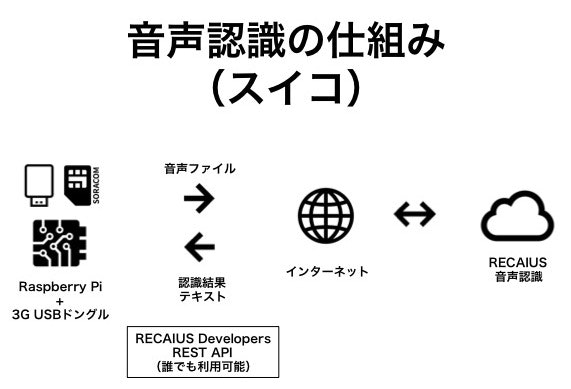
スマホやパソコンだけでなく、IoTデバイスでもクラウドサービスの音声認識使ってみたいよね、ってことで『早口言葉の練習』をお題にして、Raspberry Piで音声認識をやってみた。
音声認識は、APIで使えるクラウドサービスRECAIUS、通信は、WiFi環境がなくても使えるSORACOMを使った。
環境
- Raspberry Pi 2 Model B + LCDディスプレイ( KOOKYE LCD touch screen )
- Python, Requests, PyAudio, Tkinter
- 3G USBドングル ( AK-020 ) + SORACOM SIM
- USBマイク ( MM-MCUSB16 )
- USBマウス

音声認識はRECAIUS
RECAIUS Developersのサイトでユーザ登録するとAPIが翌月末まで使えるIDとパスワードが発行されるので、それを使う(繰り返し登録することで延長可)。
https://developer.recaius.io
通信はSORACOM
RECAIUSはクラウドで音声認識するので、Raspberry Piで録音した音声ファイルを送ると、認識した結果がテキストで帰ってくる。
今回は、WiFi環境がなくても使えるように、SORACOMを使った。
実行スクリプト
以下の2つのスクリプトをデスクトップに用意しておき、順に実行する(アイコンを右クリックして"開く")。
- connect_air.sh : SORACOM接続実行スクリプト
- suiko.sh : 早口言葉練習「スイコ」実行スクリプト

# !/bin/sh
sudo /usr/local/sbin/connect_air.sh
/usr/local/sbin/connect_air.shは、SORACOM公式のやり方
各種デバイスで SORACOM Air を使用する
でget。
# !/bin/sh
cd /home/pi/recaius/python-recaius
./suiko.py
suiko.pyの中身は後述。
動作
-
suiko.shを実行するとGUIが立ち上がる
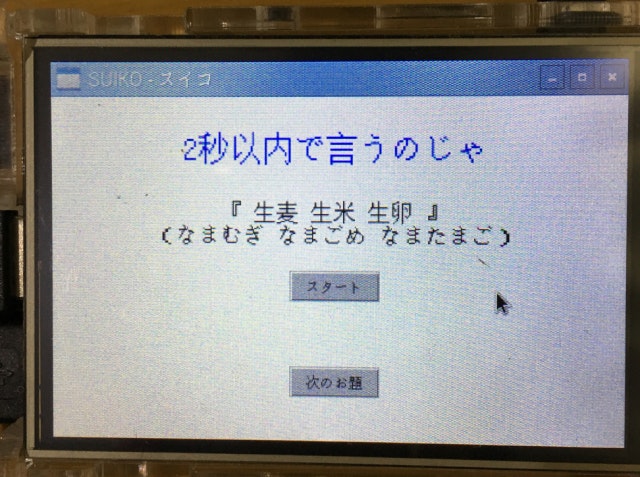
- スタートボタンをクリックすると録音開始し、2秒後に録音停止する
- この2秒間でお題の早口言葉を言う!
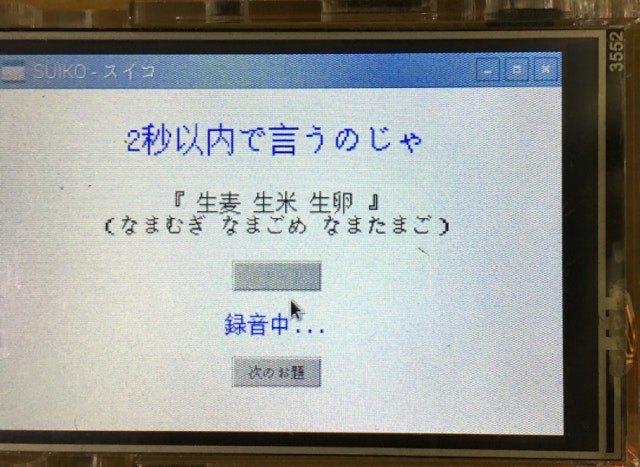
- 録音停止後、RECAIUSにSORACOM経由で音声ファイルを送信する
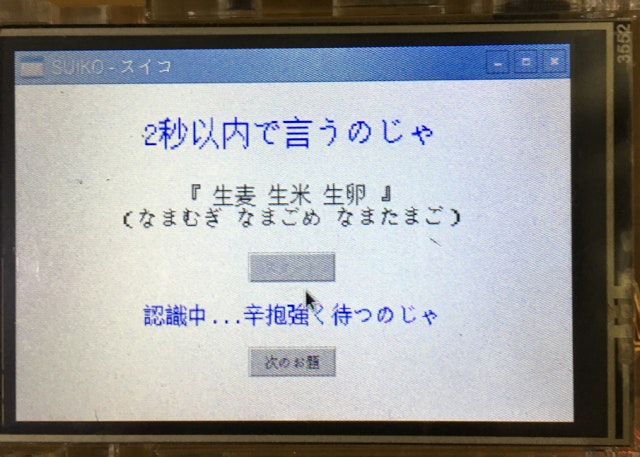
- 音声認識されたテキストファイルを受信して表示する(赤字のところ)
- 早口言葉が正しく言えてたら(認識されていたら)お題と同じになる!
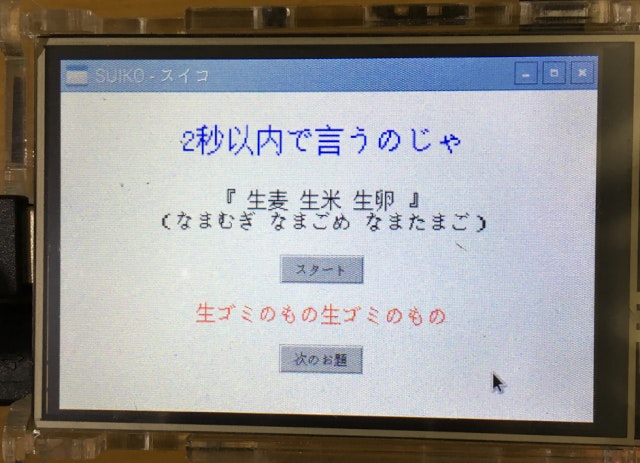
ぜんぜん言えてない・・・
コード
# !/usr/bin/env python
# -*- coding: utf-8 -*-
from recaius.asr import RecaiusASR
from settings import ASR_ID, ASR_PASSWORD
import pyaudio
import wave
import sys
import Tkinter
import threading
def ClickStart(event):
Button1.configure(state=u'disabled')
Label4.configure(fg='blue', text=u'録音中...')
Label4.pack()
t_recording = threading.Thread(target=Recording)
t_recording.start()
def Recording():
CHUNK = 4096
FORMAT = pyaudio.paInt16 #
CHANNELS = 1 #
RATE = 16000 #
RECORD_SECONDS = 2 #
WAVE_OUTPUT_FILENAME = "output.wav"
p = pyaudio.PyAudio()
stream = p.open(format=FORMAT,
channels=CHANNELS,
rate=RATE,
input=True,
frames_per_buffer=CHUNK)
print("* recording")
frames = []
for i in range(0, int(RATE / CHUNK * RECORD_SECONDS)):
data = stream.read(CHUNK)
frames.append(data)
print("* done recording")
stream.stop_stream()
stream.close()
p.terminate()
print("* transrating")
wf = wave.open(WAVE_OUTPUT_FILENAME, 'wb')
wf.setnchannels(CHANNELS)
wf.setsampwidth(p.get_sample_size(FORMAT))
wf.setframerate(RATE)
wf.writeframes(b''.join(frames))
wf.close()
print("* done transrating")
Label4.configure(fg='blue', text=u'認識中...辛抱強く待つのじゃ')
Label4.pack()
t_recognition = threading.Thread(target=Recognition)
t_recognition.start()
def Recognition():
rec = RecaiusASR(ASR_ID, ASR_PASSWORD)
rec.set_lang('ja_JP')
uuid = rec.login()
# speech recognition from wave file
result = rec.recognize(uuid, 'output.wav')
rec.logout(uuid)
print(result)
if(result == ''):
Label4.configure(fg='red', text=u'??? 認識できませんでした')
Label4.pack()
else:
Label4.configure(fg='red', text=result)
Label4.pack()
Button1.configure(state=u'normal')
def ClickNext(event):
global index
index += 1
index = index % 11
if index == 0:
Label2.configure(text=u'『 生麦 生米 生卵 』\n(なまむぎ なまごめ なまたまご)\n')
Label2.pack()
elif index == 1:
Label2.configure(text=u'『 東京特許許可局 』\n(とうきょうとっきょ きょかきょく)\n')
Label2.pack()
elif index == 2:
Label2.configure(text=u'『 青巻紙 赤巻紙 黄巻紙 』\n(あおまきがみ あかまきがみ きまきがみ)\n')
Label2.pack()
elif index == 3:
Label2.configure(text=u'『 隣の客は よく柿食う 客だ 』\n(となりのきゃくは よくかきくう きゃくだ)\n')
Label2.pack()
elif index == 4:
Label2.configure(text=u'『 庭には 二羽 鶏がいた 』\n(にわには にわ にわとりがいた)\n')
Label2.pack()
elif index == 5:
Label2.configure(text=u'『 ジャズシャンソン歌手 』\n(じゃず しゃんそん かしゅ)\n')
Label2.pack()
elif index == 6:
Label2.configure(text=u'『 新春シャンソンショー 』\n(しんしゅん しゃんそん しょー)\n')
Label2.pack()
elif index == 7:
Label2.configure(text=u'『 除雪車除雪作業中 』\n(じょせつしゃ じょせつ さぎょうちゅう)\n')
Label2.pack()
elif index == 8:
Label2.configure(text=u'『 李も桃も桃のうち 』\n(すももも ももも もものうち)\n')
Label2.pack()
elif index == 9:
Label2.configure(text=u'『 竹藪に 竹立てかけた 』\n(たけやぶに たけ たてかけた)\n')
Label2.pack()
elif index == 10:
Label2.configure(text=u'『 坊主が 屏風に 上手に 坊主の絵を描いた 』\n(ぼうずが びょうぶに じょうずに ぼうずのえをかいた)\n')
Label2.pack()
Label4.configure(text=u'')
Label4.pack()
root = Tkinter.Tk()
root.title(u"SUIKO - スイコ")
root.geometry("{0}x{1}+0+0".format(root.winfo_screenwidth(), root.winfo_screenheight()))
root.configure(bg=u"White")
# root.overrideredirect(True)
Label1 = Tkinter.Label(fg='Blue', font=('FixedSys', '20'), text=u'\n2秒以内で言うのじゃ\n')
Label1.configure(bg=u"White")
Label1.pack()
# お題
index = 0
Label2 = Tkinter.Label(text=u'『 生麦 生米 生卵 』\n(なまむぎ なまごめ なまたまご)\n')
Label2.configure(font=('FixedSys', '14'))
Label2.configure(bg=u'White')
Label2.pack()
Button1 = Tkinter.Button(text=u'スタート')
Button1.bind("<Button-1>",ClickStart)
Button1.pack()
# 空行
Label3 = Tkinter.Label(text=u'')
Label3.configure(bg=u"White")
Label3.pack()
# 結果
Label4 = Tkinter.Label(text=u'')
Label4.configure(font=('FixedSys', '14'))
Label4.configure(bg=u"White")
Label4.pack()
# 空行
Label5 = Tkinter.Label(text=u'')
Label5.configure(bg=u"White")
Label5.pack()
Button2 = Tkinter.Button(text=u'次のお題')
Button2.bind("<Button-1>",ClickNext)
Button2.pack()
root.mainloop()
-
RECAIUS APIのPythonラッパーは、以下を参考にさせていただきました
Python wrapper for RECAIUS API -
PyAudio(マイク入力から音声ファイルへの変換)は、以下を参考にさせていただきました
Pythonでマイクからの音を録音(pyaudio使用) – あかさたな
PyAudioの基本メモ2 音声入出力 - たけし備忘録 -
USBマイクの設定は、以下を参考にさせていただきました
簡単にできる!音声認識と音声合成を使ってRaspberrypiと会話 - Qiita
Raspberry Piで音声認識 - Qiita -
GUI(Tkinter)は、以下を参考にさせていただきました
PythonのTkinterを使ってみる - Qiita
Maker Faire Tokyo 2016で展示した

現状では、結果が表示されるまでに、10秒程度かかってしまう。
音声ファイルへの変換、音声ファイルの送信に時間がかかっている。
2秒間の録音後、音声ファイルへの変換を開始、変換完了後に送信を開始しているので、これを数ミリ秒区切りで、マルチスレッドで実行できるようにすれば、もう少し速くなるかもしれない。
ローカルで音声認識するリソースがなかったり、頻繁に音声認識を使わず、結果の表示までの時間をうまく隠せる使い方があれば、今回つくったような音声認識の環境が使えそう。