SVM についてまとめてみました。
最近の自分の中ので決めていることがあって、「とにかくOutputしまくる」ということです。
ってことでSVMについてOutputしていきたいと思います!
(今回は数式は省いています)
~Output 第1弾 SVM~
1. SVMとはなんや?
**SVM(Support Vector Machine)**とは、パターン認識手法です。
パターン認識とは、一定の規則や意味を持つ対象を選んで取り出すようなイメージ。
(分類、回帰の両方に利用可能な教師あり学習)
基本的に2値分類を考えて
クラスAとクラスBの間を直線(平面、超平面)で区切っちゃおう。って考えます。
以下の画像をみてください。
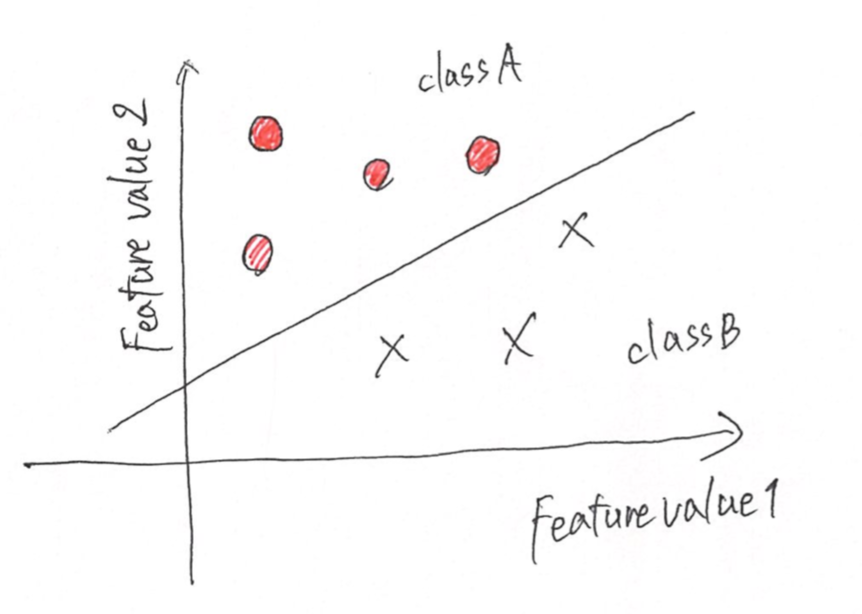
そしてこの線を基準としてできるだけ太い道を通すことが目的です。
この2つのクラスの間に出来るだけ太い道を通すんです。
この画像は、直線ですが、、、(笑)
この記事を読み進めればわかってくると思います!
この太い道を通す際にマージン最大化という考え方を使います。
マージン最大化 - ふたつのクラスに分ける決定境界の間にできる限り大きいマージンを確保します。
後ほど説明します。
+α
一般的に2次元のものを直線を引いて2クラスに分けます。
では、直線で分けれない時(線形分離不可能)はどうすれば良いでしょうか?
その時は、カーネルトリックというものを使います。
カーネルトリックにより「非線形変換を施した上で、より高次元特徴空間に写像」します。
分類・回帰について
カテゴリ予想→分類
数値データ予想→回帰
みたいな覚え方でいいと思います。
2. サポートベクトル
SVMについて調べているとサポートベクトルという言葉をよくみますよね。
では、サポートベクトルってなんなんだって事になりますよね。
サポートベクトルとは、、、
「SVMを訓練した後に" 道 "の中に入るインスタンス」のこと。
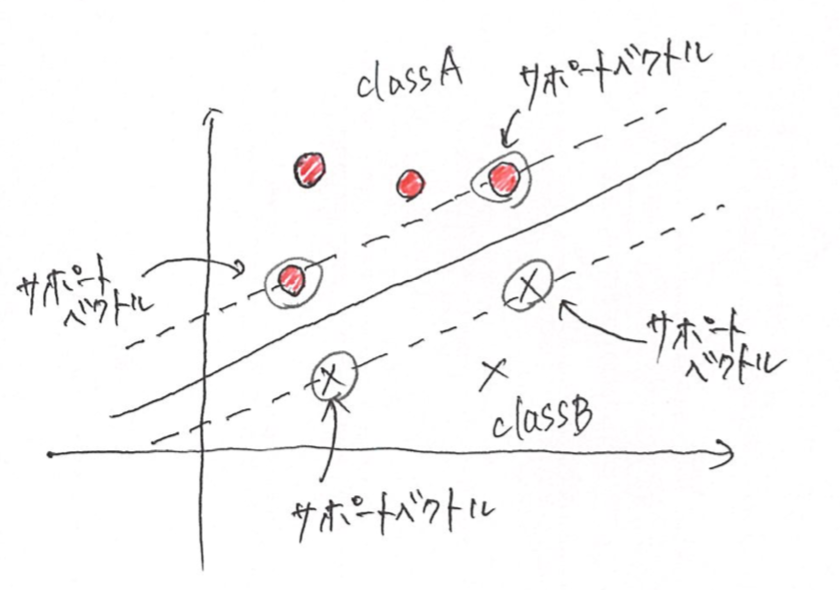
そして重要なことは、
サポートベクトルではないインスタンスは影響を持たない。
そのような影響を持たないインスタンスを追加、削除しても決定境界は変わらない。
予測の計算に使われるのは、サポートベクトルだけです!
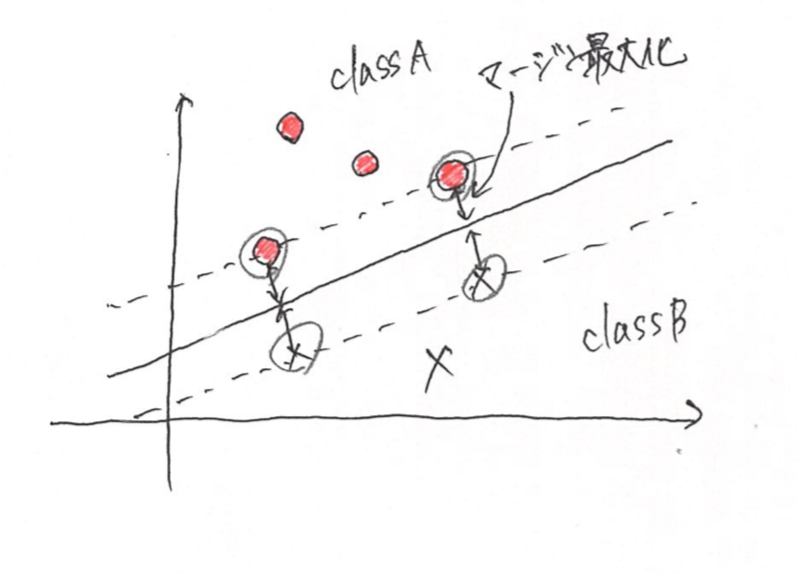
3. マージン最大化
マージンとは、判別する境界とデータとの距離です。
つまり、マージン最大化とはこの距離を最大化することです。
この距離が大きければ、少しデータが変わった時に誤判定する確率が下がります。
4. カーネルトリック
線形分離不可能の問題を解く時には、カーネルトリックという方法を使う。
「非線形変換を施した上で、より高次元特徴空間に写像」して、超平面で分離できるようにする。
⇒線形カーネル
(訓練セットが大きい、特徴量が大きい)
⇒ガウスRBFカーネル
(訓練セットがそれほど大きくない)
など。詳しくは検索してみてください。
5. SVMのメリットとデメリット
メリット
⇒ サポートベクトルでトレーニングを行うのでメモリ効率が高い
⇒ 高次元空間で有効
⇒ 多次元空間に写像するカーネル関数を色々変えることができる。
⇒ 平均や分散を使わない→新しいデータが追加されても全体の計算は不要
デメリット
⇒ SVMは境界面を設定するものなので、確率は残念ながら計算してくれません。ですので、訓練データを分けて汎化性能(Generalization Performance)を確かめることが重要!(Cross Validation)
⇒ 多クラス分類をやろうとすると必要になる分類器が増えるため、計算量が多くなる。
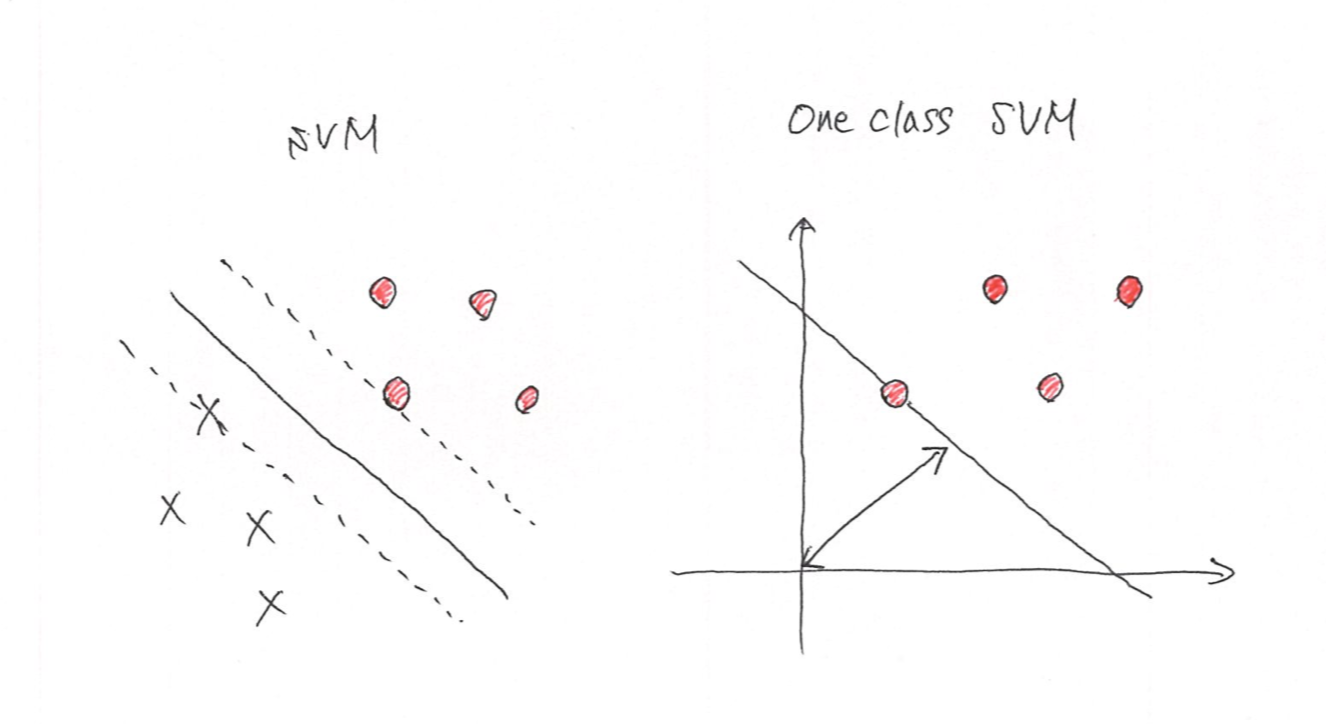
6. One Class SVM
異常検知の手法として、One Class SVM はよく使われます。
正常である大量のデータで学習を行って、未知のデータが正常か異常か判定するものです。
SVMは教師あり学習なのに対して、One Class SVMは教師なし学習
sklearn ではsvm.OneClassSVM()で使用できます。
SVMとの違いとしては、SVMでは、正例と負例のマージンを最大化するように境界面を決定する。
One class SVMは、原点と正常なデータのマージンを最大化するように境界面を決定する。
7. iris dataset を用いた SVM の実装
ここからは、実際のデータを使用してSVMについて考えていきたいと思います。
iris dataset は、“setosa”, “versicolor”, “virginica” の 3 種類の品種のアヤメのデータです。今回は、この3種の分類を行ってみたいと思います。
ちなみに、カラム数は4つで以下のようになっています。
sepal length (cm) がく片の長さ
sepal width (cm) がく片の幅
petal length (cm) 花弁の長さ
petal width (cm) 花弁の幅
import文とデータの読み込み
import numpy as np
import matplotlib.pyplot as plt
from mlxtend.plotting import plot_decision_regions
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
from sklearn.svm import SVC
plt.style.use('ggplot')
from sklearn.datasets import load_iris
iris = load_iris()
データの前処理
3,4番目のデータのみ学習に使用。
3. petal length (cm) 花弁の長さ
4. petal width (cm) 花弁の幅
X = iris.data[:,[2,3]]
y = iris.target
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=None )
# 標準化処理
sc = StandardScaler()
sc.fit(X_train)
X_train_std = sc.transform(X_train)
X_test_std = sc.transform(X_test)
標準化というスケーリング手法をしています。
スケーリング手法は、
⇒ 正規化 : [0~1]の間に収まるようにする MinMaxScaler()
⇒ 標準化 : 平均が0, 標準偏差=1の分布にする。StandardScaler()(新しくデータ作成)
Q.なんでスケーリングとかすんの?しなくて良くね?
Answer : 特徴量間で異なるスケール(その単位と値の範囲が異なる)のデータセットをモデルで学習させると、うまく学習できないから!! (ex. 身長と体重、家の値段と部屋数)
Q. どういうデータに対してどの手法を使うか?
正規化 ・画像処理におけるRGBの強さ[0,255]、sigmoid,tanhなどの活性化関数を用いるNN
標準化 ・ロジスティック回帰、SVM、NN、KNN、K-means
使わない ・決定木、ランダムフォレスト
モデルの作成・学習
model = SVC(kernel='rbf', C=0.5, gamma=0.5, random_state=None)
model.fit(X_train_std, y_train)
SVC(C=1.0, kernel=’rbf’, degree=3, gamma=’auto_deprecated’, coef0=0.0, shrinking=True, probability=False, tol=0.001, cache_size=200, class_weight=None, verbose=False, max_iter=-1, decision_function_shape=’ovr’, random_state=None)
⇒ kernelのデフォはrbfで指定可能なのがlinear, poly, rbf, sigmoid, precomputed
⇒ Cはコストパラメータといわれるもので、小さいと誤分類を許す。大きいと誤分類を許さない。
⇒ gammaは、rbfカーネルのパラメータで小さいと単純な決定境界となり、大きいと複雑な決定境界になる。つまり、個々の訓練データをどれだけ重視するかと考えればいいのかなあ。
精度の確認
predicted_train = model.predict(X_train_std)
accuracy_train = accuracy_score(y_train, predicted_train)
print('Training accuracy: %.2f' % accuracy_train)
predicted_test = model.predict(X_test_std)
accuracy_test = accuracy_score(y_test, predicted_test)
print('Test accuracy: %.2f' % accuracy_test)
実行結果
Training accuracy: 0.95
Test accuracy: 0.98
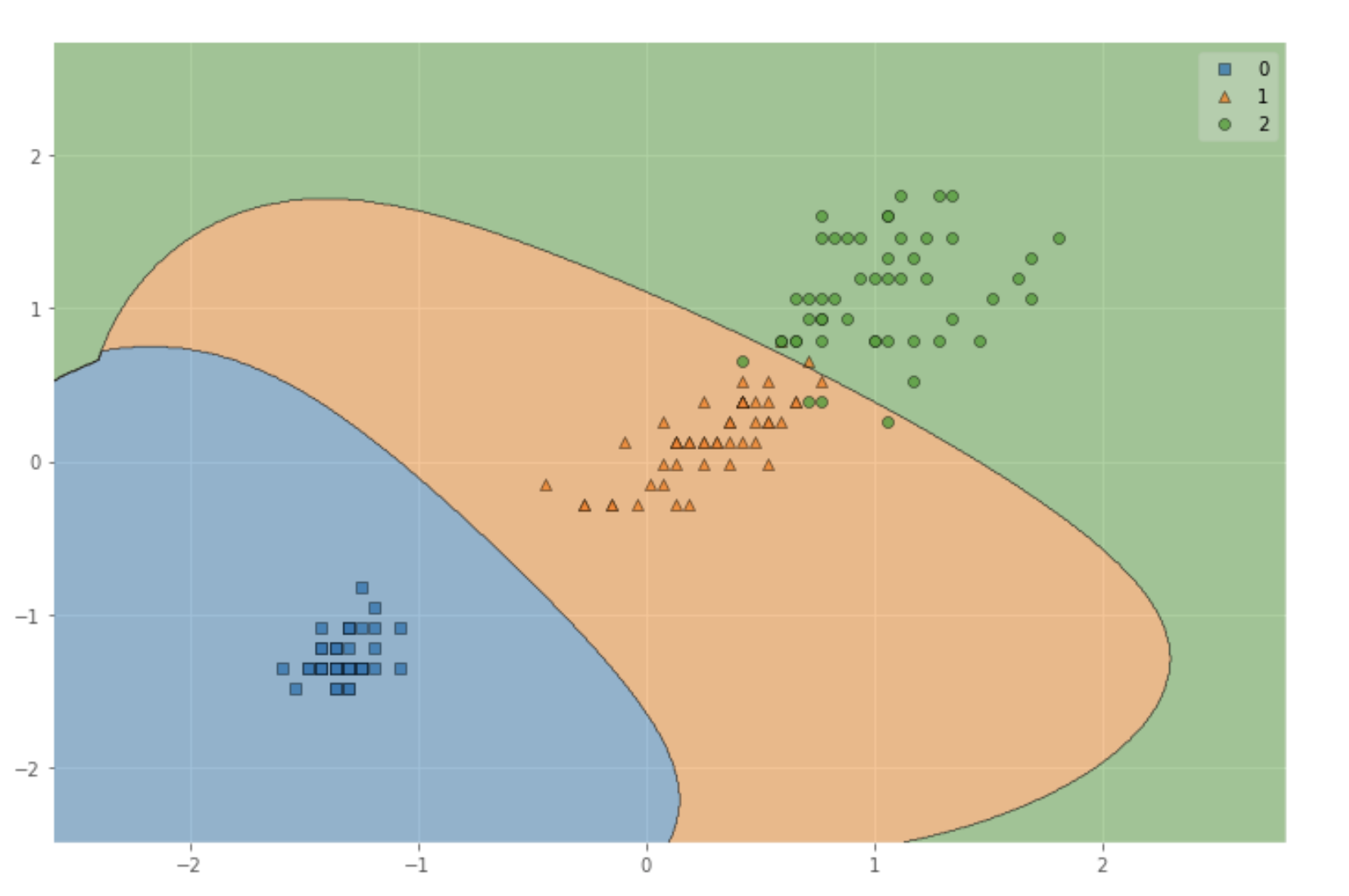
可視化
X_ = np.vstack((X_train_std, X_test_std))
y_ = np.hstack((y_train, y_test))
fig = plt.figure(figsize=(12,6))
plot_decision_regions(X_, y_, clf=model,res=0.02)
train dataとtest dataを結合して表示してます。
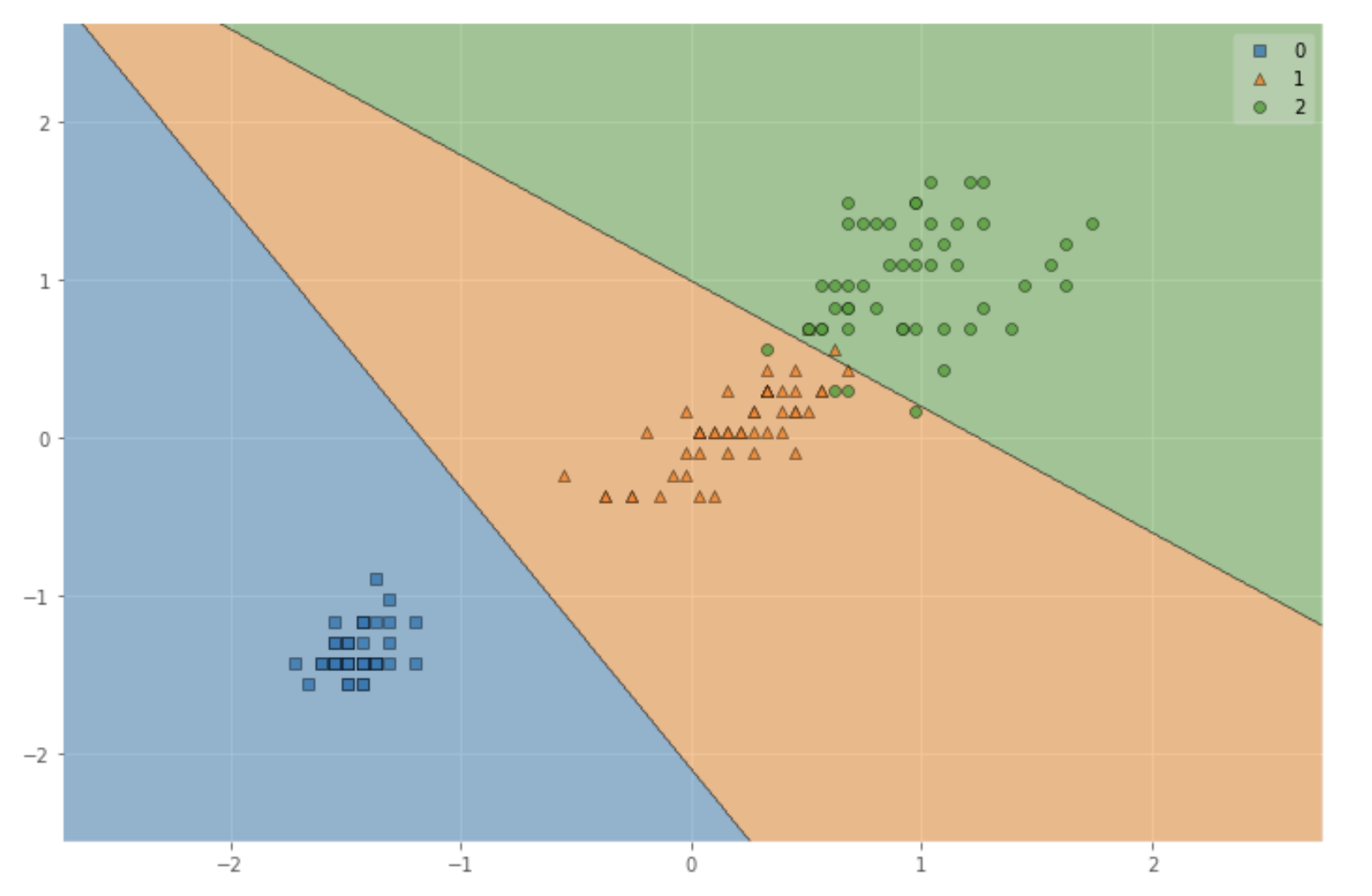
kernelをlinearに変更すると以下のようになります。
8. 参考文献
9. おわりに
KEY: SVMはデータを多次元空間に埋め込み、線形分離する!
SVMについて、自分なりに整理できながら書けたので良かったです。
機械学習素人の記事なんで、指摘があればビシバシお願いします!!
Outputシリーズ今後もできたらなと思っています!