google apps script知識0から、スクレイピングをやってみました。
本記事のざっくりとした流れとしては下記の通りです。
1.google apps scriptの記述先
2.いったん動かしてみる(ログ出力)
3.いったん動かしてみる(スプレッドシートに値を書き込み)
4.標準機能だけでスクレイピング
5.ライブラリを使ったスクレイピング
必要なもの
・googleアカウント以上!開発ツールもウェブ上なのでサクサク作れちゃいますね!
スクリプトの記述場所
スプレッドシートのスクリプトエディタから記述可能 エクセルのvbsみたいな感じなんですね。 とにかくまずはログ出力
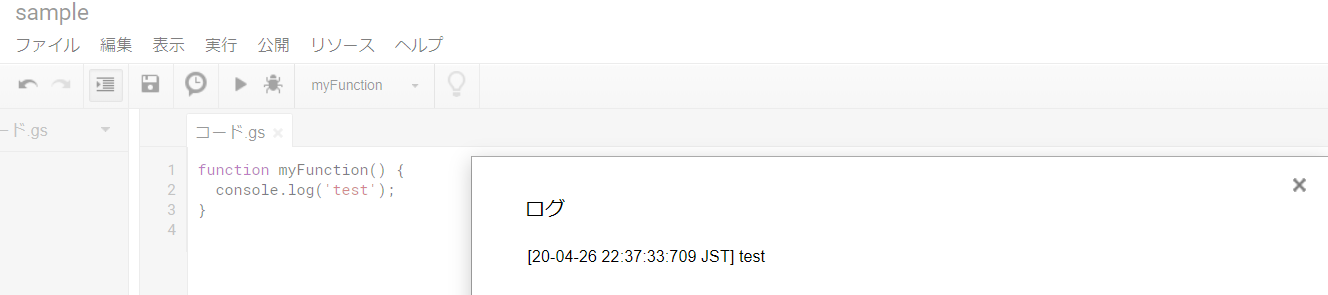
とりあえずjavascriptと同じような言語ということでconsole.logでログ出力してみました。function myFunction() {
console.log('test');
}
ログの確認はメニューの表示→ログで確認できます。
スプレッドシートに文字を書く
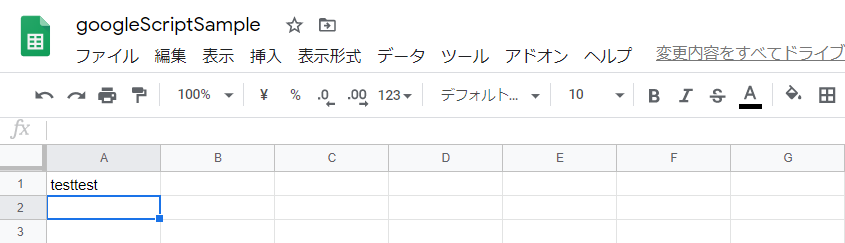
スクレイピングした結果をスプレッドシートに記載したいのでスプレッドシートに文字列を記述してみました。 ※スプレッドシートへのアクセス権付与が必要でした。ノリと勢いでやっているのでノリと勢いでOKしました。1.sheetオブジェクトを取得
2.rangeオブジェクトを取得してそこにtesttestという値をセット
function myFunction() {
var sheet = SpreadsheetApp.getActiveSheet();
sheet.getRange('A1').setValue('testtest');
}
スクレイピングの実装
ヤフートップページからタイトルタグを取得するコードを書いてみました。function myFunction() {
var sheet = SpreadsheetApp.getActiveSheet();
var url = 'https://www.yahoo.co.jp/';
//トップページ情報をすべて取得
var content = UrlFetchApp.fetch(url).getContentText('UTF-8');
//タイトルタグに一致する部分を正規表現で取得
var titleRegexp = new RegExp(/<title>.*?<\/title>/);
var item = content.match(titleRegexp);
sheet.getRange('A1').setValue((item[0]));
}
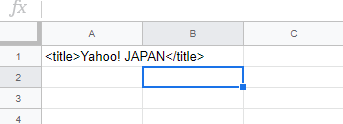
取得できました!
ライブラリを使うための準備
正規表現ではちょっとしんどいなーと思ったので、ライブラリをインポートしていろいろやってみました。 今回はライブラリの使い方、今私が知っているライブラリについて紹介します。ライブラリ一覧
私が調べたスクレイピングをより使いやすくするためのライブラリです。| ライブラリ名 | key | 機能紹介 |
| Parser | M1lugvAXKKtUxn_vdAG9JZleS6DrsjUUV | 文字列のfrom,toを指定し、その間の文字を取得します。 |
| html-parser-gas | 1Jrnqmfa6dNvBTzIgTeilzdo6zk0aUUhcXwLlQEbtkhaRR-fi5eAf4tBJ | getElementbyIdなどが使えます。 読込先ウェブサイトが必ず正しいフォーマットである必要があります。 amazonのウェブサイトの解析がうまく行えませんでした。 |
ライブラリのインポート方法
リソース→ライブラリからkeyを指定、インポートします。 Parserライブラリを使ってamazonの商品名を取得
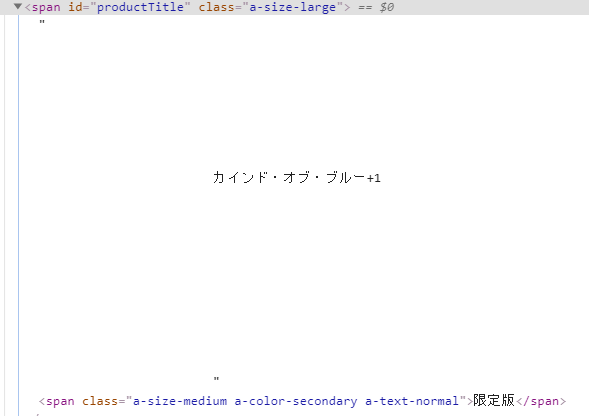
html-parser-gasではamazonで Parserライブラリを使ってamazonの商品名を取得しようと思います。 画像 ソース
function myFunction() {
var sheet = SpreadsheetApp.getActiveSheet();
var url = 'https://www.amazon.co.jp/gp/product/B00D1B8R9G?pf_rd_r=8QJ2ZY7TYN1EPACKS1V0&pf_rd_p=3d322af3-60ce-4778-b834-9b7ade73f617';
var content = UrlFetchApp.fetch(url).getContentText();
var scraped = Parser
.data(content)
.from('<span id="productTitle" class="a-size-large">')
.to('<span class')
.build();
sheet.getRange('A1').setValue(scraped);
}
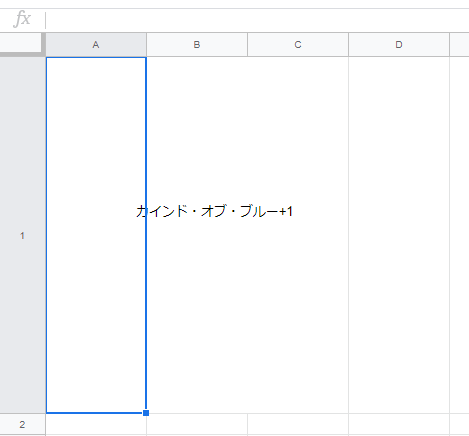
こうすることで無事値が取得できました!
定期実行させる
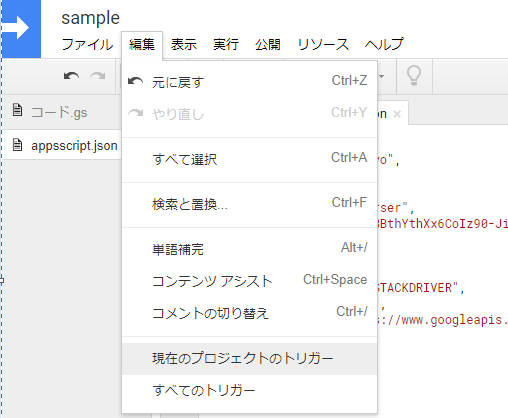
スクレイピングの値は定期実行して自動で値を取得したいですよね。 ということで定期実行のさせ方を調べてみました。1.スクリプトの[編集]から[現在のプロジェクトのトリガー]を選択
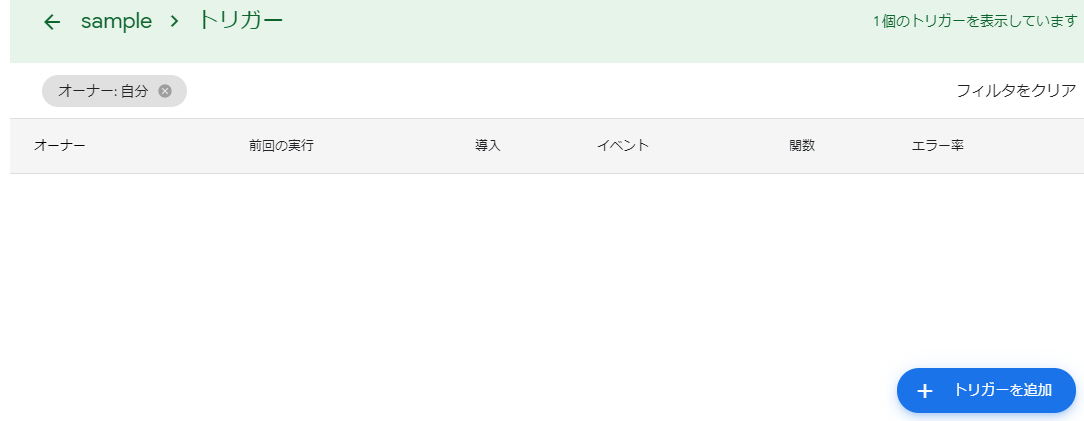
2.トリガーの追加をクリック
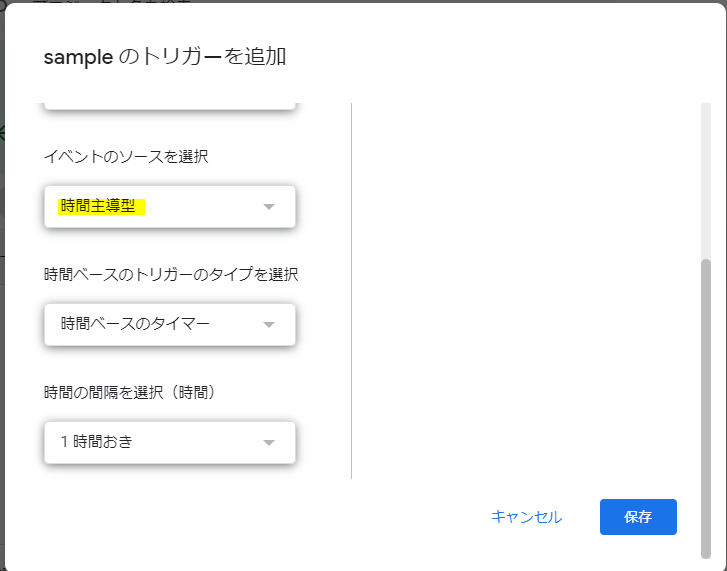
3.イベントのソースを時間手動型に変更
以上!
番外編 IMPORTXML関数で情報取得
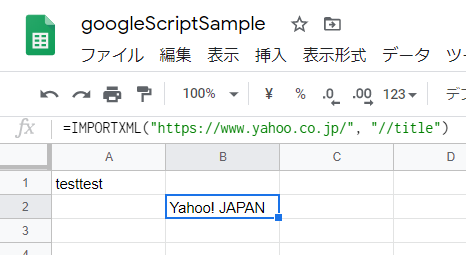
=IMPORTXML("https://google.com/", "//title")
これでヤフーのタイトルが取得できます。
めっちゃ便利,ただ数が多いと重くなりそうです。
参考:https://developers.google.com/apps-script/reference/spreadsheet/