuga where col1 like ‘a%’; ※ただし、前方一致のみ
※例外として、MIN()、MAX()については索引が利用されます。
・Where句の条件に否定形(NOT、!=、<>)を使っている
select * from fuga where col1 != 100;
例えば、以下のように修正する事で索引が利用されるようになります。
select * from fuga where col1 > 100;
・ORを用いている
select * from fuga where col1 = 100 or col2 = 20;
この場合は、UNION ALLなどに記述を置き換えられないかを検討します。
・後方一致または中間一致のLIKEを用いている
select * from fuga where col1 like ‘%a’;
select * from fuga where col1 like ‘%a%’;
この場合は、前方一致のみにできないか、OracleTextなどの全文検索エンジンを利用するなど、別の方法を検討します。
索引以外の確認ポイント
・統計情報
バッチ処理実行後など、実データの構造と統計情報とに乖離があると、オプティマイザにより効率的なアクセスパスが選択されず、SQLのパフォーマンスが悪化する場合があります。
データディクショナリで、統計情報が最後にいつ更新されたかを確認し、必要に応じて統計情報の再取得をしたり、上述した見積統計、実行統計を出力して比較し、オプティマイザ統計を改善(ヒストグラム収集など)する事も必要となります。
・実行計画を固定する
多くの場合、オプティマイザが最適な実行計画を選択してくれますが、時として意図した通りの実行計画が選択されない場合もあります。
このような場合、SQLヒントを指定する事で、アクセスパス、結合方法などを、オプティマイザに明示的に指示する事ができます(少し上級者向けの機能です)。
※他にも実行計画を固定する方法がありますが、実運用上利用が難しい為、本記事では割愛します。
例) DEPERTMENT表のDEPERTMENT_ID列の索引を利用し、EMPLOYEE表とネステッド・ループ結合でJOINするよう指示
SELECT /*+ INDEX(D I_DEPARTMENT$DEPARTMENT_ID) USE_NL(E D) */
E.EMPLOYEE_ID,
E.FIRST_NAME,
E.LAST_NAME,
D.NAME,
D.DEPARTMENT_ID
FROM
EMPLOYEE E, DEPARTMENT D
WHERE
D.DEPARTMENT_ID = D.DEPARTMENT_ID;
※ヒントの指定方法が間違っていた場合、無視されるだけでエラーとはならない(効果もないが)
※ヒントの使用により、実行計画が固定される
・Hard Parse
過去に実行したSQLが共有プールにキャッシュされていないとSQL実行時にHard Parseが発生し、その分余計な処理時間がかかります(共有プールのメモリも無駄に必要になる)。
Hard Parseの発生を抑え、SQLを効率よく実行する為には、以下を検討する必要があります。
-
バインド変数の利用
SQLのWhere句の条件として指定される値が、毎回異なるリテラル値である場合に、バインド変数(Javaの場合は「?」で指定)を使う事で、指定される値が違っても、オプティマイザは同じSQLと認識し、Hard Parseを抑制する事ができます。 -
SQL記述方法の規約化
各開発者が、それぞれ好きな形式でSQLを実行していると、SQLが再利用されにくくなり、Hard Parseが発生しやすくなるため、SQL記述方法を規約化し、統一されたフォーマットでSQLを記述する事も大切です。
以下の例のように、同じ意味のSQLでも、実行計画が再利用されない場合があります。
実行計画が再利用されない例
| 実行順 | 実行されたSQL文 | 再利用されない理由 |
|---|---|---|
| 1 | SELECT * FROM emp WHERE empno = 7788; | インスタンス再起動、共有プールのFlash後など、初実行時は必ずHard Parseが発生 |
| 2 | SELECT * FROM emp WHERE empno = 8000; | 1のSQLと、Where句に指定されているリテラル値が異なる為、Hard Parseが発生 ※バインド変数を使用している場合、条件値が異なっても同じSQLと判断され、Hard Parseは発生せず、実行計画が再利用される |
| 3 | SELECT * FROM emp WHERE empno = 7788; | 1のSQLと、スペースの個数が異なる為、Hard Parseが発生 |
| 4 | SELECT * FROM emp WHERE empno = 7788; |
1のSQLと、改行の有無が異なる為、Hard Parseが発生 |
| 5 | SELECT * FROM EMP WHERE empno = 7788; | 1のSQLと、大文字、小文字が異なる為、Hard Parseが発生 |
効率のよいSQLにするためのTips
同じ意味のSQLであっても、書き方によりパフォーマンスに差が出る場合があります。
効率のよいSQLの書き方の例をいくつか紹介します。
・データの存在チェックをする場合、INよりEXISTSを使う方が効率がよい
例) 以下のSQL文は、
select name from personnel
where birthday in (select birthday from celebrities);
以下のように書き換えた方が効率がよいです。
select name from personnel p
where exists (select rowid from celebrities c where p.birthday = c.birthday);
・BETWEEN
BETWEENを使わなくても、=、<、>を組み合わせる事で同じ条件を指定できますが、BETWEENを使う方が効率的です。
・INの引数リストには、最もマッチする可能性が高いキーを左に記述する
INは左から右に引数を評価し、見つかった時点でTRUEを返し、それより右の引数を見ないため。
CASE式も同様の動作をするので、マッチする可能性が高い式を上に記述するようにします。
・件数取得の場合、count(*)より、count(primary key)の方が効率がよい
※count関数の引数に指定する列に索引が付けられている前提
・UNIONの代わりにUNION ALLを使う
UNIONでは、重複行を排除する際にソートが必要になるため、値の重複を気にしなくてよい、または重複が発生しない事が明らかな場合は、UNION ALLを使う方が効率的です。
・ワイルドカードは使わない
ワイルドカード(*)で全列を指定すると、実行時に実際の列名への読み替えによるオーバーヘッドが発生するため、必要な列のみを指定する方が効率がよいです。
また、その方がソースの可読性、仕様変更(カラム追加など)にも強くなります(ORマッピングツールなどを利用している場合は、難しいかもしれませんが)。
・表に別名をつける
表に別名を指定すると、SQLの解析時にどの列がどの表に属すかの判定を省略できるため効率的です。
特に複数の表を扱うSQLやたくさん実行されるSQL文で有効です。
・暗黙の型変換を回避する
型と代入値が一致しない場合、暗黙の型変換が行われますが、この変換は一度代入に失敗した後に行われるため、オーバーヘッドが発生します。
また、索引が使われなくなるため、型を意識してSQLを記述するようにします。
・無駄なソートをしない
ソート処理は負荷が大きい処理なので少ないデータの場合のみにするか、できるだけ無駄な(意味のない)ソート処理を行わないようにします。
なお、ORDER BY句だけでなく、暗黙的にソート処理が行われる指定(DISTINCT、UNION、INTERSECT、MINUSなど)があるため、本当に必要なのか検討した上で指定するよう注意します。
・表の結合数
コストベース・オプティマイザは、結合する順番の組合せを評価して、最もコストの低いものを選択しますが、表の数が多いとそのコスト計算に時間が掛かるのが問題になります。
そのため、その時間を抑えるために評価する組合せの最大数が決められています。
Oracle10g以降、2000までの組み合わせ数まで評価し、それを超える組み合わせについては評価しないようになっているため注意が必要です。
なお、表の結合数6と7では、以下の組合せ数になります。
- 結合数6:6! (6*5*4*3*2*1=720)
- 結合数7:7! (7*6*5*4*3*2*1=5,040 )
つまり、組み合わせ数が2,000を超える7つ以上の表結合では、すべての組合せを評価しないことになります。
7つ以上の表結合では、ベストな実行計画にならない場合があるため、ヒント句の指定が必要になるなど、チューニングが必要になる可能性があります。
というより、できれば表結合は6以下になるよう設計するようにしましょう。
・Viewの扱い
Viewはとても便利ですが、Viewと表を結合するようなSQL文や、View定義のSQL文にAVG、COUNT、SUMなどの集約関数、UNIONなどの集約演算子が含まれる場合、パフォーマンス悪化の原因になる場合があります。
・HAVING句は極力使わないようにする
可能であれば、WHERE句に置き換えるようにします。
・DISTINCTをEXISTSに
1対Nの関係の親を決定する問い合わせで、DISTINCTが必要となる場合は結合を避け、EXISTS句での代用を考慮。
・副問い合わせを表結合へ
多くの場合、副問い合わせは表結合に置き換えができます。
特に必然性のない副問い合わせは、表結合に置き換えるようにします。
・GROUP BY句を使う際の注意
GROUP BY句を使うと対象となる集合を全走査するため、対象件数が多い場合、適時WHERE句で絞り込みを行った後、集計処理が実行されるようにします。
・繰り返して使用する副問合せはWITH句を
SQL文の中で、同じ問合せを何回か実行しなければいけない場合があると思います。
同じ副問合せを複数回使用するような場合は、WITH句または一時表の使用を検討するとよいと思います。
・(参考)インラインビューを使う
インラインビューと書きましたが、結合する前にレコード件数を絞り込むと書いた方が分かりやすいかもしれません。
インラインビューは、簡単に書くと、select句やfrom句に記述するselect文です。
件数が多い表の結合は負荷が大きいため、件数を少なくしてから行った方が効率がよくなります。
最近のOracleなどのRDBMSのオプティマイザは進化しているので、ある程度好きなように書いても、効率よい実行計画を立ててくれるようになってきていますが、結合する表の数が多かったり、集合演算を含むような複雑なSQLの場合に、意図した実行計画が選択されない場合があります。
そのような場合には、インラインビューを使い、結合前にこの表のレコード件数を絞り込んでから結合して欲しいという"意図"をオプティマイザに伝える事で、パフォーマンスがよくなる可能性があります。
また、インラインビューを使う事で、SQLの可読性も上がるように思います(個人見解です)。
例えば、以下のSQL文は、
SELECT * FROM tab1 left outer join tab2 ON tab1.a = tab2.a AND tab2.b = 10;
インラインビューを使い、以下のように記述する事ができます。
SELECT * FROM tab1 left outer join (SELECT * FROM tab2 WHERE b = 10) B ON tab1.a = B.a;
また、少しトリッキーな例ですが、以下のSQL文は、
SELECT A.c2, count(*)
FROM tab1 as A, tab2 as B
WHERE A.c1 = B.c1 AND B.c2 = 10
GROUP BY A.c2;
インラインビューを使い、以下のように記述する事もできます。
SELECT A.c2, SUM(ct)
FROM tab1 as A, (SELECT c1, count(*) ct FROM tab2 WHERE c2 = 10 GROUP BY c1) as B
WHERE A.c1 = B.c1
GROUP BY A.c2;
・DMLに含まれる問い合わせの最適化
UPDATE、DELETE文には大抵WHERE句が含まれており、暗黙的に問い合わせが実行されています。
よって、SELECT文と同様にWHERE句や副問い合わせの最適化により、UPDATE、DELETE文の効率もよくなります。
・DELETEとTRUNCATE
100万件ある表のデータをDELETE文で全件削除し、その後同じテーブルを全件取得するselect文を実行すると、データ件数は0件でも、100万件のデータが挿入された事があるデータブロック(HWMまで)が走査されます。
アプリケーションで、特定の表をDELETEしてINSERTするような処理はなるべく避ける方が、HWMの影響を受けずに済みます。
メンテナンスなどで、表の全行を削除する必要があり、元に戻す必要が無い場合はTRUNCATE文を使います。
これによりHWMもクリアされるので、全データ削除後の全表スキャンのパフォーマンスも悪化しません(ROLLBACKができないので、その点は注意)。
・トランザクションのCOMMIT(主にバッチ処理)
COMMIT時には、ある程度のディスクI/Oが発生するため、COMMITの頻度により、バッチ処理の処理時間が変わってきます。
基本的にはCOMMITの頻度を減らす事で処理時間を削減できます(ROLLBACKの場合は逆)が、UNDO領域との兼ね合いをみつつ、設計、検証する事をお勧めします。
・PL/SQL(ストアドファンクション、パッケージ)の活用
どうしても処理時間を速くする必要がある処理で、通常のSQL処理では実現が難しい、バッチ処理など更新範囲が大きい処理をする場合は、PL/SQL(FUNCTION)を使う事も選択肢になるかもしれません。
PL/SQLを使うメリットは、「一つの要求で複数のSQL文を実行できる(ネットワークに対する負荷の軽減)」、「予め構文解析や内部中間コードへの変換をしておくため、処理時間が低減される」点などがあげられます。
また、共通のユーティリティとして、自作のSQL関数を作成する事も可能です。
逆にデメリットとして、「依存するDBオブジェクト(表など)に変更があると、コードの修正または再コンパイルが必要となるため、メンテナンス時の考慮点が増える」、「他のDBMSと互換性が無い為、環境がOracle Database依存になる」、「開発環境が貧弱」といった点もあるので、その点を考慮した上で利用するか検討してください。
以下のように、表関数を使う事で、複雑な条件で処理を行わなければ取得が難しい処理をストアドファンクション化(以下の例では「F_GET_XXXX」)し、実行結果をselect文で取得する事ができます。
select * from TABLE(F_GET_XXXX(?,?));
※表関数を使う事で、ストアドファンクションの返り値(PL/SQLのコレクション型などのオブジェクト)を表として扱う事ができます。
上述しましたが、SQLの書き方によるパフォーマンスへの影響は、オプティマイザの進歩により、過去有用だったTipsも、最新バージョンでは効果が無くなっている可能性があります。
しかし、SQLの書き方による違いやオプティマイザの挙動を知る上では有用だと思いますので、上記も意識してSQLを書いてみて欲しいと思います。
おわりに
OracleのSQLチューニングの考え方についてまとめてみました。
「最新のバージョンでは、こういう挙動になっている」であったり、記述に間違いなどあれば、ご指摘いただけるとありがたいです。
参考情報
一部について、津島博士のパフォーマンス講座を参考にさせていただきました。