はじめに
2019/7/8に【Tech-on MeetUp#07「OpsとDevの蜜月な関係」】というイベントに参加しました。
発表資料へのリンクとイベントに参加した際の自分のメモとtwitterのつぶやきをまとめてみました。
イベントのページはこちら
twitterはこちら:#TechOn東京
発表1:「Ops meets NoOps ~そのとき何が起こったか~」
日本マイクロソフトの真壁 徹さんの発表
基本的にインフラの方。ちょっとアプリもかじっているらしい。
NoOps Japan Community のサポーターをしている方です。
NoOps Japan Community はこちら
・connpass:https://noops.connpass.com/
・twitter:https://twitter.com/NoOpsJapan
・GitHub:https://github.com/noopsjapan
資料
内容
NoOpsとは?

資料より抜粋
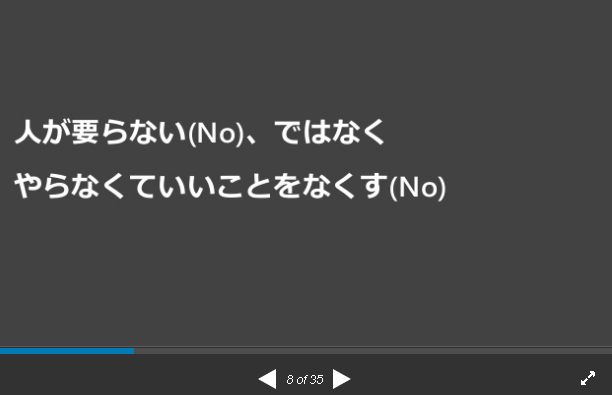
資料より抜粋

資料より抜粋
退役←ここが重要
・どのくらいのユーザーが使っているのか
・ビジネス効果は?
これらを鑑みて今やっていることを続けていく必要があるかどうかを考えてみる。
今やっていることをやりながら新しいことができるのか?
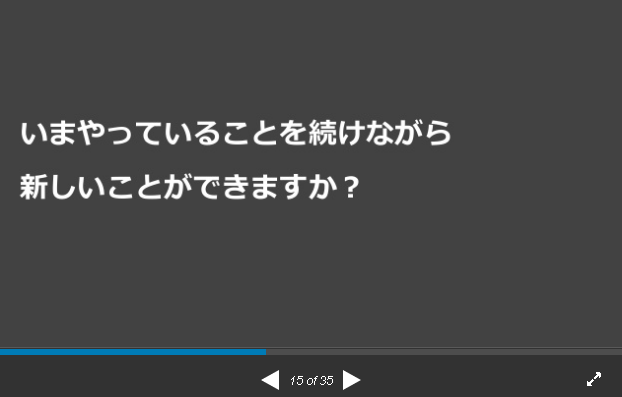
資料より抜粋

資料より抜粋
作ることは誰にでもできる。難しいのは偉い人が「やめる判断」をするところ 。
いまやっていることを「やめよう」と胸を張って言える組織ですか?もう必要ないのではないか?
技術や組織はどんどん新しくなっている。
システム放っておいても複雑化し、やがて腐る。
やめる判断は、意思決定の権限がある人の大事な仕事。
意思決定者がNoOpsの文脈でつくる話に終始するのは危険信号。
古いシステムをやめて、空いた人手・空いた時間でこういう新しいシステムを作っていこう!・・・と言えることが大事。
前向きに「やめよう」という組織、学ぶ文化が大事。
ポジティブにやめる力。
どうやって軌道に乗せるか

資料より抜粋
やめるものをやめて時間ができた。
いきなりドリームチームは作れない。
能力よりも意欲が大事。
パッションのある人が始めて、持続して組織内に広めていく。
何処から着手する?
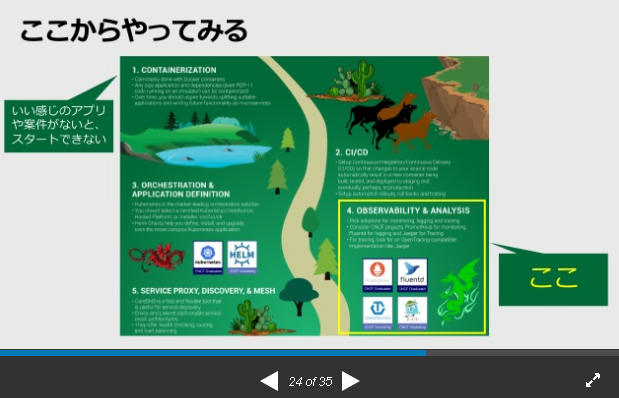
資料より抜粋
何処から着手するかを決めきれないなら、
⇒Cloud Native Trail Map
Cloud Native を目指すときにどこから始めたらいいかを示したもの。
発表者的には、Opsは「4.OBSERVABILITY & ANALYSIS」から始めたほうが良いと思っている。
1.CONTAINERIZATION
⇒いい感じのアプリや案件がないと、スタートできない
4.監視と分析
⇒Opsならここから

資料より抜粋
なぜObservability(可観測性)から始めた方が良いか?
IaCから入る人が多いが、、、
プロビジョニングの自動化って、本当に効果ある?失敗した時のリスクが大きい。
監視から始める方がやりやすいし効果も出やすい。
監視が不要な組織はない。
変えても、止まってもユーザー影響は少ない。
⇒監視システムをOpsの道場にする。
・監視システムをNoOpsコンセプトで作る
・OSSやSaaSをベースに小さく初めて「育てる」
監視システムを自分で作り、知見をためてビジネスアプリケーションへ展開していく。
SLI(Service Level Indicator)を議論しよう。

資料より抜粋
SREのR(Reliability)は曖昧。
SLI(Service Level Indicator)を議論しよう。
ビジネスを支える仕組みが健全かどうかの指標。
PO含めて議論するのが大事。POやDevと議論する。
運用・監視を雰囲気で、何となくでやっていることがある。
雰囲気で合意せずにやってしまっている。
雰囲気でやっていることには予算がつかない。
数値化されてないと評価されない。投資してもらうには評価の基準が必要。
SLIはNoOps活動の投資判断や評価の指標。

資料より抜粋
SLI/SLOを考える時
ビジネスオーナーから見たら、高いほうが良い。
「適切なレベルの信頼性 - Microsoft Lean」
レベルは、ビジネスニーズに合致し、実用的である必要があります
本当にそれだけのAvailability, Reliabilityは必要なのか?を表した文章。
100%を顧客に要求されたらこの文章をそのままぶつけても良い。

資料より抜粋
共有指標があってこそのチームワーク
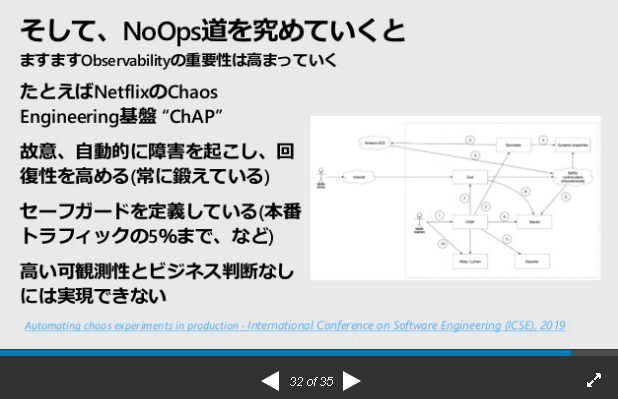
資料より抜粋
Chaos engineering基板 CHAP
「本番トラフィックの5%まで」とあるが、きっちり観測しないとできない。
それができるビジネス判断ができることが大切。
まとめ

資料より抜粋
技術よりも・・・
・組織文化
・パッションを持ったメンバー
が大事。
組織文化
「やめよう!」が言えること。
その際、今までありがとう、でも今は機能してないからこれはやめよう。という意識。常にリスペクトをもって。
無駄をなくせる人、違う仕組みを作れる人にはどんどん仕事が来る。NoOpsでも仕事がなくなることはない。
発表2:「チーム開発におけるDevとOpsのプラクティス」
KDDIの廣田 翼さんの発表
インフラ寄りの方
資料
内容
チーム開発=スクラム開発を前提とした発表です。
チーム開発と運用の課題

資料より抜粋
開発(スクラム)と運用(複数件運用)とでゴールが違う

資料より抜粋

資料より抜粋
【課題】
スクラム開発と複数件運用でゴールが違う
監視もリリースも自動化したい
統合システムに沿ってほしい
チーム外の意見は後回しにせざるを得ない
どうしたら運用観点を早く注入できる
【解決策】
・スクラムチーム(開発チーム)に運用観点がある人(運用するキーマン)を入れる←ここ大事
・最初から非機能要件の優先度をPOやチームと調整する
(開発チームと運用チーム、ビジネスオーナーで観点違うのは当然だからチームにすべき)
・運用も開発チームの一員となり、サービスをより良くするためのゴールを統一する。
・ユーザーストーリーに運用観点を入れる。
・週1くらいの定例会で運用チームから刺さることもあるが、これではバックログの優先度を上げられない。
・運用もサービスをより良くする観点を持つ。
・OpsメンバーもDevチームに入り、サービスを良くするために同じゴールを見る。Opsもユーザー目線からシステムを見れるべき
開発と運用とでシステムの考え方にギャップがある

資料より抜粋
考え方のギャップ
メンテしにくい
zabbixの設定は、設定した人以外にはわかり辛いものになりがち。
監視設定書などで引き継ぐと抜けがないか心配になる。
本来、開発チームが作ったものをすぐリリースしたい。
⇒承認フローがネックになる。通すためにサラリーマンスキルが必要になる。
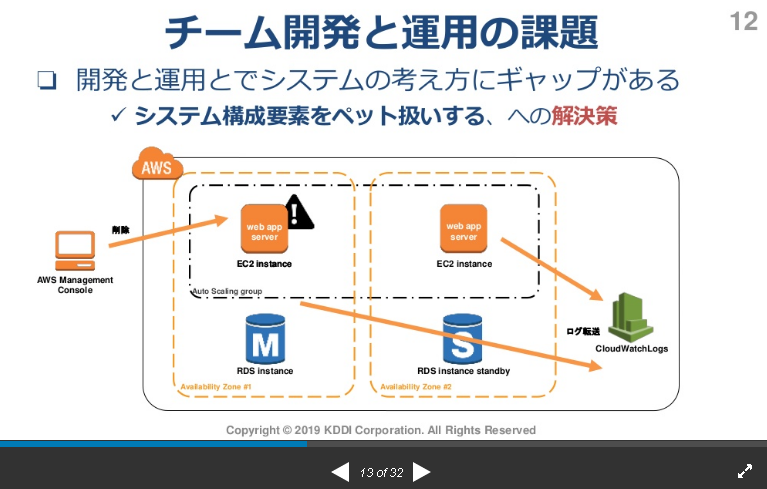
資料より抜粋
ペットとして扱う。
オンプレに名前を付けたりする(惑星の名前とか)
クラウドだとペットじゃなくて家畜のように扱う。
⇒EC2に障害が起きたら削除する。
AutoScaleで自動復旧する。
ベンダー呼んで修理とか、SSHで入ってうんぬん・・・なんてことはやらない。
クラウドは家畜。落ちたらすぐに次立ち上げる
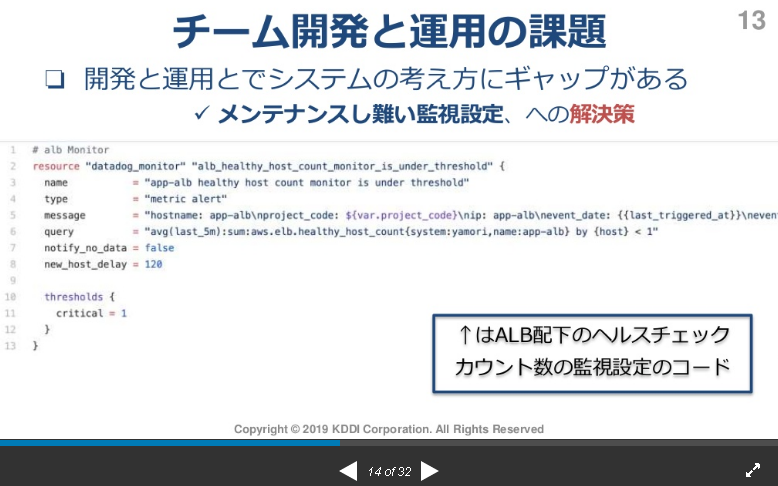
資料より抜粋
メンテしにくい監視設定
監視設定をコード化した(IaC)&CI/CD
どんな変更かをみんなで確認しやすい。
メンテナンスし難い監視設定への解決策。
DataDog x terraformで実現。
現代のシステムは分散化され複雑である

資料より抜粋
分散化されて複雑。

資料より抜粋
新しいAWS機能ができたら入れ替わったり増えたりする。
これらの変化に運用方法も追随して変化すべき。
現代のシステムは分散化され複雑
機能や連携先が増減すると、システムの構成要素も変化
⇒各コンポーネント障害の影響範囲がわからない
ユーザアクセスの傾向も時期によって変化
⇒サービスイン前に重厚なテスト
傾向が変わったら意味がないかもしれない
システムは変化するべき、運用も変化するべき
⇒継続的に運用方法を見直すことが必要
継続的障害訓練

資料より抜粋
Chaos Engineering
※これは本の表紙の色違うから別の本??わからん。。。
継続的障害訓練:連絡フローなど込みの継続的な障害訓練。
KDDIでは、商用と同じ構成のステージング環境で ChaosEngineering を行い、システムの弱点を把握、対策。ステークホルダを集めて継続的障害訓練を行っている。POとかも含める。
障害はプラットフォームからサーバ、NW、DBと全域に対して発生させたい。
障害はGUIで発生させて、状況を可視化したい。
障害パターンを記憶して、再現。

資料より抜粋
Gremlin:https://www.gremlin.com/
CNCFのプロジェクト。
https://landscape.cncf.io/selected=gremlin
Gremlin で障害を任意に発生させ強力なシステムを作る。
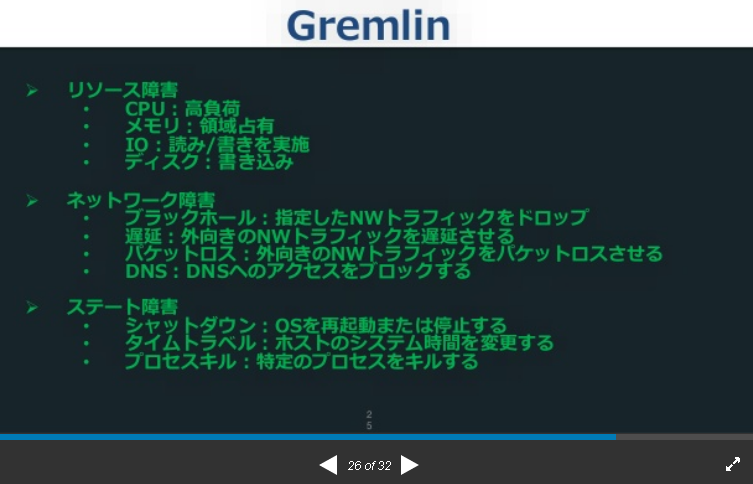
資料より抜粋
Gremlin
SaaS
できる障害
- リソース障害
- ネットワーク障害
⇒遅延の指定なども
- ステート障害
⇒NTPの同期をずらすなども

資料より抜粋
障害訓練の内容
メモリ高負荷、時刻同期解除、DBアクセス遅延
AWSリソースアクセス / 外部システムアクセス / 内部間アクセスを 70%低下
⇒障害対応者には何の障害を起こすかは伝えずに実施する。

資料より抜粋
障害訓練の効果
コンポーネント障害時のユーザ影響がわかる
障害手順を修正、改善
システムを改善できる機会が生まれる
まとめ
運用要件もチームでユーザーストーリーを作っていこう。
運用方法をチームで作る。
LT1. SRE はじめの一歩
JX通信社の平瀬 達也(たっち)さんの発表
資料
SREがわからん人はこの本を読もう。
(これは発表関係なく私個人の意見です)
LT2. Slackによるインシデント対応
コネヒトの金城 秀樹さんの発表
資料
LT3. MLOps
日本マイクロソフトの中村 憲一郎さんの発表
資料
公開待ち
LT4. Microservice x ScrumなBtoB_Webアプリケーション開発現場のOps話
CyberAgentの小西 宏樹さんの発表
資料
LT5. ZOZOTOWNを支えるチーム運用について
ZOZOテクノロジーズの鶴見 純一さんの発表
資料
他の方のブログなど
・2019-07-08 Tech-on MeetUp#07「OpsとDevの蜜月な関係」 #TechOn東京
https://note.mu/suwash/n/nb9554de8a610
・理解できる内容がたとえ1割未満でも - TechOn MeetUpにいってきました #TechOn東京
https://blog.onpu-tamago.net/entry/2019/07/09/113350
・togetter
https://togetter.com/li/1374311
その他イベントレポートなど
2019/07/27追加
主催グループのイベントレポート
Tech-on MeetUp#07「OpsとDevの蜜月な関係」
https://tech-on.org/report-meetup07/