e-statの政府統計のexcelデータって、無駄な全角空白とか、セルの結合ゴリゴリとか、Rで食べさせるにはどうしても一旦Excelで整形しないとダメだと思っていて敬遠してたけど、readxlが思いのほかパワフルに読み込んでくれるので楽しくなってきたので、メモ。
APIで抜くほどでもないけど、Excelで整形するのは面倒なときなどに。
方針
readxlは、とりあえず空白を含んでいようがセルが結合されていようが読み込んでくれるので、読み込み段階では工夫せず。
- とりあえず読み込み
- 必要なところを切り出して整形。
下記の3つで分けて切り出すのは、行・列ラベルなどは、無駄な全角空白・セルの結合ゴリゴリなどを、それぞれ個別でやっつける方が楽な気がするので。- 行ラベル
- 列ラベル
- データ
- ひっつけて縦持ちにしたりなど
- ここまでくればあとはよしなに
やってみる
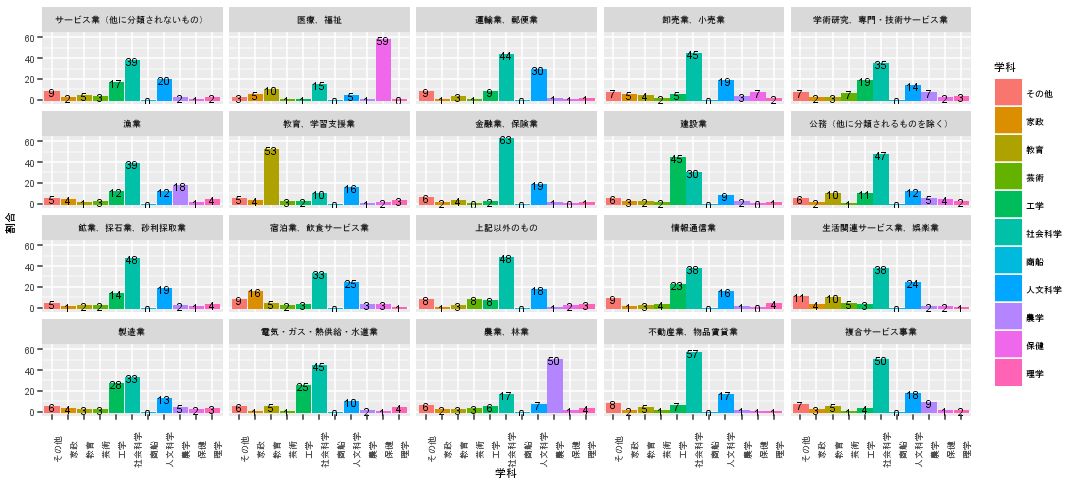
ためしに、学校基本調査の平成29年度の卒業後の状況調査の「産業別 就職者数」のデータで大卒の子でどの学科の子がどんな職業についているか?などをお題に。
とりあえず読み込み
# 何はともあれライブラリ読み込み
library("tidyverse")
library("readxl")
# 落としてきたファイルは適当なところに
working_dir ="C:/R/sample" # 作業ディレクトリ名
input_file ="./data/学校基本調査/076.xlsx" # 読み込むファイル名
setwd(working_dir)
# なにはともあれ読み込む
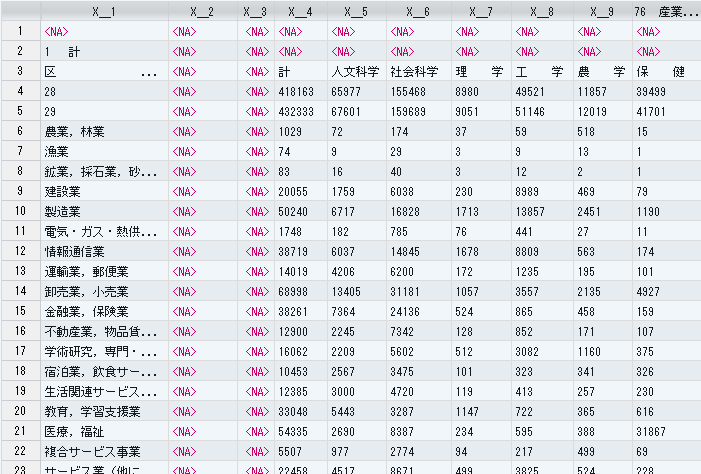
input_data <- read_excel(input_file,trim_ws=T,sheet=1)
必要なところを切り出して整形
読み込んだデータ見てみるとこんな感じ。セルの結合とかはないけど、列名に無駄な空白など、、
経年で複数ファイルあって繰り返し読み込みとかしないのであれば、
抜き方を考えるのに時間をかけるくらいなら、場所決め打ちでもいいと思う。
# 切り出すデータの範囲を決め打ち
cut_row <- 6:25
cut_col <- 5:15
# データ部分を切り出す
tmp_data <- input_data[cut_row, cut_col]
# 行名部分を切り出す
tmp_row <- input_data[cut_row, 1]
# 列名部分を切り出す
tmp_col <- input_data[3, cut_col]
# 列名・行名で整形が必要なものがあれば整形
# 今回は行名は整形不要、列名は無駄にスペースが入っているので適当に消す
tmp_col <- str_replace_all(tmp_col,"[ \\s]","")
# ひっつける時に備えて列名はつけておく
colnames(tmp_data) <- tmp_col
colnames(tmp_row) <- "職種"
列名は日本語か英語か?
昔はソースに日本語が混じるので、列名は基本英語だよねーと思っていたけど、
ほかの人が読んだり、後々の可読性を考えたり、これって英語でなんて言うんだっけ?などを考えたら、とりあえず動くのであれば日本語でもいいんじゃないかなと思う最近。英語にするなら切り出さずにつけてあげる。
ひっつけて縦持ちにしたりなど
行名部分にデータ部分をひっつける。
# つないで、縦持ちにして、数値データに
output_data <- tmp_row %>% # 行名部分に
bind_cols(tmp_data) %>% # データをひっつけて
gather(key=学科,value=人数,-職種) %>% # 縦持ちにして
mutate(人数=as.numeric(人数)) # 数値が文字列なので数値に
(データ的に)readxlで読むと数値が文字列になることが多いけど、読み込んだ時がんばらずに、縦持ちにしたときに一括で数値にする方が楽。
よしなに可視化など
それぞれの職種の入社する学生の学部の構成比など
# グラフ用にデータ整形
tmp <- output_data %>%
group_by(職種) %>% # 職種でしばって
mutate(割合=人数/sum(人数)*100) # 割合を出す
# グラフで可視化
tmp %>% ggplot(aes(x=学科,y=割合)) + # 横軸は学科で、縦軸は割合にしよう
geom_col(aes(fill=学科)) + # とりあえず棒グラフで、学科で塗り分けよう
geom_text(aes(label=round(割合,0)))+ # 割合の数も入れておこう
theme(axis.text.x = element_text(angle = 90))+ # 学科名は重なるので縦にして、
facet_wrap(~職種) # 職種別にグラフを分けよう。
こんな感じ