はじめに
Pythonを使った画像のハンドリングについての記事となります。
自分自身の勉強と知識の整理という目的で本記事を書きました。技術ブログ投稿は初なので、暖かい目でご容赦いただけると幸いです。
OpenCV3をインストール
以下の環境で行いました。
macOS 10.14.2
Python 3.6.5
anaconda3-5.2.0
Jupyter Notebook
(19/01/25 記載)
現状ですと、以下の通りにインストールすると、手取り早いようです。
$ pip install opencv-python
なお、pyenvによる仮想環境設定については、今回は割愛します。
OpenCV3の動作確認
まず、正しくOpenCV3がimportされているかどうかを確認します。
import numpy as np
import cv2, matplotlib
import matplotlib.pyplot as plt
print(cv2.__version__)
エラーが出ずversion表示されればOKです。
画像入力と画像表示
まず、今回はjupyterで動かしながら、画像の埋め込み表示を行います。matplotlibを使いますが、以下のおまじないを書きます。
%matplotlib inline
次に、画像分野で良く使われているlennaの画像をググって入手し、画像を読み込んで表示します。
RGBへの変換も必要です。
%matplotlib inline
def read_img(name_i):
img = cv2.imread(name_i)
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)
return img
# 画像の読み込み
img = read_img('lenna.png')
# 画像の表示
plt.imshow(img)

lennaさんが無事に表示されました。
顔認識と顔座標の検出
引数:画像ファイル名,顔認識の特徴量パス
返り値:画像ファイルから検出された顔画像の配列
で、以下の処理を行います。
・画像入力
・入力画像をグレー画像に変換
・顔認識実行。特徴量のpathを引数から入力。
・検出した顔を囲む矩形を作成し、1枚の画像ずつ、配列へ追加。
・画像に枠を枠を書く
・画像の表示
def detect_face(img_name , cascade_path):
#画像入力
img = read_img(img_name)
width = img.shape[1]
height = img.shape[0]
img = cv2.resize(img , (width , height))
#入力画像をグレー画像に変換
gry = cv2.cvtColor(img, cv2.COLOR_RGB2GRAY)
#顔認識実行。特徴量のpathを引数から入力。
cascade = cv2.CascadeClassifier(cascade_path)
#minNeighbors=20, minSize=(30, 30)→検出枠が近すぎるのと、小さすぎるのは間引く。
facerect = cascade.detectMultiScale(gry, scaleFactor=1.05, minNeighbors=20, minSize=(30, 30))
dst_img = []
if len(facerect) > 0:
color = (255, 0, 0)
for rect in facerect:
x = rect[0]
y = rect[1]
w = rect[2]
h = rect[3]
#検出した顔を囲む矩形を作成し、1枚の画像ずつ追加。
add_image = cv2.resize(img[y : y+h , x : x + w] , (64 , 64))
dst_img.append(add_image)
#画像に枠を枠を書く
cv2.rectangle(img, tuple(rect[0:2]),tuple(rect[0:2]+rect[2:4]), color, thickness=2)
# 画像の表示
plt.imshow(img)
return dst_img
以下、openCVであらかじめ持っている学習済み顔特徴量を指定し、実行。
cascade_path = '/usr/local/share/OpenCV/haarcascades/haarcascade_frontalface_default.xml'
res_images = detect_face("lenna.png" , cascade_path)
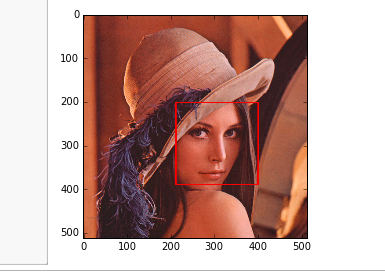
lennaさんの顔が赤い枠で囲まれました。
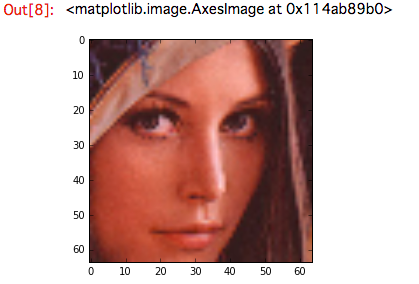
次に、顔検出の画像のみを表示します。今回は1画像から検出顔を1つなので、indexは0番目です。
plt.imshow(res_images[0])
1枚の画像から複数顔検出
1枚の画像から複数顔の検出を行う場合です。
画像の引用元は以下になります。
https://www.pakutaso.com/model.html
res_images = detect_face("sample.png" , cascade_path)

このような実行結果となりました。真正面でないと検出されないようです。
また、複数の画像を保持できているかの確認のため、0番目以外の画像で表示されるかを確認します。今回はindexが1で実行します。
plt.imshow(res_images[1])

ヒストグラム算出と基本的な統計量の算出
ごく基本な統計量に注目するということで、ヒストグラムを算出します。
# Green画素のみを抽出し、Green画像でヒストグラム算出
RGB =cv2.split(res_images[1])
Gr = RGB[1]
hist = cv2.calcHist([Gr],[0],None,[256],[0,256])
hist

配列でヒストグラムを持つことができます。
次にプロットします。
plt.plot(hist)
plt.xlim([0,256])
plt.show()
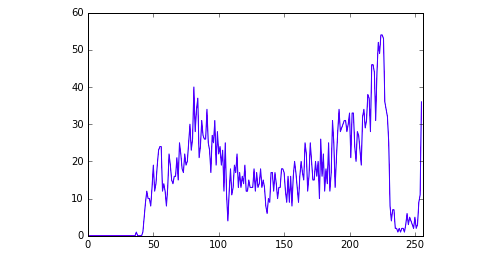
サチっているというか、明るめの画像なので、真面目に分析を行い際には、正規化も必要になるでしょう。
得られたヒストグラムに対して、基本的な統計量を見て見ます。
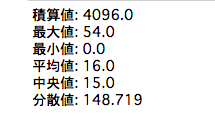
print("積算値:", np.sum(hist))
print("最大値:", np.max(hist))
print("最小値:", np.min(hist))
print("平均値:", np.mean(hist))
print("中央値:", np.median(hist))
print("分散値:", np.var(hist))
今回はここで終わりです
OpenCVのちょっとした動作確認も行いつつ、基本的な統計量を算出することまでできました。
統計量だけで考えなくても、世の中に画像特徴量の作成方法はたくさんあります。また、作成した特徴量に対してbag-of-featuresの形式にすれば、特徴量エンジニアリングを行ったことになり、機械学習実践の第一歩を踏み出せるかと思います。実務的なところは、また別の機会で紹介できたらと思います。