注意!! この記事は,github上の最新versionと大きく異なります.
目次
- wallprimeってなに?
- 使用したライブラリ、androidエミュレータ
- 画面の読み込み、画像のOCR
- 素因数分解の準備
- 素因数分解
- androidエミュレータに出力
- 工夫と改善点
- まとめ
- スコア
今回のコード
githubからダウンロードできます!
demo。gif変換の過程で再生速度が早くなっています。
wallprimeってなに?
wallprimeは表示される合成数を素因数分解していくゲームです。プレイしている動画。素因数は難易度ごとに決まっていて、場所も固定されています(固定させていたのが実装を楽にしてくれた)。難易度は簡単な順に、EASY,NORMAL,HARD,EXPERT,INSANEです。今回は、最高難易度のINSANEの自動化です。別の難易度に対応させるには、clickする座標を変更するだけです。
使用たライブラリ、androidエミュレータ
言語はもちろんPythonです。
Python 3.7.4
使用したライブラリは主に、
- PyAutoGui (画面の読み込み、自動click)
- PyOCR (数字の識別)
です。
ディレクトリ構成は、
wallprime
├── auto_click.py #クリックの自動化
├── get_number.py #ゲーム画面を撮影
├── read_num.py #get_number.pyで取得したゲーム画面の数字の識別
├── prime_solve.py #因数分解を解く
├── mode.py #難易度ごとの素因数(実質INSANE)のみ
├── image #get_number.pyの保存先
└── venv #いつもの。git cloneしてきたものには含まれていません。
となっています。
使用したandroidエミュレータは、BlueStacksです。メモリを大量に食います。私のmacだとファンがフル回転になりました。githubやこれから解説するコードに出てくる座標はエミュレータを左上、左端にくっつけた時の座標です。

エミュレータを左上、左端にくっつけた時
注意点:環境の問題でDockerと競合するため併用はできません。
画面の撮影、画像のOCR
まずは、ゲーム画面を撮影する方法から。
ゲーム画面を撮影するには、いくつか方法があると思いますが今回はPyAutoGuiのスクリーンショット機能を使います。macを使用している方は、アクセシビリティを要求されます。
# import
import pyautogui as auto
def get_number(path):
img = auto.screenshot(region=(180,370,420,400))
img.save(path)
auto.screenshot()でスクリーンショットを撮っています。()内はどの領域を撮るかのoptionです。
数字以外を入れるとOCR時にエラーが出る可能性があるので、領域を狭くしています。
ゲーム画面を撮ったら次はOCRです。
前述とおりOCRに使用するライブラリはPyOCRです。
# import
from PIL import Image,ImageOps,ImageFilter
import pyocr
import pyocr.builders
def read_num():
tools = pyocr.get_available_tools()
if len(tools) == 0:
print('No OCR tool found')
tool = tools[0]
img = 'image/prime.png'
img = Image.open(img).convert('RGB')
img_convert = ImageOps.invert(img) #白黒反転で精度向上
number = tool.image_to_string(
img_convert,
lang='eng',
builder = pyocr.builders.TextBuilder(tesseract_layout=7)
)
try:
int(number.replace(' ',''))
return(int(number.replace(' ','')))
except ValueError:
print(number)
return 'error'
そのまま画像を読み込ませると精度が悪かったので、白黒反転させています。
try文までは普通のOCRです。try以降は、OCRが数字以外を検出した時にerrorが出るのを防いでいます。また、replaceで返させる数字に空白が含まれないようにしています。後に書きますが、return 'error'させることで例外処理しています。二値化やぼかし等を試しましたが精度は上がりませんでした。精度は95%くらいです。

この画像をどうやっても$829374$だと認識してくれず、$329374$と言われました。Cloud Vision APIとか使えばできそうですが、今回は簡単にできることに重点を置いてるのであきらめてRetryしました。
教えて画像認識のプロ。
素因数分解の準備
# import
from mode import mode_choice
from get_number import get_number
from read_num import read_num
from auto_click import auto_click_insane
from time import sleep
import pyautogui as auto
# パラメータ
mode = 'insane'
auto.click(70,150) #最初に適当な場所をclickさせます。特に意味はない
path = 'image/prime.png' #スクリーンショットした画像を保存する場所を指定するpath
# solve
while True:
m = 0
error_counter = 0
while error_counter < 5:
img = get_number(path)
n = read_num()
if n == 'error':
error_counter += 1
print('error')
continue
else:
error_counter = 0
break
else:
print('please type number cannot read')
n = int(input())
error_counter = 0
print(n)
prime_f = mode_choice(mode)
cal = []
error_counter = 0
上の4つは自分で書いたスクリプトで、timeはclick間の時間を測ります。PyAutoGuiはclick処理を行ないます。
While Trueで無限ループにして処理を続行できるようにしています。
while error_counter < 5:
img = get_number(path)
n = read_num()
if n == 'error':
error_counter += 1
print('error')
continue
else:
error_counter = 0
break
get_number.pyで画像を撮って、そのあとにOCRしています。OCRのパートに書いたように数字以外を検知した場合に実行します。確認のためにprint(n)しています。
一回でも数字以外を検知したら無限にエラーが出ると思われるかも知れませんが、ゲームの演出で壁を破壊した時に出るブロックが数字と重なるタイミングでスクリーンショットを撮っていしまうことを回避しています。
こういった状態
else:
print('please type number cannot read')
n = int(input())
error_counter = 0
もしもエラーが5回以上になると手動で入力させます。
print(n)
prime_f = mode_choice(mode)
cal = []
error_counter = 0
OCRがしっかりと検知しているかを確認するためにprintしています。
prime_fは難易度ごとの素因数をlsitで取得します。
calという計算結果を収納する空のlistを作ります。
error_counterを初期化するのを忘れないようにしています。どっちみち、前のパートで初期化されているような気がしますが、念のため。
def mode_choice(mode):
if mode == 'easy':
return [2,3,5]
elif mode == 'normal':
return [2,3,5,7]
elif mode == 'hard':
return [2,3,5,7,11,13]
elif mode == 'expert':
return [2,3,5,7,11,13,17,19,23]
elif mode == 'insane':
return [2,3,5,7,11,13,17,19,23,29,31,37,41,43,47,53]
素因数分解
while n != 1:
for i in prime_f:
if n % i == 0:
cal.append(i)
n /= i
error_counter = 0
elif error_counter > 16:
break
else:
error_counter += 1
else:
continue
break
if error_counter > 16:
print('please type number read error')
n = int(input())
m += n
cal = []
error_counter = 0
while n != 1:
for i in prime_f:
if n % i == 0:
cal.append(i)
n /= i
error_counter = 0
elif error_counter > 16:
break
else:
error_counter += 1
else:
n = m
break
cal.sort()
素因数分解は、特にアルゴリズムは使わずにとりあえず割っていく手法を採用しています。合成数が競プロみたいに大きくないことと素因数が全て見えているので代入するだけの方が楽だと考えたからです。
ここで2つ目のエラー処理をします。OCRが正しく数字を認識した場合には、必ず手持ちの素因数で分解することが可能ですが、もしも誤検知していた場合には分解することができません。ですので、error_counterという変数で検知します。
誤検知していなければ必ず16種類の素因数で割れるはずなので閾値を16に設定して、16を越えた時は実行者に数字の入力を要求します。
追記 :アドバイスを貰ったので、jからiに変更しました。
androidエミュレータに出力
androidエミュレータに出力するために、PyAutoGuiを使います。
for s in range(len(cal)):
auto_click_insane(cal[s])
sleep(0.05) #遅延させないと入力できない
print(cal)
auto.click(300,600) #決定ボタンの座標
sleep(3.5)
単純にfor文を使って、calの要素を関数auto_click_insaneに入れてclickさせています。
コメントしているように、あえて遅延をはさんでいます。一瞬で入力しようとするとエミュレータがclickを認識してくれません。
最後のsleep(3.5)は次の問題までの待ち時間です。ここは難易度によって時間を待機時間を調整したほうが高スコアを取れると思います。
import pyautogui as auto
def auto_click_insane(cal):
if cal == 2:
auto.click(45,490)
elif cal == 3:
auto.click(100,490)
elif cal == 5:
auto.click(160,490)
elif cal == 7:
auto.click(210,490)
elif cal == 11:
auto.click(45,540)
elif cal == 13:
auto.click(100,540)
elif cal == 17:
auto.click(160,540)
elif cal == 19:
auto.click(210,540)
elif cal == 23:
auto.click(45,590)
elif cal == 29:
auto.click(100,590)
elif cal == 31:
auto.click(160,590)
elif cal == 37:
auto.click(210,590)
elif cal == 41:
auto.click(45,640)
elif cal == 43:
auto.click(100,640)
elif cal == 47:
auto.click(160,640)
elif cal == 53:
auto.click(210,640)
工夫と改善点
エラーの処理を分けるのに時間がかかりました。できるだけ自動化しようと努力しましたが、完全自動化はできませんでした。理由は、OCR部分の読み込みエラーは人間が介入しないと正しく読めないからです。OCRの精度が高くても100%ではないので必ず読み込みエラーはでます。回避する方法は、違うアルゴリズムのOCRを並べれば少しはマシになるかもしれません。今回は、時間がありませんでした。
clickのタイミングもうまく噛み合わずに最後の1が入力されずに手作業でclickするしかない状況がありました。
また、読み込みエラーした写真を別の場所に保存して、正しく学習できるようにするためのデータセットを作れるようにしたかったのですが上手にできなかったので、後でbranchにでも作ります。全難易度対応版も作ろうかな...
まとめ
こんなにエラーの処理を書いたのは初めてなので、breakやcountinueの使用を理解していないのでグダグダなコードになりました。また、2日で作ったということもあって精度が低かったり、エラーの処理がうまくいっていませんが、個人的には満足の結果でした。エラーや改善点があればコメントください。
スコア
最高スコアは、14556ptです。
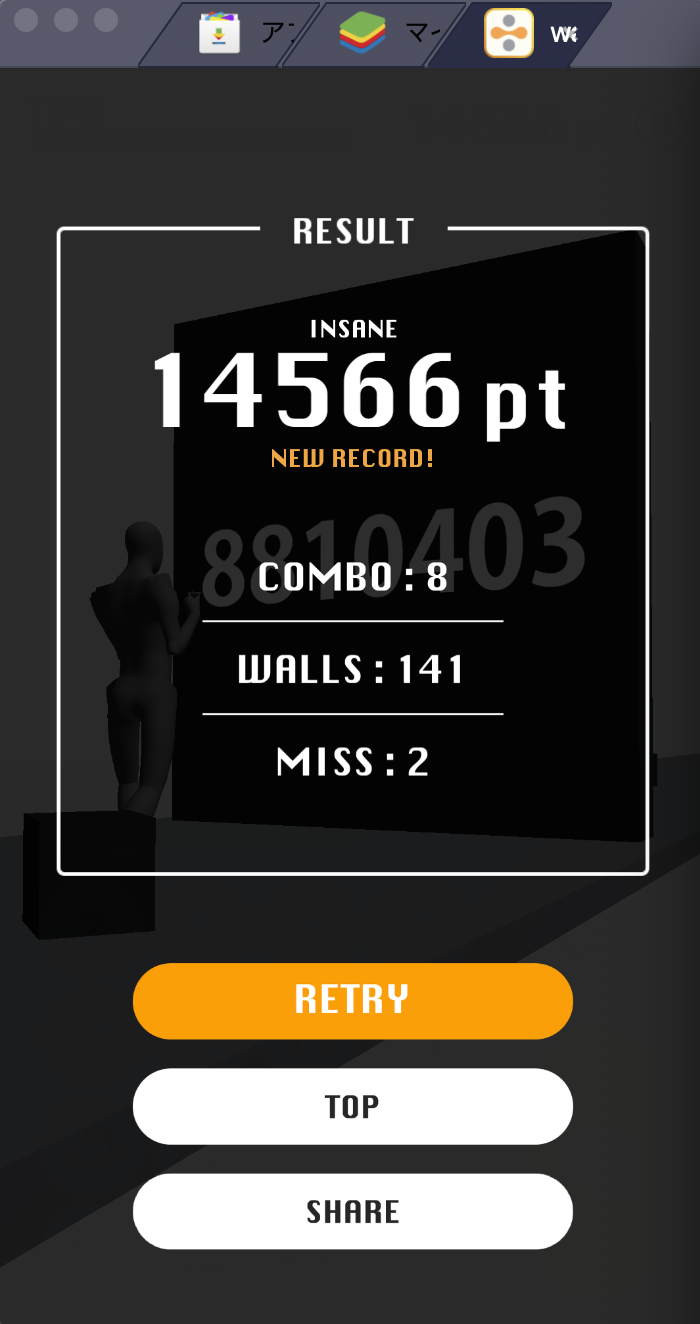
めざせ20000点