条件分岐とループベースのロジックからコレクションパイプラインを利用したロジックへ
概要
条件分岐とループベースのロジックからコレクションパイプラインを利用したロジックへの
置き換えについて説明します。
- コレクションパイプラインに関する概要を説明
- コレクション操作の基本: select / map ( collect ) / reduce ( inject )
- はしやすめ
- コレクションパイプライン サンプルケース
この記事の対象
コレクションパイプラインによるロジックを扱ったことがない方・不慣れな方が対象です。
コレクション操作の変遷
コレクションに対する処理はどの言語、どの領域のプログラミングでも頻出の課題です。
コレクションの操作は言語の基本的な文法としてサポートされている
条件分岐やループで処理することもできます。
コレクションパイプラインを利用すると、分かりやすく・スマートに記述することができます。
コレクションパイプラインは、ある処理の結果のコレクションを、
次の処理の入力とし、一連の連続した計算を行うパターンです。
そう、パイプを利用した UNIX のコマンドのように。
コレクション操作の基本:select / map ( collect ) / reduce ( inject )
コレクションパイプラインのサンプルの前に、
コレクション操作の基本である select / map ( collect ) / reduce ( inject )
について、ループ・条件分岐のロジックと対比しながら説明します。
select
イメージ
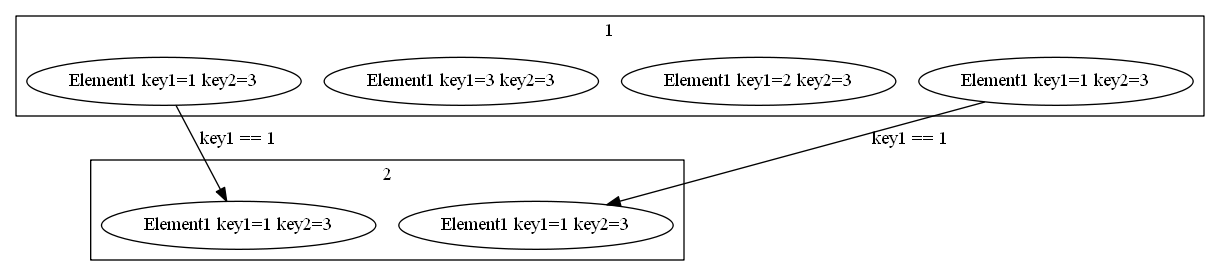
概要
コレクションから任意の条件を満たす要素を抽出します。
ここでは、 1 から 10 の数値リストから偶数の要素のみを抽出します。
コード
- 条件分岐とループ
list = [*1..10]
even_list = []
for i in 0..(list.size - 1) do
next if list[i].odd?
even_list << list[i]
end
print even_list # => [2, 4, 6, 8, 10]
- select メソッド
list = [*1..10]
print list.select { |e|e.even? } # => [2, 4, 6, 8, 10]
- select メソッド ( Symbol#to_proc を利用した省略記法)
ブロックを受け取るメソッドにProc以外を渡すと、
自動的に to_proc が呼び出され、型変換されます。
to_proc については下記を参照
るりま メソッド呼び出し(super・ブロック付き・yield)
ブロックの記述が不要になり、ブロックの仮引数を書く必要もなくなりました。
(仮引数 = ひとつ前の例の |e| の部分)
list = [*1..10]
print list.select(&:even?) # => [2, 4, 6, 8, 10]
- reject メソッド
条件を満たさない要素を抽出します。
select の反対です。 select 内に否定演算子を書かなければならないような場合は
こちらを利用するほうが自然になります。
list = [*1..10]
print list.reject(&:odd?) # => [2, 4, 6, 8, 10]
map ( collect )
イメージ
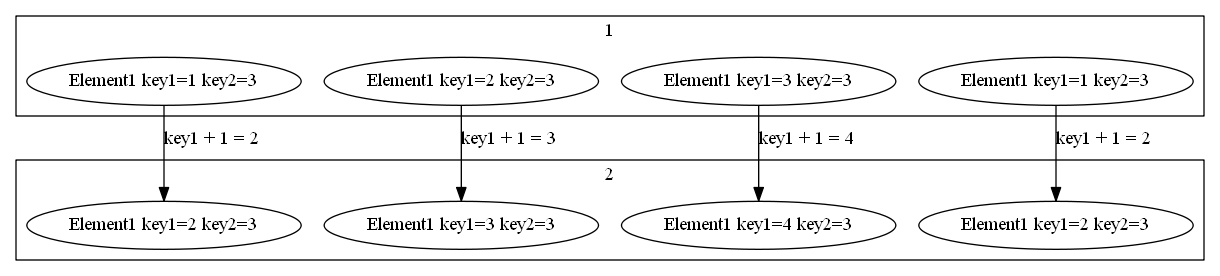
概要
コレクションの各要素に任意の処理を適用した結果を返却します。
ここでは、 1 から 10 の数値リストをすべて 2 倍にします。
Ruby では map と collect の二つのシンタックスシュガーが用意されています。
好みに合わせて使ってください。
詳しくは、 るりま | map と collect の発想の違い を参照。
コード
- 条件分岐とループ
list = [*1..10]
double_list = []
for i in 0..(list.size - 1) do
double_list << list[i] * 2
end
print double_list # => [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
- map メソッド
list = [*1..10]
print list.map { |e|e * 2 } # => [2, 4, 6, 8, 10, 12, 14, 16, 18, 20]
reduce ( inject )
イメージ
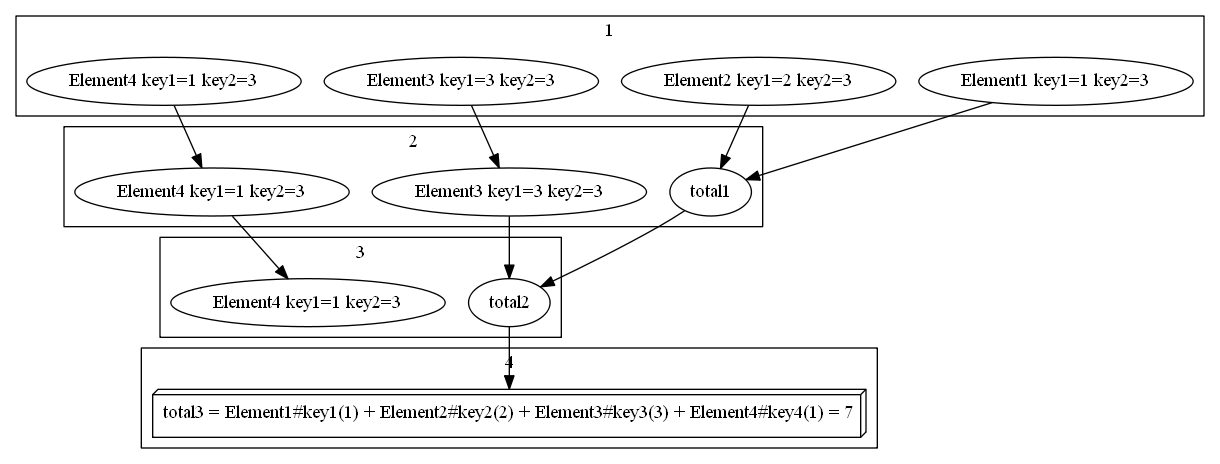
概要
コレクションの各要素に任意の処理を適用した結果を1つの変数に設定します。
ここでは、 1 から 10 の数値リストを合計にします。
Ruby では reduce と inject の二つのシンタックスシュガーが用意されています。
好みに合わせて使ってください。
るりま | reduce と inject の発想の違い
コード
- 条件分岐とループ
list = [*1..10]
total = 0
for i in 0..(list.size - 1) do
total += list[i]
end
print total # => 55
- reduce メソッド
list = [*1..10]
print list.reduce(&:+) # => 55
はしやすめ
tap
イメージ
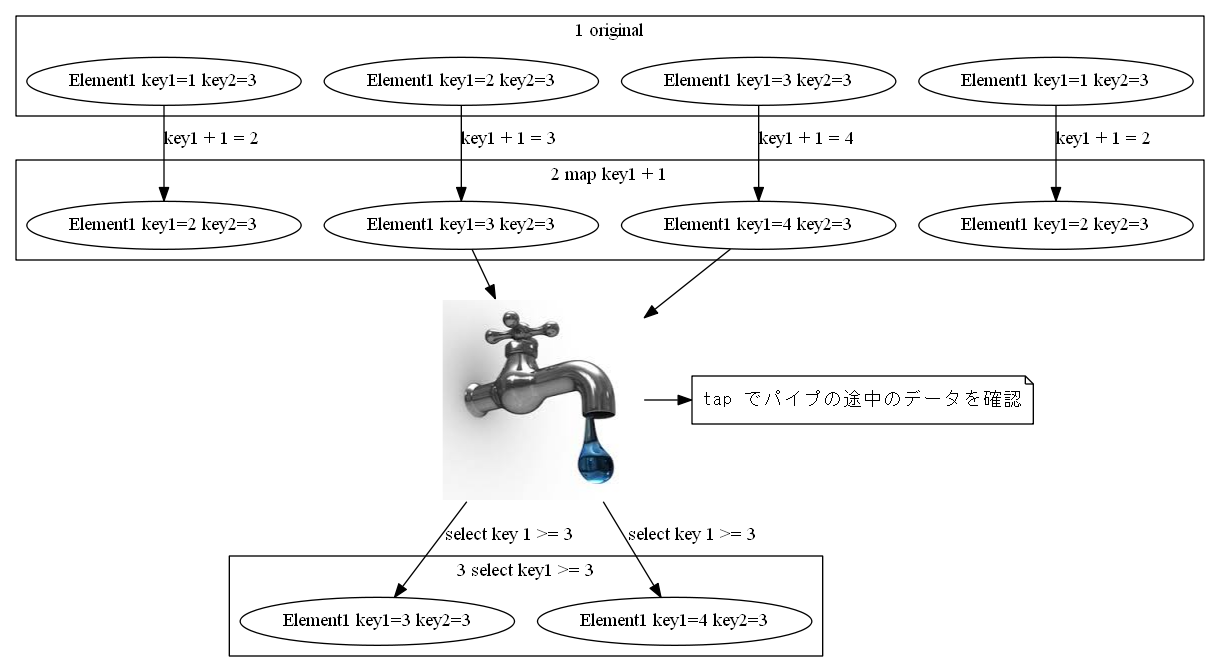
概要
コレクション操作の途中で値を確認したい場合、 tap メソッドを重宝します。
コード
1-10 の数値配列から
- 奇数のみを抽出
- 2倍にする
- 合計する
という操作をします。
2倍にした直後の値を確認するために、 tap を利用します。
list = [*1..10]
puts list.select(&:odd?)
.map { |e|e * 2 }
.tap { |e|print e, "\n" }
.reduce(&:+)
- 出力
[2, 6, 10, 14, 18]
50
コレクションパイプライン サンプルケース
ここからが本番です。
Engineer クラスのコレクションを操作します。
Engineer クラスは以下の属性を持ちます。
| key | type | contents |
|---|---|---|
| name | String | 名前 |
| age | Fixnum | 年齢 |
| burn_out | bool | 燃え尽きたかどうか |
| company | String | 所属企業 |
| hours_worked_per_annum | Fixnum | 月労時間 |
基礎データ
各サンプルから require して利用する共通データ。
以下の項目を持ちます。
Engineer = Struct.new(:name, :age, :burn_out, :company, :hours_worked_per_annum)
def read_engineers
engineers_src = [
{ name: 'tanaka', age: 23, burn_out: false, company: 'white', hours_worked_per_annum: 170 },
{ name: 'sato', age: 50, burn_out: false, company: 'white', hours_worked_per_annum: 160 },
{ name: 'honda', age: 32, burn_out: false, company: 'white', hours_worked_per_annum: 180 },
{ name: 'suzuki', age: 32, burn_out: false, company: 'normal', hours_worked_per_annum: 180 },
{ name: 'fujita', age: 32, burn_out: false, company: 'normal', hours_worked_per_annum: 180 },
{ name: 'kaneda', age: 32, burn_out: false, company: 'normal', hours_worked_per_annum: 180 },
{ name: 'nonomura', age: 48, burn_out: true, company: 'black', hours_worked_per_annum: 400 },
{ name: 'obokata', age: 31, burn_out: true, company: 'black', hours_worked_per_annum: 300 },
{ name: 'katayama-yuchan', age: 123, burn_out: true, company: 'black', hours_worked_per_annum: 350 },
{ name: 'samuragochi', age: 42, burn_out: false, company: 'black', hours_worked_per_annum: 50 }
]
engineers_src.map do |e|
Engineer.new(
e[:name],
e[:age],
e[:burn_out],
e[:company],
e[:hours_worked_per_annum]
)
end
end
サンプル1: ホワイト企業の技術者の名前と年齢のリスト
require 'pp'
require './engineers'
engineers = read_engineers
pp engineers.select { |e|e.company == 'white' }
.map { |e|[e.name, e.age] }
__END__
[["tanaka", 23], ["sato", 50], ["honda", 32]]
サンプル2: 企業名ごとにグループ化された技術者の名前と年齢のリスト
- group_by については るりま | Enumerable#group_by をご確認ください
require 'pp'
require './engineers'
engineers = read_engineers
pp engineers.group_by { |e| e.company }
.map { |k, v|{k => v.map { |e|[e.name, e.age] } } }
__END__
[{"white"=>[["tanaka", 23], ["sato", 50], ["honda", 32]]},
{"normal"=>[["suzuki", 32], ["fujita", 32], ["kaneda", 32]]},
{"black"=>
[["nonomura", 48],
["obokata", 31],
["katayama-yuchan", 123],
["samuragochi", 42]]}]
サンプル3: 企業ごとの労働時間合計を降順でソート
- sort_by については るりま | Enumerable#sort_by をご確認ください
require 'pp'
require './engineers'
engineers = read_engineers
pp engineers.group_by { |e| e.company }
.map { |k, value|{ name: k, total_hours_worked_per_annum: value.reduce(0) { |a, e|a + e.hours_worked_per_annum } } }
.sort_by { |e|-e[:total_hours_worked_per_annum] }
__END__
[{:name=>"black", :total_hours_worked_per_annum=>1100},
{:name=>"normal", :total_hours_worked_per_annum=>540},
{:name=>"white", :total_hours_worked_per_annum=>510}]
サンプル4: 企業名ごとにグループ化された35歳より上の技術者の人数
require 'pp'
require './engineers'
engineers = read_engineers
pp engineers.group_by { |e| e.company }
.map { |k, v|{ k => v.count { |e|e.age >= 35 } } }
__END__
[{"white"=>1}, {"normal"=>0}, {"black"=>3}]
サンプル5: 燃え尽きた技術者からランダムで2名抽出し、名前の昇順でソート
- sample については るりま | Array#sample をご確認ください
require 'pp'
require './engineers'
engineers = read_engineers
pp engineers.select(&:burn_out)
.sample(2)
.sort_by(&:name)
__END__
実行 1 回目
[#<struct Engineer
name="katayama-yuchan",
age=123,
burn_out=true,
company="black",
hours_worked_per_annum=350>,
#<struct Engineer
name="obokata",
age=31,
burn_out=true,
company="black",
hours_worked_per_annum=300>]
実行 2 回目
[#<struct Engineer
name="nonomura",
age=48,
burn_out=true,
company="black",
hours_worked_per_annum=400>,
#<struct Engineer
name="obokata",
age=31,
burn_out=true,
company="black",
hours_worked_per_annum=300>]