はじめに
Statspackレポートからは、Oracle DatabaseのSE2環境でパフォーマンス状況の調査やDBサーバーのスペック見積もりなどに有用な情報が得られますが、フォーマットが非定型であるため、1時間毎に出力されたレポートを1週間分確認するといった場合、1つ1つファイルを確認していくのは非常に非効率です。
そこで、Statspackレポートで確認したい内容を解析し、結果をまとめて出力するスクリプトを作成してみました。
Statspackレポートの確認方法については、以下の記事も参考にしていただければと思います。
スクリプトの概要
Configファイルで指定したディレクトリに存在するStatspackレポートを1ファイル(File名の形式もConfigで指定)ずつ読み込みます。
各レポートファイルを解析し、Configで指定したキーワードを含む行が見つかったら、キーワードの文字列と半角スペース後、最初に出現する数値を集計し、その数値の最小値、最大値、平均値、中央値、最小値を記録したレポートファイル名、最大値を記録したレポートファイル名、中央値を記録したレポートファイル名を、Configで指定した解析結果出力ファイルに出力します。
例えば、以下のようなStatspackレポートのセクションで、「Buffer Hit %:」をキーワードに指定すると、この例では「93.12」という数値が集計対象になります。
全てのファイルの「Buffer Hit %:」の値を収集後、最小値、最大値、平均値、中央値などをバッファヒット率の解析結果として解析結果出力ファイルに出力します。
Instance Efficiency Indicators
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
Buffer Nowait %: 99.97 Redo NoWait %: 100.00
Buffer Hit %: 93.12 Optimal W/A Exec %: 100.00
Library Hit %: 93.49 Soft Parse %: 92.49
Execute to Parse %: 75.74 Latch Hit %: 100.00
Parse CPU to Parse Elapsd %: 91.47 % Non-Parse CPU: 96.47
Statspackレポートで確認したい情報
今回、Statspackレポートで確認したい項目として、以下を対象にしました。
Configファイルに指定するキーワードとその値の意味について、以下にまとめます。
| Configに指定するキーワード | 値の意味 |
|---|---|
| SGA Target ※SGA_Targetの後に連続した半角スペースあり |
SGAに実際に割り当てられたメモリ(MB) |
| PGA Target ※PGA_Targetの後に連続した半角スペースあり |
PGAに実際に割り当てられたメモリ(MB) |
| Buffer Cache: | データベース・バッファキャッシュに実際に割り当てられたメモリ(MB) |
| Shared Pool: | 共有プールに実際に割り当てられたメモリ(MB) |
| Buffer Hit %: | バッファヒット率 |
| Library Hit %: | ライブラリヒット率 |
| Av Act Sess: | 平均アクティブセッション数 |
| % SQL with executions>1: | 再利用されたSQL文の割合 |
| DB time: | Oracleデータベースが動作していた時間(分) |
| DB CPU: | OracleデータベースがCPUを使っていた時間(分) |
| Host: Total time (s): | ホストサーバーのCPUコア数×レポート期間(秒) |
| Host: Busy CPU time (s): | ホストサーバーがCPUを使っていた時間(秒) |
| % of time Host is Busy: | ホストサーバーのCPU使用率 |
| Instance: Total CPU time (s): | OracleデータベースがCPUを使っていた時間(秒) |
| % of Busy CPU used for Instance: | OracleデータベースのCPU使用率 |
| Instance: Total Database time (s): | Oracleデータベースが動作していた時間(秒) |
| Logical reads: | データブロックをメモリから読み込みした回数 |
| Physical reads: | データブロックをディスクから読み込みした回数 |
| Physical writes: | データブロックをディスクに書き込みした回数 |
| physical read total IO requests | ディスクからの読み込みIO数 |
| physical write total IO requests | ディスクへの書き込みIO数 |
| physical read total bytes | ディスクから読み込んだバイト数 |
| physical write total bytes | ディスクに書き込んだバイト数 |
Configファイル
以下のように指定します。
- Directoriesに、Statspackレポートが置いてあるディレクトリを指定します(複数指定する場合はカンマ区切り)
- OutputFilesに、解析結果を出力するファイルパスを指定します(Directoriesを複数指定した場合は、OutputFilesも同じ数だけ指定)
- FileNameには、Statspackレポートのファイル形式を指定します
- Keywordsには、解析したい値がヒットするキーワードを指定します(各キーワードで解析したい内容は上のセクションに記載しています)
#config.ini
[Statspack]
Directories = C:/performance/XXXX/stats_report/ASytem,
C:/performance/XXXX/stats_report/BSystem
OutputFiles = C:/performance/XXXX/stats_report/statspack_analysis_ASystem.csv,
C:/performance/XXXX/stats_report/statspack_analysis_BSystem.csv
FileName = spreport*.lst
keywords = SGA Target ,
PGA Target ,
Buffer Cache:,
Shared Pool:,
Buffer Hit %:,
Library Hit %:,
Av Act Sess:,
% SQL with executions>1:,
DB time:,
DB CPU:,
Host: Total time (s):,
Host: Busy CPU time (s):,
% of time Host is Busy:,
Instance: Total CPU time (s):,
% of Busy CPU used for Instance:,
Instance: Total Database time (s):,
Logical reads:,
Physical reads:,
Physical writes:,
physical read total IO requests,
physical write total IO requests,
physical read total bytes,
physical write total bytes
Statspackレポート解析スクリプト
import glob
import os
import re
import csv
import configparser
def parse_statspack_reports(directory, file_name, keywords):
keyword_stats = {k: [] for k in keywords}
keyword_report_files = {k: [] for k in keywords}
# # レポートファイルの一覧を取得
files = glob.glob(os.path.join(directory, file_name))
# レポートファイルごとに解析
for file in files:
fname = os.path.basename(file)
# print(file)
with open(file, "r") as f:
contents = f.read()
# キーワードごとに解析
for keyword in keywords:
# キーワードに完全一致する行を抽出
pattern = re.escape(keyword) + r'\s*([\d,.]+)'
regex = re.compile(pattern)
# match = regex.search(contents)
match = regex.search("".join(contents))
if match:
size = float(match.group(1).replace(',', ''))
keyword_stats[keyword].append(size)
# レポートファイル名を格納
keyword_report_files[keyword].append(fname)
return keyword_stats, keyword_report_files
def analyze_statspack_reports(directory, output_file, file_name, keywords):
keyword_stats, keyword_report_files = parse_statspack_reports(directory, file_name, keywords)
# 出力先のCSVファイルを作成
with open(output_file, 'w', newline='') as f:
writer = csv.writer(f)
# ヘッダーを書き込む
writer.writerow(['Keyword', 'Min Size', 'Min Report File', 'Max Size', 'Max Report File',
'Avg Size', 'Median Size', 'Median Report File'])
# キーワードごとに解析結果を書き込む
for keyword, sizes in keyword_stats.items():
min_size = min(sizes)
max_size = max(sizes)
avg_size = sum(sizes) / len(sizes)
median_size = sorted(sizes)[len(sizes)//2]
# キーワードに対応するレポート時間を取得
report_files = keyword_report_files[keyword]
min_time = report_files[sizes.index(min_size)]
max_time = report_files[sizes.index(max_size)]
median_time = report_files[sizes.index(median_size)]
writer.writerow([keyword, min_size, min_time,
max_size, max_time,
avg_size,
median_size, median_time])
print(f'解析結果は {output_file} に保存されました。')
if __name__ == "__main__":
config = configparser.ConfigParser(interpolation=None)
config_file = 'C:/performance/scripts/config/config.ini'
config.read(config_file)
directories = [directory.strip() for directory in config["Statspack"]["Directories"].split(",")]
output_files = [file.strip() for file in config["Statspack"]["OutputFiles"].split(",")]
if len(directories) != len(output_files):
raise ValueError("Number of log directories and output files doesn't match")
file_name = config["Statspack"]["FileName"]
keywords = [column.strip() for column in config["Statspack"]["keywords"].split(",")]
for i in range(len(directories)):
print(f'ディレクトリ {directories[i]} を確認中。')
analyze_statspack_reports(directories[i], output_files[i], file_name, keywords)
実行結果例
このスクリプトを実行すると以下のような結果が出力されます。
※147ファイルあるStatspackレポートを解析した結果(statspack_analysis_BSystem.csv)です。
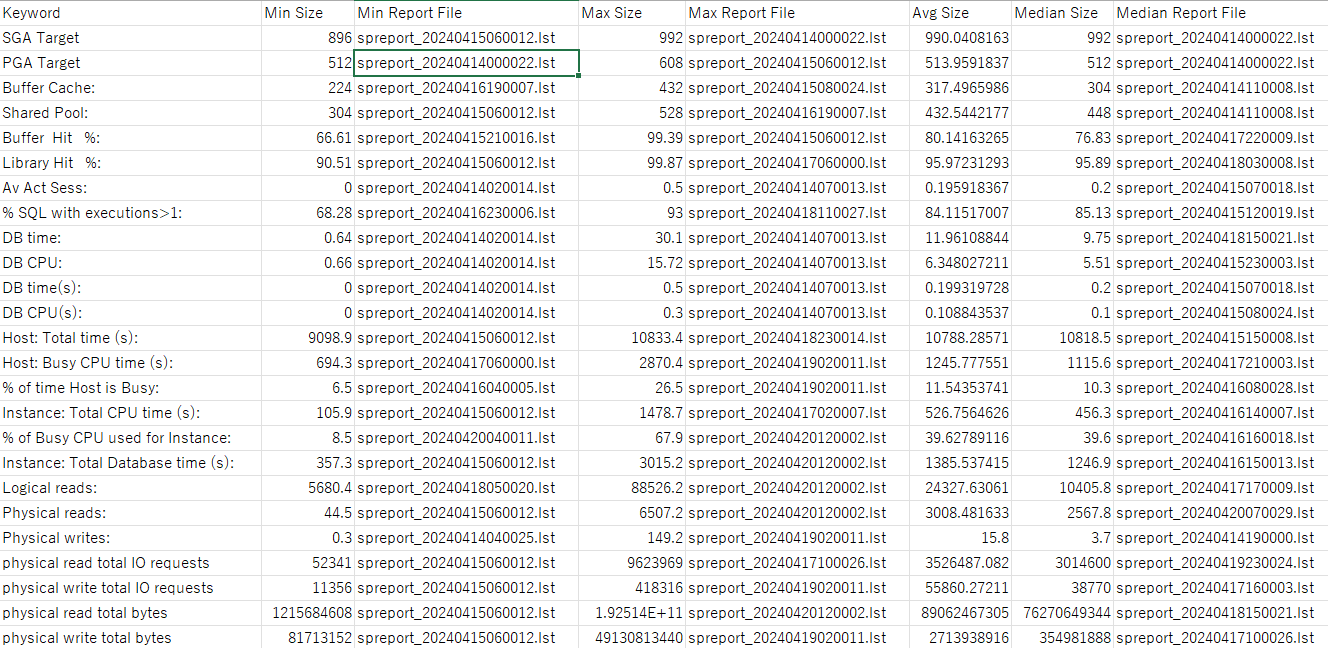
このスクリプトは、Configで指定したキーワードを含む行が見つかったら、キーワードの文字列と半角スペース後、最初に出現する数値を集計するものなので、未確認ですが、恐らくテキスト形式で出力したAWRレポートの解析などにも使えるのではないかと思います。
Oracleデータベースの動作状況サマリーを確認する際に、活用できるのではないかと思います。
動作状況サマリー以外の確認
上記の他に、各種アドバイザリー情報や、DB Time、DB CPU、メモリ、アクセスが多いオブジェクト、IO状況を時系列で確認したい場合があります。
その場合は、以下のようにgrepして状況を確認するようにしています。
grep -r -A 30 "Instance Efficiency Indicators" *.lst > InstanceEfficiencyIndicators.txt
grep "Host: Total time (s):" *.lst > HostTotalCPUTime.txt
grep "% of time Host is Busy:" *.lst > HostCPUBusy.txt
grep "Instance: Total CPU time (s):" *.lst > InstanceTotalCPUTime.txt
grep "% of Busy CPU used for Instance:" *.lst > InstanceCPUBusy.txt
grep "Instance: Total Database time (s):" *.lst > TotalDatabaseTime.txt
grep -r -A 7 "Memory Statistics" *.lst > MemoryStatistics.txt
grep -r -A 16 "Time Model System Stats" *.lst > TimeModelSystemStats.txt
grep -r -A 30 "Buffer Pool Advisory" *.lst > BufferPoolAdvisory.txt
grep -r -A 30 "PGA Memory Advisory" *.lst > PGAMemoryAdvisory.txt
grep -r -A 42 "Shared Pool Advisory" *.lst > SharedPoolAdvisory.txt
grep -r -A 22 "SGA Target Advisory" *.lst > SGATargetAdvisory.txt
grep -r -A 14 "Segments by Logical Reads" *.lst > SegmentsbyLogicalReads.txt
grep -r -A 12 "Segments by Physical Reads" *.lst > SegmentsbyPhysicalReads.txt
echo "Statistic Total per Second per Trans" > PhysicalReadTotalIoRequests.txt
grep "physical read total IO requests" *.lst >> PhysicalReadTotalIoRequests.txt
echo "Statistic Total per Second per Trans" > PhysicalReadTotalBytes.txt
grep "physical read total bytes" *.lst >> PhysicalReadTotalBytes.txt
echo "Statistic Total per Second per Trans" > PhysicalWriteTotalIoRequests.txt
grep "physical write total IO requests" *.lst >> PhysicalWriteTotalIoRequests.txt
echo "Statistic Total per Second per Trans" > PhysicalWriteTotalBytes.txt
grep "physical write total bytes" *.lst >> PhysicalWriteTotalBytes.txt
スクリプトでのサマリー出力とgrepでの確認(出力結果の加工は必要ですが)で、1つ1つファイルを確認するのに比べ、かなり効率的にStatspackレポートの解析ができるようになるのではないかと思います。
ただし、SQL ordered by Gets、SQL ordered by ReadsといったSQLセクションなどは1つ1つ確認が必要なので、もう少し効率よく確認できる方法がないか考えてみたいと思います。
おわりに
Statspackレポートをスクリプトで解析する方法をまとめてみました。