初めに
Gigazineさんの、画像生成AI「Stable Diffusion」が実はかなり優秀な画像圧縮を実現できることが判明という記事を読んで、やってみたくなったので試しました。
画像縮小ではなく画像圧縮なので注意。画像の解像度は変わりません。
どんな仕組みか調べる
参考元:
※特にAIに詳しくない人間がコードだけ見て適当に解釈した結果なので間違ってる可能性があります。(タイトル見たらわかりますが多分間違えてます)
ぜひ勉強のためにも間違っている箇所などあれば教えてください。
StableDiffusionは画像の特徴を抽出するVAE(Variational Autoencoder)と、ノイズを除去するU-Netという2つのAIモデルから構成されている。
手順を簡単に説明すると、
- 画像を512*512の正方形に中央で切り取る
- VAEを使用して画像を潜在空間(latent)に変換し、すごく縮小(0.1825倍)する
- Unetを使用してノイズを消去する。
- すごく縮小したlatentをすごく拡大(0.1825で除算)する
- VAEをデコードして画像に戻す
みたいな感じらしい。
・・・
・・・・・・
・・・・・・・・・
正直、よくわからない!!!!!
こういう時は書いてある通りに作ってみましょ。
そしたら何かが見えてくるはず。
とりあえず再現してみる(ComfyUI)
参考元どうりPythonプログラムでやると思ったか?騙されたな!
そんな知識はありません。
ということでComfyUIで作ってみました。
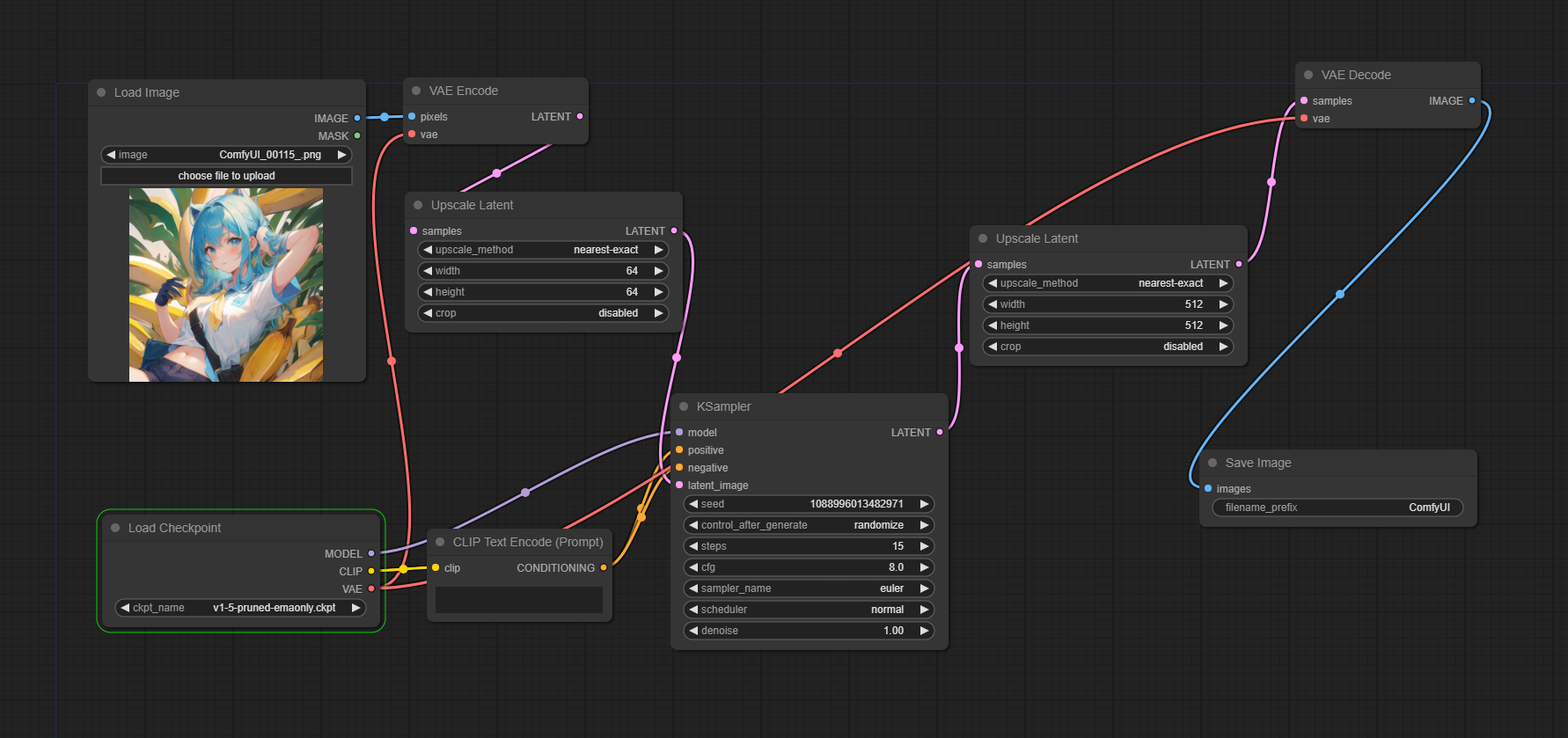
画像は適当に用意しました。とりあえずイラストで、無理そうなら写真を用意します。
latentをComfyUIではどう縮小したらいいんだ?って困ったので、とりあえずGigazine記事の通り64*64に縮小しておきました。
試してみた結果がこちらです。
元画像(423KB):

結果(243KB) Seed"818682320945873":

画像サイズ半分に圧縮できましたね()
失敗した原因の調査
64*64に縮小した時点で大量の情報が失われているのでは?
各過程の画像をそれぞれ表示してみた。
VAE Encode → 64 * 64縮小時:

KSampler処理終了時:

画像を見ると、縮小時によくわからない画像へと変化している。
また、KSampler後の画像にはステップ数が低いことで起こる謎のシミがあるようにも見える。
そこで、以下の変更をした。
Step数:15→30
縮小:64 * 64 → 216 * 216 (512の大体半分)
修正した結果
VAE Encode → 216 * 216縮小時:

KSampler処理終了時:

結果:

ここまでくるとやり方が間違っているような気がしてきた......
教えて!ChatGPT!
compress_inputという圧縮してそうな関数の内容を教えてもらった。
この関数は、入力ファイルを圧縮し、様々な圧縮手法を用いて結果を表示・保存します。以下が関数の概要です:
- 入力画像を
Image.open()を使って開き、gt_imgに読み込みます。to_latents()を用いてgt_imgを潜在変数に変換し、to_img()を使って再度画像に戻します。この過程を通じてVAE (Variational Autoencoder) の画像ラウンドトリップを行います。quantize()を使って潜在表現を量子化し、その後unquantize()を使って元の解像度に戻します。そして、量子化された画像を無損失のWebP形式で保存します。- 8ビットの量子化された潜在変数からVAEで復号された画像を表示し、評価指標を表示します。
- 8ビットの量子化された潜在変数をさらにパレット化し、libimagequantを使ってディザリングを行います。その結果、圧縮されたバイナリデータをnpzおよびバイナリファイルとして保存します。
- さらに、Zlibを使って圧縮された8ビットの潜在変数を生成し、バイナリファイルとして保存します。
- 8ビットの潜在変数をパレット化した画像を表示し、その後、Stable Diffusion U-Netを使用してノイズを除去します。
- ノイズが除去された画像を表示し、そのサイズと評価指標を表示します。
- さらに、JPEGとWebP形式の圧縮を行い、最適な品質設定で保存します。その後、それぞれの圧縮結果を表示し、サイズと評価指標を表示します。
この関数は、入力された画像データを様々な圧縮手法を用いて処理し、それぞれの手法での結果を比較・表示・保存する役割を持っています。
わっかんねぇ......
言い訳
情報少なすぎてなんもわかんにゃい......
そもそも論文も何言ってるか半分ぐらいしか分かんにゃい......
てか潜在空間ってなんだよ(哲学)
さて、言い訳し終わったので別の方法考えますかぁ......(ここまでで3時間半を消費)
記事通りにやるのはあきらめよう。
次の作戦はこうです。
- 画像に少しだけノイズを加える
- 画像をimg2imgで再生成させる
AIで生成される情報は現実の写真よりもノイズやらなんやらが少なくて、サイズが縮むんじゃないかという予想です。
簡単すぎていうことないですね。
今回のワークフローはこちら。
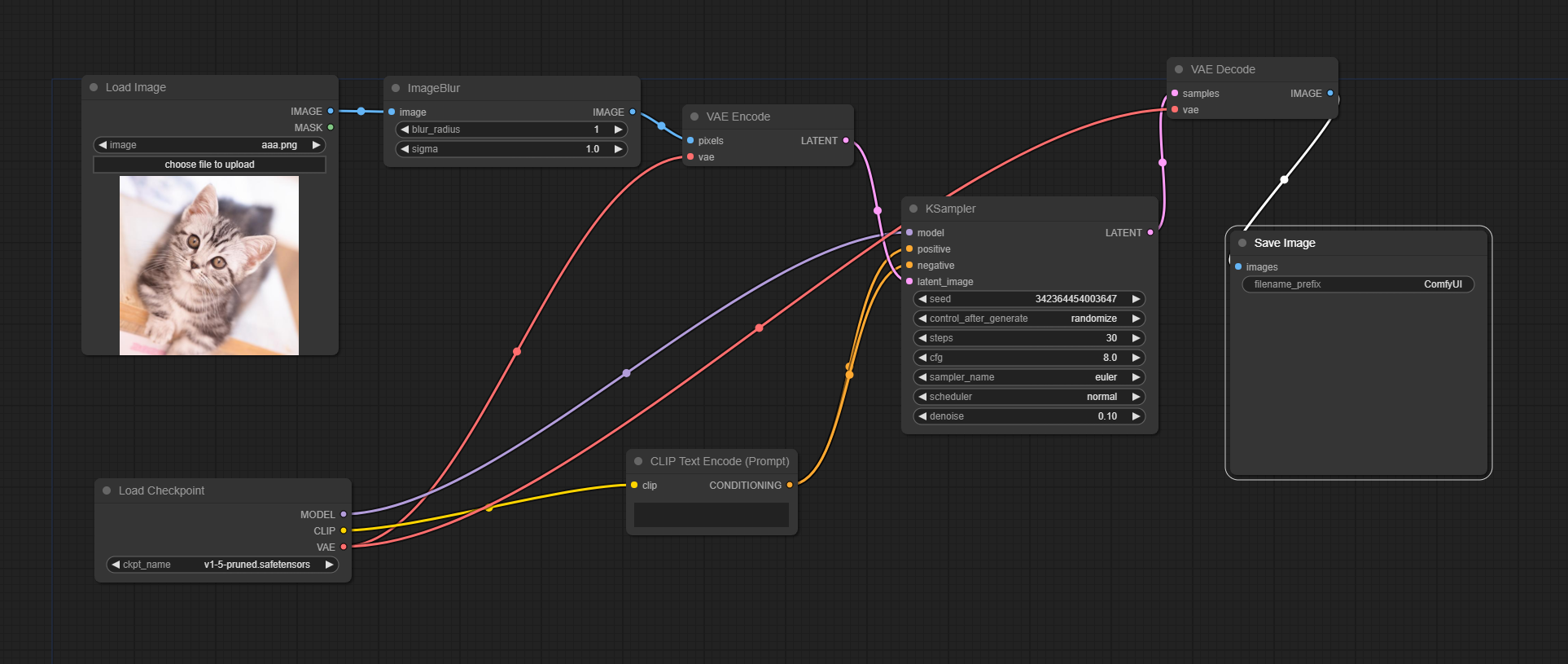
猫の画像はぱくたそ様からお借りしました。
うだうだしててもしょうがないので、早速結果です。
元画像(256KB):

結果(293KB):

増えた......だと!?
ってことでパラメータ変更。
ステップ数:30→5
結果(289KB):

毛先などに明らかな劣化が見られるレベルなのに、圧縮どころかサイズを増やしてしまった......
反省
「人生の旅路において、知識は心強い道案内人。その案内人を育てるのが勉強である。」
StableDiffusionで画像圧縮をしようとする先人が少なく、自分の知識という道案内人すらもいなかったことが敗因です。
勉強したらまた再挑戦します。